 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinking as Compression: Your Reasoning Model is Secretly a Context Compressor
May 27, 2026Context compression aims to shorten long context inputs with minimal information loss for LLM inference acceleration. While existing methods have shown promise, they typically rely on complex compression modules or compression-specific training, leaving the intrinsic capabilities of LLMs underexplored. In contrast, this work reveals that a thinking model itself can naturally compress long contexts by organizing task-relevant information. We thus derive Thinking as Compression (TaC), a new compression paradigm that treats thinking itself as compressed context. Without relying on specific dedicated compressor, TaC directly prompts the thinking model to generate thinking traces as the shortened context, already outperforming most representative compression methods. Further, given that raw thinking output may struggle with budget control and shortcut behaviors, we introduce Thinking as Compression Constrained (TaC-C), leveraging a simple reward-driven optimization framework to elicit intrinsic thinking as compact and controllable compressed context. Experiments across four long-context QA benchmarks demonstrate that TaC-C consistently outperforms existing baselines. At 4x and 8x compression ratios, it surpasses the strongest competitor by 17.4% and 23.4% in average F1, and by 15.7% and 21.7% in average Exact Match Score (EM), respectively.
ReflectRM: Boosting Generative Reward Models via Self-Reflection within a Unified Judgment Framework
Apr 08, 2026Reward Models (RMs) are critical components in the Reinforcement Learning from Human Feedback (RLHF) pipeline, directly determining the alignment quality of Large Language Models (LLMs). Recently, Generative Reward Models (GRMs) have emerged as a superior paradigm, offering higher interpretability and stronger generalization than traditional scalar RMs. However, existing methods for GRMs focus primarily on outcome-level supervision, neglecting analytical process quality, which constrains their potential. To address this, we propose ReflectRM, a novel GRM that leverages self-reflection to assess analytical quality and enhance preference modeling. ReflectRM is trained under a unified generative framework for joint modeling of response preference and analysis preference. During inference, we use its self-reflection capability to identify the most reliable analysis, from which the final preference prediction is derived. Experiments across four benchmarks show that ReflectRM consistently improves performance, achieving an average accuracy gain of +3.7 on Qwen3-4B. Further experiments confirm that response preference and analysis preference are mutually reinforcing. Notably, ReflectRM substantially mitigates positional bias, yielding +10.2 improvement compared with leading GRMs and establishing itself as a more stable evaluator.
ConsistRM: Improving Generative Reward Models via Consistency-Aware Self-Training
Apr 08, 2026Generative reward models (GRMs) have emerged as a promising approach for aligning Large Language Models (LLMs) with human preferences by offering greater representational capacity and flexibility than traditional scalar reward models. However, GRMs face two major challenges: reliance on costly human-annotated data restricts scalability, and self-training approaches often suffer from instability and vulnerability to reward hacking. To address these issues, we propose ConsistRM, a self-training framework that enables effective and stable GRM training without human annotations. ConsistRM incorporates the Consistency-Aware Answer Reward, which produces reliable pseudo-labels with temporal consistency, thereby providing more stable model optimization. Moreover, the Consistency-Aware Critique Reward is introduced to assess semantic consistency across multiple critiques and allocates fine-grained and differentiated rewards. Experiments on five benchmark datasets across four base models demonstrate that ConsistRM outperforms vanilla Reinforcement Fine-Tuning (RFT) by an average of 1.5%. Further analysis shows that ConsistRM enhances output consistency and mitigates position bias caused by input order, highlighting the effectiveness of consistency-aware rewards in improving GRMs.
When Less is More: The LLM Scaling Paradox in Context Compression
Feb 10, 2026Scaling up model parameters has long been a prevalent training paradigm driven by the assumption that larger models yield superior generation capabilities. However, under lossy context compression in a compressor-decoder setup, we observe a Size-Fidelity Paradox: increasing the compressor size can lessen the faithfulness of reconstructed contexts though training loss decreases. Through extensive experiments across models from 0.6B to 90B, we coin this paradox arising from two dominant factors: 1) knowledge overwriting: larger models increasingly replace source facts with their own prior beliefs, e.g., ``the white strawberry'' $\to$ ``the red strawberry''; and 2) semantic drift: larger models tend to paraphrase or restructure content instead of reproducing it verbatim, e.g., ``Alice hit Bob'' $\to$ ``Bob hit Alice''. By holding model size fixed, we reflect on the emergent properties of compressed context representations. We show that the culprit is not parameter count itself, but the excessive semantic capacity and amplified generative uncertainty that accompany scaling. Specifically, the increased rank of context embeddings facilitates prior knowledge intrusion, whereas higher entropy over token prediction distributions promotes rewriting. Our results complement existing evaluations over context compression paradigm, underpinning a breakdown in scaling laws for faithful preservation in open-ended generation.
TRE: Encouraging Exploration in the Trust Region
Feb 03, 2026Entropy regularization is a standard technique in reinforcement learning (RL) to enhance exploration, yet it yields negligible effects or even degrades performance in Large Language Models (LLMs). We attribute this failure to the cumulative tail risk inherent to LLMs with massive vocabularies and long generation horizons. In such environments, standard global entropy maximization indiscriminately dilutes probability mass into the vast tail of invalid tokens rather than focusing on plausible candidates, thereby disrupting coherent reasoning. To address this, we propose Trust Region Entropy (TRE), a method that encourages exploration strictly within the model's trust region. Extensive experiments across mathematical reasoning (MATH), combinatorial search (Countdown), and preference alignment (HH) tasks demonstrate that TRE consistently outperforms vanilla PPO, standard entropy regularization, and other exploration baselines. Our code is available at https://github.com/WhyChaos/TRE-Encouraging-Exploration-in-the-Trust-Region.
Advancing General-Purpose Reasoning Models with Modular Gradient Surgery
Feb 02, 2026Reinforcement learning (RL) has played a central role in recent advances in large reasoning models (LRMs), yielding strong gains in verifiable and open-ended reasoning. However, training a single general-purpose LRM across diverse domains remains challenging due to pronounced domain heterogeneity. Through a systematic study of two widely used strategies, Sequential RL and Mixed RL, we find that both incur substantial cross-domain interference at the behavioral and gradient levels, resulting in limited overall gains. To address these challenges, we introduce **M**odular **G**radient **S**urgery (**MGS**), which resolves gradient conflicts at the module level within the transformer. When applied to Llama and Qwen models, MGS achieves average improvements of 4.3 (16.6\%) and 4.5 (11.1\%) points, respectively, over standard multi-task RL across three representative domains (math, general chat, and instruction following). Further analysis demonstrates that MGS remains effective under prolonged training. Overall, our study clarifies the sources of interference in multi-domain RL and presents an effective solution for training general-purpose LRMs.
H2-MARL: Multi-Agent Reinforcement Learning for Pareto Optimality in Hospital Capacity Strain and Human Mobility during Epidemic
Mar 13, 2025



The necessity of achieving an effective balance between minimizing the losses associated with restricting human mobility and ensuring hospital capacity has gained significant attention in the aftermath of COVID-19. Reinforcement learning (RL)-based strategies for human mobility management have recently advanced in addressing the dynamic evolution of cities and epidemics; however, they still face challenges in achieving coordinated control at the township level and adapting to cities of varying scales. To address the above issues, we propose a multi-agent RL approach that achieves Pareto optimality in managing hospital capacity and human mobility (H2-MARL), applicable across cities of different scales. We first develop a township-level infection model with online-updatable parameters to simulate disease transmission and construct a city-wide dynamic spatiotemporal epidemic simulator. On this basis, H2-MARL is designed to treat each division as an agent, with a trade-off dual-objective reward function formulated and an experience replay buffer enriched with expert knowledge built. To evaluate the effectiveness of the model, we construct a township-level human mobility dataset containing over one billion records from four representative cities of varying scales. Extensive experiments demonstrate that H2-MARL has the optimal dual-objective trade-off capability, which can minimize hospital capacity strain while minimizing human mobility restriction loss. Meanwhile, the applicability of the proposed model to epidemic control in cities of varying scales is verified, which showcases its feasibility and versatility in practical applications.
Enhancing Agent Learning through World Dynamics Modeling
Jul 25, 2024
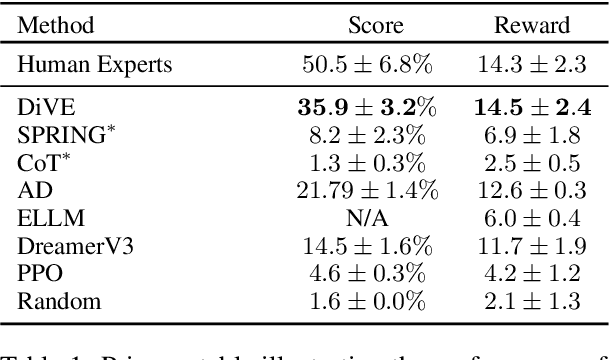
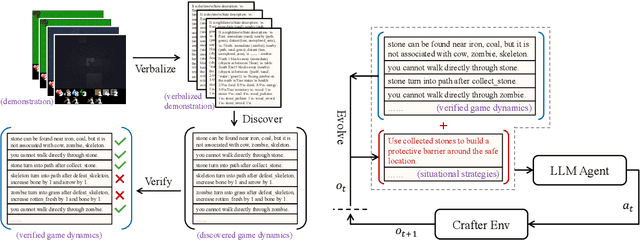
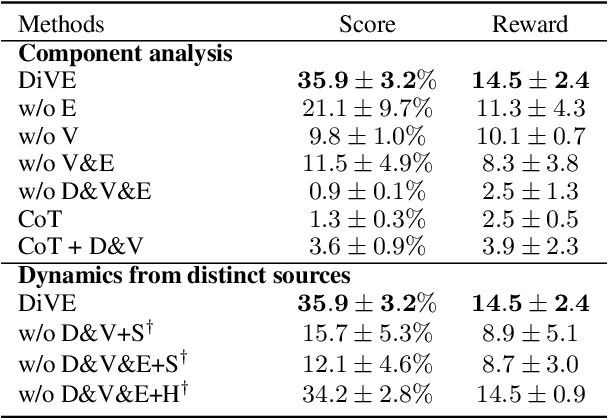
While large language models (LLMs) have been increasingly deployed across tasks in language understanding and interactive decision-making, their impressive performance is largely due to the comprehensive and in-depth domain knowledge embedded within them. However, the extent of this knowledge can vary across different domains. Existing methods often assume that LLMs already possess such comprehensive and in-depth knowledge of their environment, overlooking potential gaps in their understanding of actual world dynamics. To address this gap, we introduce Discover, Verify, and Evolve (DiVE), a framework that discovers world dynamics from a small number of demonstrations, verifies the correctness of these dynamics, and evolves new, advanced dynamics tailored to the current situation. Through extensive evaluations, we analyze the impact of each component on performance and compare the automatically generated dynamics from DiVE with human-annotated world dynamics. Our results demonstrate that LLMs guided by DiVE can make better decisions, achieving rewards comparable to human players in the Crafter environment.
OPEx: A Component-Wise Analysis of LLM-Centric Agents in Embodied Instruction Following
Mar 05, 2024



Embodied Instruction Following (EIF) is a crucial task in embodied learning, requiring agents to interact with their environment through egocentric observations to fulfill natural language instructions. Recent advancements have seen a surge in employing large language models (LLMs) within a framework-centric approach to enhance performance in embodied learning tasks, including EIF. Despite these efforts, there exists a lack of a unified understanding regarding the impact of various components-ranging from visual perception to action execution-on task performance. To address this gap, we introduce OPEx, a comprehensive framework that delineates the core components essential for solving embodied learning tasks: Observer, Planner, and Executor. Through extensive evaluations, we provide a deep analysis of how each component influences EIF task performance. Furthermore, we innovate within this space by deploying a multi-agent dialogue strategy on a TextWorld counterpart, further enhancing task performance. Our findings reveal that LLM-centric design markedly improves EIF outcomes, identify visual perception and low-level action execution as critical bottlenecks, and demonstrate that augmenting LLMs with a multi-agent framework further elevates performance.
Deciphering Digital Detectives: Understanding LLM Behaviors and Capabilities in Multi-Agent Mystery Games
Dec 01, 2023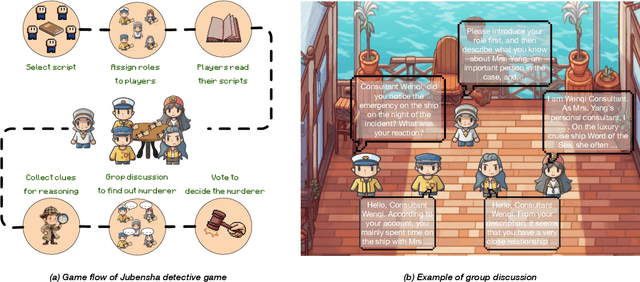

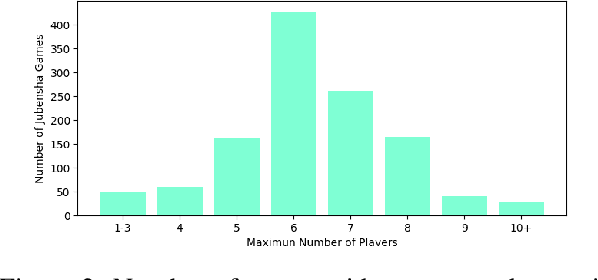

In this study, we explore the application of Large Language Models (LLMs) in "Jubensha" (Chinese murder mystery role-playing games), a novel area in AI-driven gaming. We introduce the first Chinese dataset specifically for Jubensha, including character scripts and game rules, to foster AI agent development in this complex narrative environment. Our work also presents a unique multi-agent interaction framework using LLMs, allowing AI agents to autonomously engage in the game, enhancing the dynamics of Jubensha gameplay. To evaluate these AI agents, we developed specialized methods targeting their mastery of case information and reasoning skills. Furthermore, we incorporated the latest advancements in in-context learning to improve the agents' performance in critical aspects like information gathering, murderer detection, and logical reasoning. The experimental results validate the effectiveness of our proposed methods. This work aims to offer a fresh perspective on understanding LLM capabilities and establish a new benchmark for evaluating large language model-based agents to researchers in the field.