 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSports Video Analysis on Large-Scale Data
Aug 09, 2022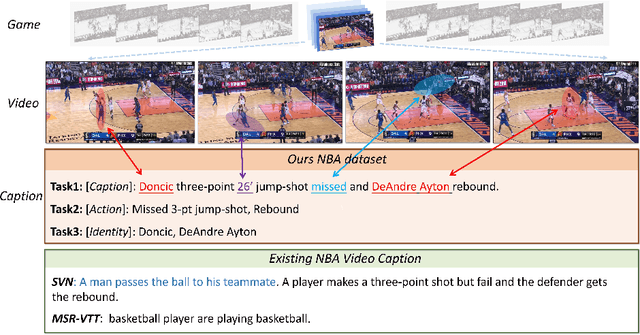


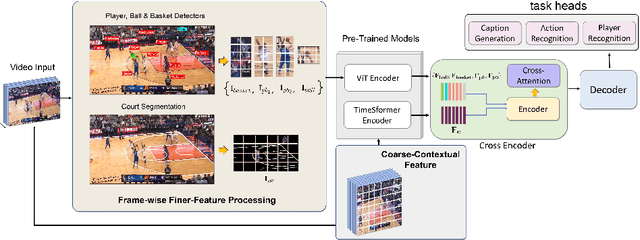
This paper investigates the modeling of automated machine description on sports video, which has seen much progress recently. Nevertheless, state-of-the-art approaches fall quite short of capturing how human experts analyze sports scenes. There are several major reasons: (1) The used dataset is collected from non-official providers, which naturally creates a gap between models trained on those datasets and real-world applications; (2) previously proposed methods require extensive annotation efforts (i.e., player and ball segmentation at pixel level) on localizing useful visual features to yield acceptable results; (3) very few public datasets are available. In this paper, we propose a novel large-scale NBA dataset for Sports Video Analysis (NSVA) with a focus on captioning, to address the above challenges. We also design a unified approach to process raw videos into a stack of meaningful features with minimum labelling efforts, showing that cross modeling on such features using a transformer architecture leads to strong performance. In addition, we demonstrate the broad application of NSVA by addressing two additional tasks, namely fine-grained sports action recognition and salient player identification. Code and dataset are available at https://github.com/jackwu502/NSVA.