 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndoorWorld: Integrating Physical Task Solving and Social Simulation in A Heterogeneous Multi-Agent Environment
Jun 14, 2025Virtual environments are essential to AI agent research. Existing environments for LLM agent research typically focus on either physical task solving or social simulation, with the former oversimplifying agent individuality and social dynamics, and the latter lacking physical grounding of social behaviors. We introduce IndoorWorld, a heterogeneous multi-agent environment that tightly integrates physical and social dynamics. By introducing novel challenges for LLM-driven agents in orchestrating social dynamics to influence physical environments and anchoring social interactions within world states, IndoorWorld opens up possibilities of LLM-based building occupant simulation for architectural design. We demonstrate the potential with a series of experiments within an office setting to examine the impact of multi-agent collaboration, resource competition, and spatial layout on agent behavior.
Advances and Challenges in Foundation Agents: From Brain-Inspired Intelligence to Evolutionary, Collaborative, and Safe Systems
Mar 31, 2025The advent of large language models (LLMs) has catalyzed a transformative shift in artificial intelligence, paving the way for advanced intelligent agents capable of sophisticated reasoning, robust perception, and versatile action across diverse domains. As these agents increasingly drive AI research and practical applications, their design, evaluation, and continuous improvement present intricate, multifaceted challenges. This survey provides a comprehensive overview, framing intelligent agents within a modular, brain-inspired architecture that integrates principles from cognitive science, neuroscience, and computational research. We structure our exploration into four interconnected parts. First, we delve into the modular foundation of intelligent agents, systematically mapping their cognitive, perceptual, and operational modules onto analogous human brain functionalities, and elucidating core components such as memory, world modeling, reward processing, and emotion-like systems. Second, we discuss self-enhancement and adaptive evolution mechanisms, exploring how agents autonomously refine their capabilities, adapt to dynamic environments, and achieve continual learning through automated optimization paradigms, including emerging AutoML and LLM-driven optimization strategies. Third, we examine collaborative and evolutionary multi-agent systems, investigating the collective intelligence emerging from agent interactions, cooperation, and societal structures, highlighting parallels to human social dynamics. Finally, we address the critical imperative of building safe, secure, and beneficial AI systems, emphasizing intrinsic and extrinsic security threats, ethical alignment, robustness, and practical mitigation strategies necessary for trustworthy real-world deployment.
Deciphering Digital Detectives: Understanding LLM Behaviors and Capabilities in Multi-Agent Mystery Games
Dec 01, 2023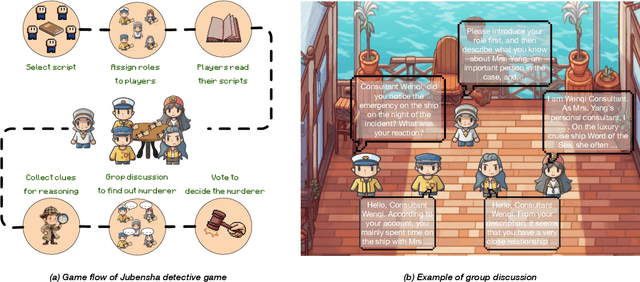

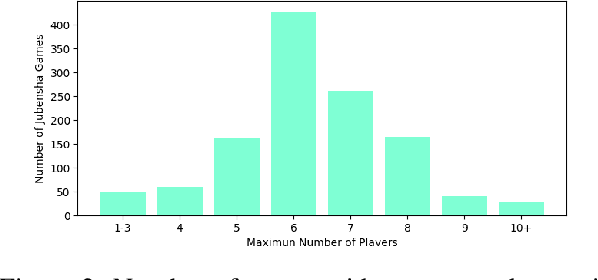

In this study, we explore the application of Large Language Models (LLMs) in "Jubensha" (Chinese murder mystery role-playing games), a novel area in AI-driven gaming. We introduce the first Chinese dataset specifically for Jubensha, including character scripts and game rules, to foster AI agent development in this complex narrative environment. Our work also presents a unique multi-agent interaction framework using LLMs, allowing AI agents to autonomously engage in the game, enhancing the dynamics of Jubensha gameplay. To evaluate these AI agents, we developed specialized methods targeting their mastery of case information and reasoning skills. Furthermore, we incorporated the latest advancements in in-context learning to improve the agents' performance in critical aspects like information gathering, murderer detection, and logical reasoning. The experimental results validate the effectiveness of our proposed methods. This work aims to offer a fresh perspective on understanding LLM capabilities and establish a new benchmark for evaluating large language model-based agents to researchers in the field.
Sports Video Analysis on Large-Scale Data
Aug 09, 2022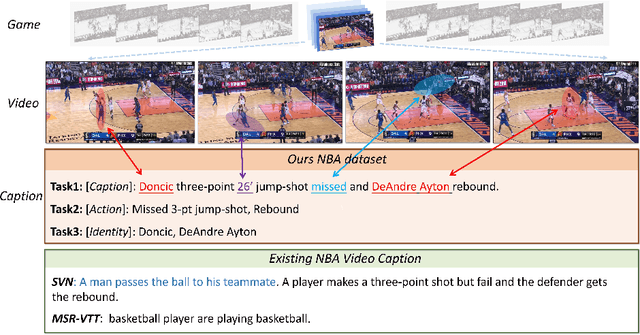


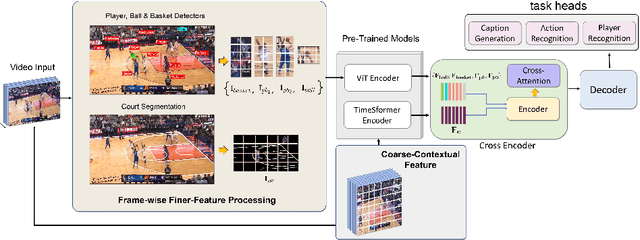
This paper investigates the modeling of automated machine description on sports video, which has seen much progress recently. Nevertheless, state-of-the-art approaches fall quite short of capturing how human experts analyze sports scenes. There are several major reasons: (1) The used dataset is collected from non-official providers, which naturally creates a gap between models trained on those datasets and real-world applications; (2) previously proposed methods require extensive annotation efforts (i.e., player and ball segmentation at pixel level) on localizing useful visual features to yield acceptable results; (3) very few public datasets are available. In this paper, we propose a novel large-scale NBA dataset for Sports Video Analysis (NSVA) with a focus on captioning, to address the above challenges. We also design a unified approach to process raw videos into a stack of meaningful features with minimum labelling efforts, showing that cross modeling on such features using a transformer architecture leads to strong performance. In addition, we demonstrate the broad application of NSVA by addressing two additional tasks, namely fine-grained sports action recognition and salient player identification. Code and dataset are available at https://github.com/jackwu502/NSVA.
Knowledge Graph Empowered Entity Description Generation
Apr 30, 2020
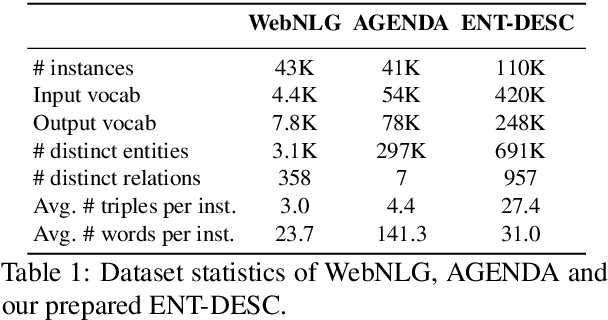

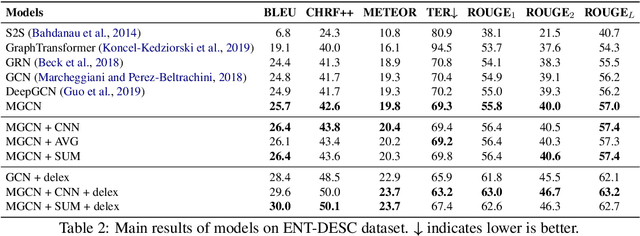
Existing works on KG-to-text generation take as input a few RDF triples or key-value pairs conveying the knowledge of some entities to generate a natural language description. Existing datasets, such as WikiBIO, WebNLG, and E2E, basically have a good alignment between an input triple/pair set and its output text. However in practice, the input knowledge could be more than enough, because the output description may only want to cover the most significant knowledge. In this paper, we introduce a large-scale and challenging dataset to facilitate the study of such practical scenario in KG-to-text. Our dataset involves exploring large knowledge graphs (KG) to retrieve abundant knowledge of various types of main entities, which makes the current graph-to-sequence models severely suffered from the problems of information loss and parameter explosion while generating the description text. We address these challenges by proposing a multi-graph structure that is able to represent the original graph information more comprehensively. Furthermore, we also incorporate aggregation methods that learn to ensemble the rich graph information. Extensive experiments demonstrate the effectiveness of our model architecture.
Scene Classification in Indoor Environments for Robots using Context Based Word Embeddings
Aug 18, 2019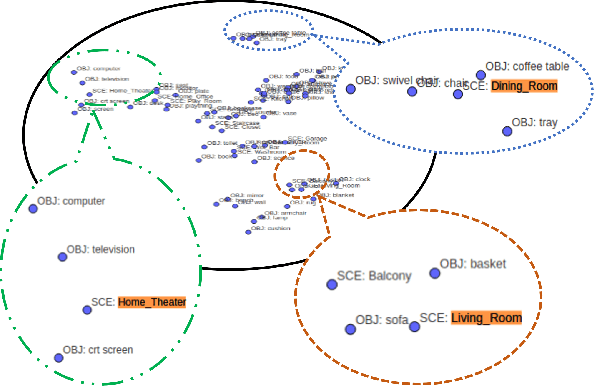

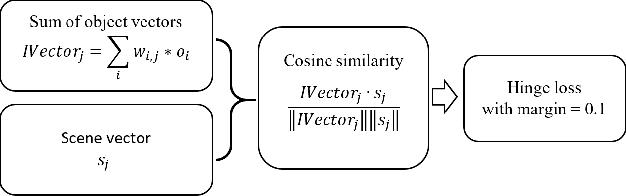

Scene Classification has been addressed with numerous techniques in computer vision literature. However, with the increasing number of scene classes in datasets in the field, it has become difficult to achieve high accuracy in the context of robotics. In this paper, we implement an approach which combines traditional deep learning techniques with natural language processing methods to generate a word embedding based Scene Classification algorithm. We use the key idea that context (objects in the scene) of an image should be representative of the scene label meaning a group of objects could assist to predict the scene class. Objects present in the scene are represented by vectors and the images are re-classified based on the objects present in the scene to refine the initial classification by a Convolutional Neural Network (CNN). In our approach we address indoor Scene Classification task using a model trained with a reduced pre-processed version of the Places365 dataset and an empirical analysis is done on a real-world dataset that we built by capturing image sequences using a GoPro camera. We also report results obtained on a subset of the Places365 dataset using our approach and additionally show a deployment of our approach on a robot operating in a real-world environment.
A General FOFE-net Framework for Simple and Effective Question Answering over Knowledge Bases
Mar 29, 2019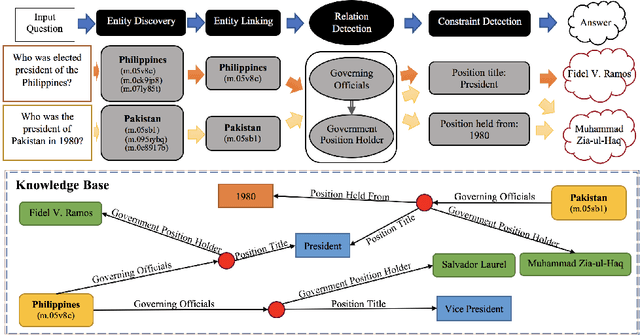
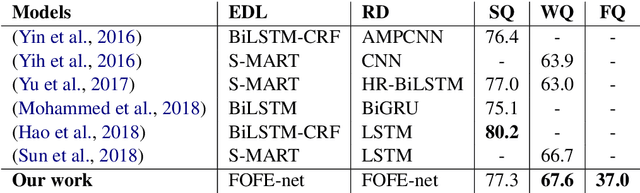
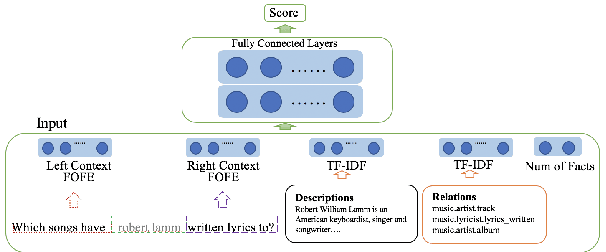

Question answering over knowledge base (KB-QA) has recently become a popular research topic in NLP. One popular way to solve the KB-QA problem is to make use of a pipeline of several NLP modules, including entity discovery and linking (EDL) and relation detection. Recent success on KB-QA task usually involves complex network structures with sophisticated heuristics. Inspired by a previous work that builds a strong KB-QA baseline, we propose a simple but general neural model composed of fixed-size ordinally forgetting encoding (FOFE) and deep neural networks, called FOFE-net to solve KB-QA problem at different stages. For evaluation, we use two popular KB-QA datasets, SimpleQuestions and WebQSP, and a newly created dataset, FreebaseQA. The experimental results show that FOFE-net performs well on KB-QA subtasks, entity discovery and linking (EDL) and relation detection, and in turn pushing overall KB-QA system to achieve strong results on all datasets.