 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Artefact to Insight: Efficient Low-Rank Adaptation of BrushNet for Scanning Probe Microscopy Image Restoration
Mar 16, 2026Scanning Probe Microscopy or SPM offers nanoscale resolution but is frequently marred by structured artefacts such as line scan dropout, gain induced noise, tip convolution, and phase hops. While most available methods treat SPM artefact removal as isolated denoising or interpolation tasks, the generative inpainting perspective remains largely unexplored. In this work, we introduce a diffusion based inpainting framework tailored to scientific grayscale imagery. By fine tuning less than 0.2 percent of BrushNet weights with rank constrained low rank adaptation (LoRA), we adapt a pretrained diffusion model using only 7390 artefact, clean pairs distilled from 739 experimental scans. On our forthcoming public SPM InpBench benchmark, the LoRA enhanced model lifts the Peak Signal to Noise Ratio or PSNR by 6.61 dB and halves the Learned Perceptual Image Patch Similarity or LPIPS relative to zero-shot inference, while matching or slightly surpassing the accuracy of full retraining, trainable on a single GPU instead of four high-memory cards. The approach generalizes across various SPM image channels including height, amplitude and phase, faithfully restores subtle structural details, and suppresses hallucination artefacts inherited from natural image priors. This lightweight framework enables efficient, scalable recovery of irreplaceable SPM images and paves the way for a broader diffusion model adoption in nanoscopic imaging analysis.
H2-MARL: Multi-Agent Reinforcement Learning for Pareto Optimality in Hospital Capacity Strain and Human Mobility during Epidemic
Mar 13, 2025



The necessity of achieving an effective balance between minimizing the losses associated with restricting human mobility and ensuring hospital capacity has gained significant attention in the aftermath of COVID-19. Reinforcement learning (RL)-based strategies for human mobility management have recently advanced in addressing the dynamic evolution of cities and epidemics; however, they still face challenges in achieving coordinated control at the township level and adapting to cities of varying scales. To address the above issues, we propose a multi-agent RL approach that achieves Pareto optimality in managing hospital capacity and human mobility (H2-MARL), applicable across cities of different scales. We first develop a township-level infection model with online-updatable parameters to simulate disease transmission and construct a city-wide dynamic spatiotemporal epidemic simulator. On this basis, H2-MARL is designed to treat each division as an agent, with a trade-off dual-objective reward function formulated and an experience replay buffer enriched with expert knowledge built. To evaluate the effectiveness of the model, we construct a township-level human mobility dataset containing over one billion records from four representative cities of varying scales. Extensive experiments demonstrate that H2-MARL has the optimal dual-objective trade-off capability, which can minimize hospital capacity strain while minimizing human mobility restriction loss. Meanwhile, the applicability of the proposed model to epidemic control in cities of varying scales is verified, which showcases its feasibility and versatility in practical applications.
AtlasSeg: Atlas Prior Guided Dual-U-Net for Cortical Segmentation in Fetal Brain MRI
Nov 05, 2024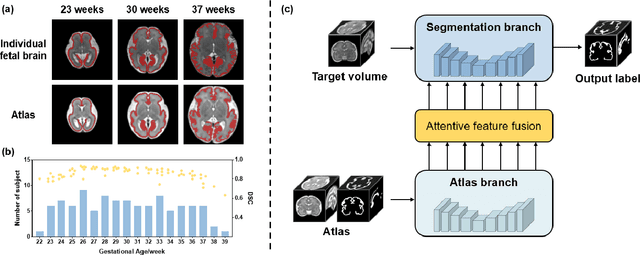
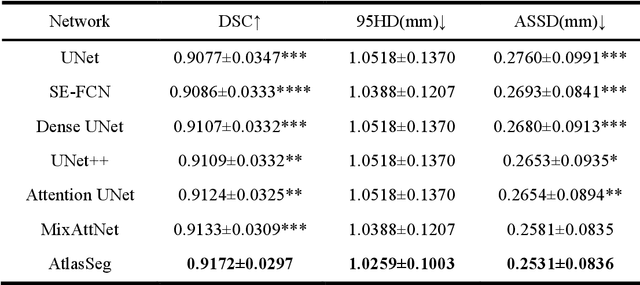
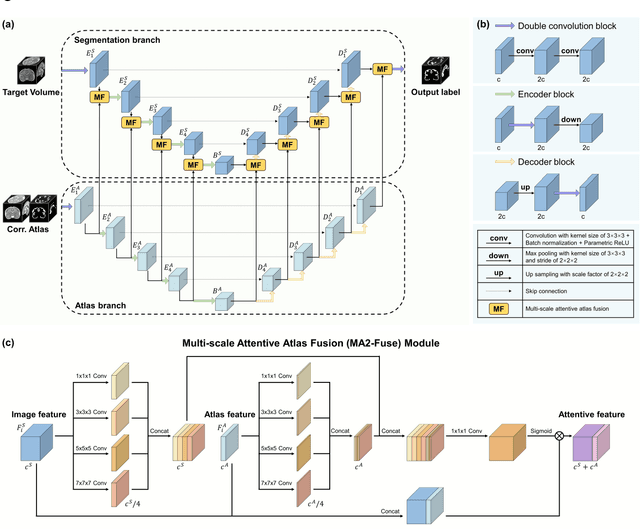

Accurate tissue segmentation in fetal brain MRI remains challenging due to the dynamically changing anatomical anatomy and contrast during fetal development. To enhance segmentation accuracy throughout gestation, we introduced AtlasSeg, a dual-U-shape convolution network incorporating gestational age (GA) specific information as guidance. By providing a publicly available fetal brain atlas with segmentation label at the corresponding GA, AtlasSeg effectively extracted the contextual features of age-specific patterns in atlas branch and generated tissue segmentation in segmentation branch. Multi-scale attentive atlas feature fusions were constructed in all stages during encoding and decoding, giving rise to a dual-U-shape network to assist feature flow and information interactions between two branches. AtlasSeg outperformed six well-known segmentation networks in both our internal fetal brain MRI dataset and the external FeTA dataset. Ablation experiments demonstrate the efficiency of atlas guidance and the attention mechanism. The proposed AtlasSeg demonstrated superior segmentation performance against other convolution networks with higher segmentation accuracy, and may facilitate fetal brain MRI analysis in large-scale fetal brain studies.
Adaptive Prompt Learning with SAM for Few-shot Scanning Probe Microscope Image Segmentation
Oct 16, 2024



The Segment Anything Model (SAM) has demonstrated strong performance in image segmentation of natural scene images. However, its effectiveness diminishes markedly when applied to specific scientific domains, such as Scanning Probe Microscope (SPM) images. This decline in accuracy can be attributed to the distinct data distribution and limited availability of the data inherent in the scientific images. On the other hand, the acquisition of adequate SPM datasets is both time-intensive and laborious as well as skill-dependent. To address these challenges, we propose an Adaptive Prompt Learning with SAM (APL-SAM) framework tailored for few-shot SPM image segmentation. Our approach incorporates two key innovations to enhance SAM: 1) An Adaptive Prompt Learning module leverages few-shot embeddings derived from limited support set to learn adaptively central representatives, serving as visual prompts. This innovation eliminates the need for time-consuming online user interactions for providing prompts, such as exhaustively marking points and bounding boxes slice by slice; 2) A multi-source, multi-level mask decoder specifically designed for few-shot SPM image segmentation is introduced, which can effectively capture the correspondence between the support and query images. To facilitate comprehensive training and evaluation, we introduce a new dataset, SPM-Seg, curated for SPM image segmentation. Extensive experiments on this dataset reveal that the proposed APL-SAM framework significantly outperforms the original SAM, achieving over a 30% improvement in terms of Dice Similarity Coefficient with only one-shot guidance. Moreover, APL-SAM surpasses state-of-the-art few-shot segmentation methods and even fully supervised approaches in performance. Code and dataset used in this study will be made available upon acceptance.
CEC: A Noisy Label Detection Method for Speaker Recognition
Jun 19, 2024



Noisy labels are inevitable, even in well-annotated datasets. The detection of noisy labels is of significant importance to enhance the robustness of speaker recognition models. In this paper, we propose a novel noisy label detection approach based on two new statistical metrics: Continuous Inconsistent Counting (CIC) and Total Inconsistent Counting (TIC). These metrics are calculated through Cross-Epoch Counting (CEC) and correspond to the early and late stages of training, respectively. Additionally, we categorize samples based on their prediction results into three categories: inconsistent samples, hard samples, and easy samples. During training, we gradually increase the difficulty of hard samples to update model parameters, preventing noisy labels from being overfitted. Compared to contrastive schemes, our approach not only achieves the best performance in speaker verification but also excels in noisy label detection.
MECPformer: Multi-estimations Complementary Patch with CNN-Transformers for Weakly Supervised Semantic Segmentation
Mar 19, 2023The initial seed based on the convolutional neural network (CNN) for weakly supervised semantic segmentation always highlights the most discriminative regions but fails to identify the global target information. Methods based on transformers have been proposed successively benefiting from the advantage of capturing long-range feature representations. However, we observe a flaw regardless of the gifts based on the transformer. Given a class, the initial seeds generated based on the transformer may invade regions belonging to other classes. Inspired by the mentioned issues, we devise a simple yet effective method with Multi-estimations Complementary Patch (MECP) strategy and Adaptive Conflict Module (ACM), dubbed MECPformer. Given an image, we manipulate it with the MECP strategy at different epochs, and the network mines and deeply fuses the semantic information at different levels. In addition, ACM adaptively removes conflicting pixels and exploits the network self-training capability to mine potential target information. Without bells and whistles, our MECPformer has reached new state-of-the-art 72.0% mIoU on the PASCAL VOC 2012 and 42.4% on MS COCO 2014 dataset. The code is available at https://github.com/ChunmengLiu1/MECPformer.
Multi-objective Generative Design of Three-Dimensional Composite Materials
Feb 26, 2023



Composite materials with 3D architectures are desirable in a variety of applications for the capability of tailoring their properties to meet multiple functional requirements. By the arrangement of materials' internal components, structure design is of great significance in tuning the properties of the composites. However, most of the composite structures are proposed by empirical designs following existing patterns. Hindered by the complexity of 3D structures, it is hard to extract customized structures with multiple desired properties from large design space. Here we report a multi-objective driven Wasserstein generative adversarial network (MDWGAN) to implement inverse designs of 3D composite structures according to given geometrical, structural and mechanical requirements. Our framework consists a GAN based network which generates 3D composite structures possessing with similar geometrical and structural features to the target dataset. Besides, multiple objectives are introduced to our framework for the control of mechanical property and isotropy of the composites. Real time calculation of the properties in training iterations is achieved by an accurate surrogate model. We constructed a small and concise dataset to illustrate our framework. With multiple objectives combined by their weight, and the 3D-GAN act as a soft constraint, our framework is proved to be capable of tuning the properties of the generated composites in multiple aspects, while keeping the selected features of different kinds of structures. The feasibility on small dataset and potential scalability on objectives of other properties make our work a novel, effective approach to provide fast, experience free composite structure designs for various functional materials.
Precise Single-stage Detector
Oct 09, 2022
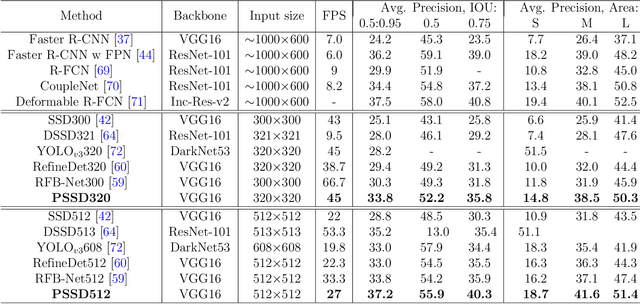
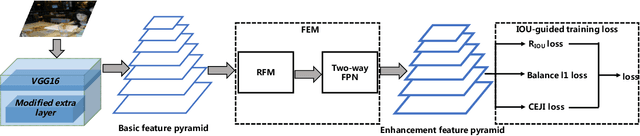

There are still two problems in SDD causing some inaccurate results: (1) In the process of feature extraction, with the layer-by-layer acquisition of semantic information, local information is gradually lost, resulting into less representative feature maps; (2) During the Non-Maximum Suppression (NMS) algorithm due to inconsistency in classification and regression tasks, the classification confidence and predicted detection position cannot accurately indicate the position of the prediction boxes. Methods: In order to address these aforementioned issues, we propose a new architecture, a modified version of Single Shot Multibox Detector (SSD), named Precise Single Stage Detector (PSSD). Firstly, we improve the features by adding extra layers to SSD. Secondly, we construct a simple and effective feature enhancement module to expand the receptive field step by step for each layer and enhance its local and semantic information. Finally, we design a more efficient loss function to predict the IOU between the prediction boxes and ground truth boxes, and the threshold IOU guides classification training and attenuates the scores, which are used by the NMS algorithm. Main Results: Benefiting from the above optimization, the proposed model PSSD achieves exciting performance in real-time. Specifically, with the hardware of Titan Xp and the input size of 320 pix, PSSD achieves 33.8 mAP at 45 FPS speed on MS COCO benchmark and 81.28 mAP at 66 FPS speed on Pascal VOC 2007 outperforming state-of-the-art object detection models. Besides, the proposed model performs significantly well with larger input size. Under 512 pix, PSSD can obtain 37.2 mAP with 27 FPS on MS COCO and 82.82 mAP with 40 FPS on Pascal VOC 2007. The experiment results prove that the proposed model has a better trade-off between speed and accuracy.
Light in the Larynx: a Miniaturized Robotic Optical Fiber for In-office Laser Surgery of the Vocal Folds
Apr 27, 2022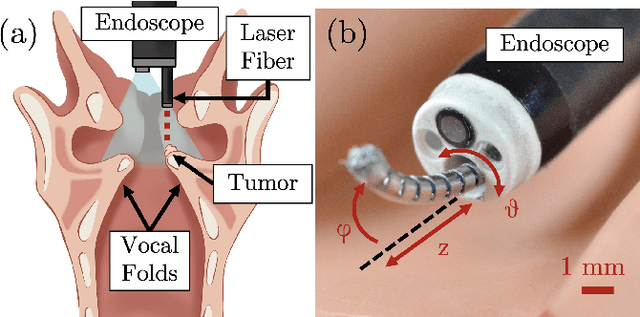
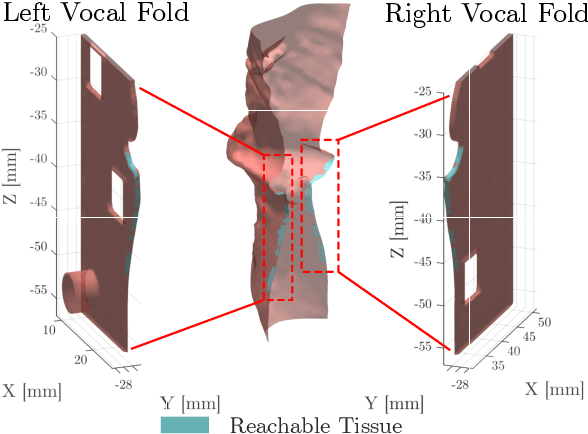
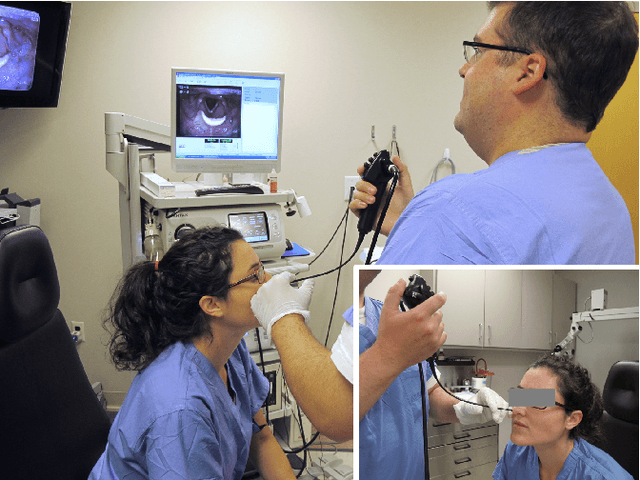

This letter reports the design, construction, and experimental validation of a novel hand-held robot for in-office laser surgery of the vocal folds. In-office endoscopic laser surgery is an emerging trend in Laryngology: It promises to deliver the same patient outcomes of traditional surgical treatment (i.e., in the operating room), at a fraction of the cost. Unfortunately, office procedures can be challenging to perform; the optical fibers used for laser delivery can only emit light forward in a line-of-sight fashion, which severely limits anatomical access. The robot we present in this letter aims to overcome these challenges. The end effector of the robot is a steerable laser fiber, created through the combination of a thin optical fiber (0.225 mm) with a tendon-actuated Nickel-Titanium notched sheath that provides bending. This device can be seamlessly used with most commercially available endoscopes, as it is sufficiently small (1.1 mm) to pass through a working channel. To control the fiber, we propose a compact actuation unit that can be mounted on top of the endoscope handle, so that, during a procedure, the operating physician can operate both the endoscope and the steerable fiber with a single hand. We report simulation and phantom experiments demonstrating that the proposed device substantially enhances surgical access compared to current clinical fibers.
GMAIR: Unsupervised Object Detection Based on Spatial Attention and Gaussian Mixture
Jun 03, 2021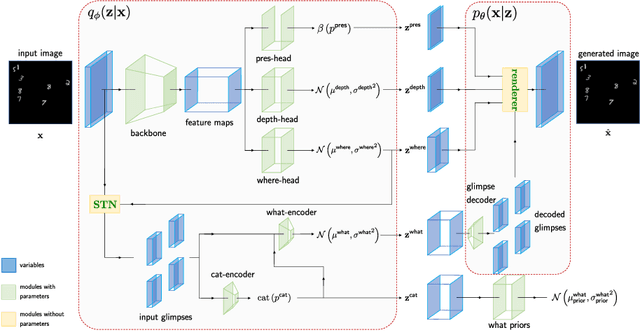


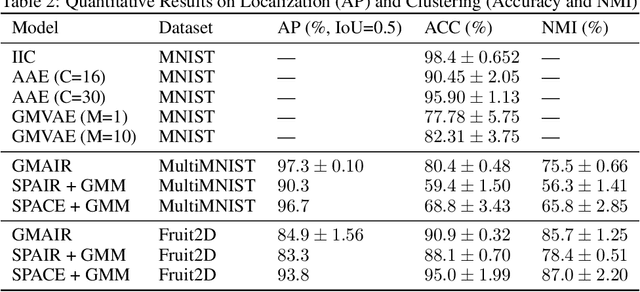
Recent studies on unsupervised object detection based on spatial attention have achieved promising results. Models, such as AIR and SPAIR, output "what" and "where" latent variables that represent the attributes and locations of objects in a scene, respectively. Most of the previous studies concentrate on the "where" localization performance; however, we claim that acquiring "what" object attributes is also essential for representation learning. This paper presents a framework, GMAIR, for unsupervised object detection. It incorporates spatial attention and a Gaussian mixture in a unified deep generative model. GMAIR can locate objects in a scene and simultaneously cluster them without supervision. Furthermore, we analyze the "what" latent variables and clustering process. Finally, we evaluate our model on MultiMNIST and Fruit2D datasets and show that GMAIR achieves competitive results on localization and clustering compared to state-of-the-art methods.