 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElastic Bulk Synchronous Parallel Model for Distributed Deep Learning
Jan 06, 2020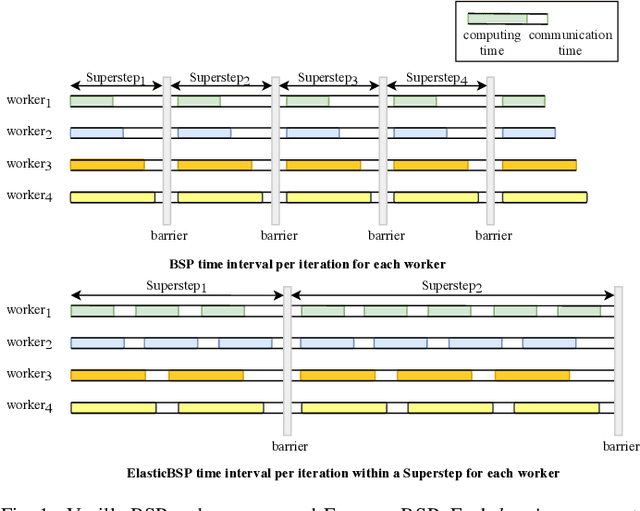
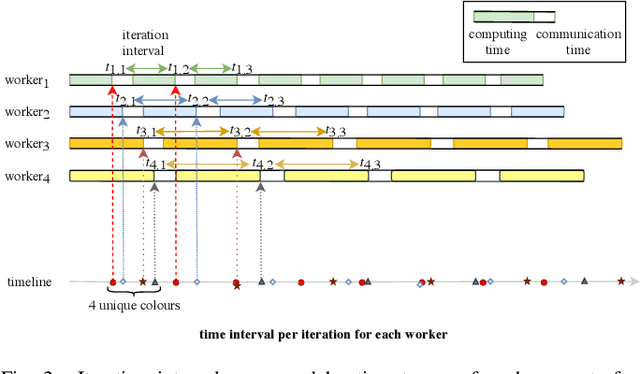
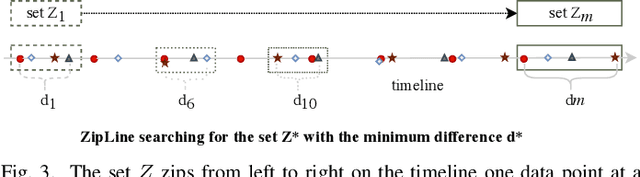
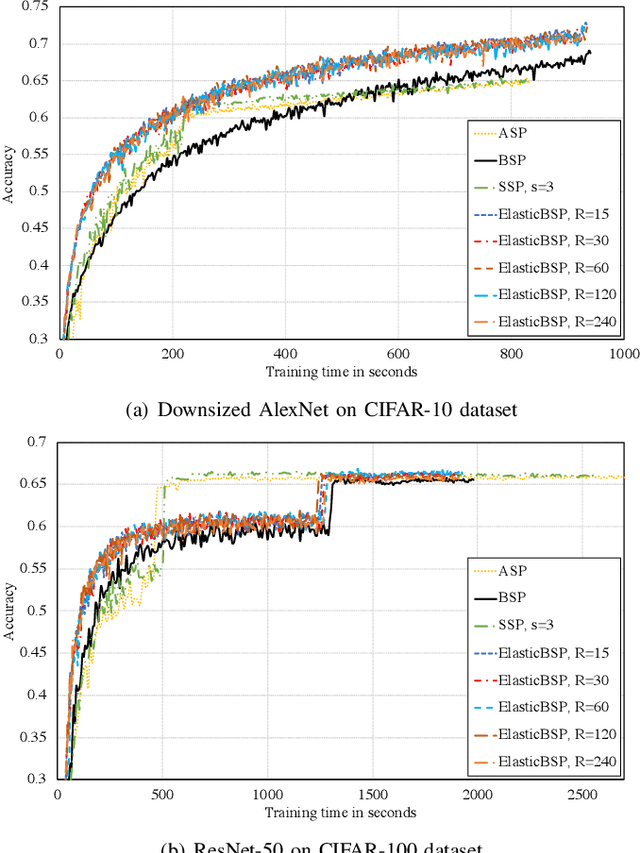
The bulk synchronous parallel (BSP) is a celebrated synchronization model for general-purpose parallel computing that has successfully been employed for distributed training of machine learning models. A prevalent shortcoming of the BSP is that it requires workers to wait for the straggler at every iteration. To ameliorate this shortcoming of classic BSP, we propose ELASTICBSP a model that aims to relax its strict synchronization requirement. The proposed model offers more flexibility and adaptability during the training phase, without sacrificing on the accuracy of the trained model. We also propose an efficient method that materializes the model, named ZIPLINE. The algorithm is tunable and can effectively balance the trade-off between quality of convergence and iteration throughput, in order to accommodate different environments or applications. A thorough experimental evaluation demonstrates that our proposed ELASTICBSP model converges faster and to a higher accuracy than the classic BSP. It also achieves comparable (if not higher) accuracy than the other sensible synchronization models.
* The paper was accepted in the proceedings of the IEEE International Conference on Data Mining 2019 (ICDM'19), 1504-1509
Fast Visual Object Tracking with Rotated Bounding Boxes
Sep 02, 2019

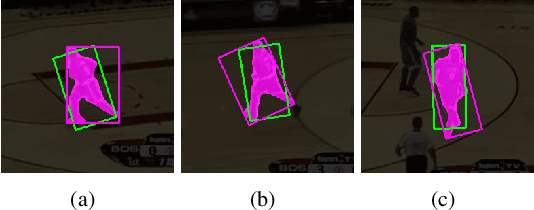

In this paper, we demonstrate a novel algorithm that uses ellipse fitting to estimate the bounding box rotation angle and size with the segmentation(mask) on the target for online and real-time visual object tracking. Our method, SiamMask_E, improves the bounding box fitting procedure of the state-of-the-art object tracking algorithm SiamMask and still retains a fast-tracking frame rate (80 fps) on a system equipped with GPU (GeForce GTX 1080 Ti or higher). We tested our approach on the visual object tracking datasets (VOT2016, VOT2018, and VOT2019) that were labeled with rotated bounding boxes. By comparing with the original SiamMask, we achieved an improved Accuracy of 0.645 and 0.303 EAO on VOT2019, which is 0.049 and 0.02 higher than the original SiamMask. The implementation is available on GitHub: https://github.com/baoxinchen/siammask_e.
Scene Classification in Indoor Environments for Robots using Context Based Word Embeddings
Aug 18, 2019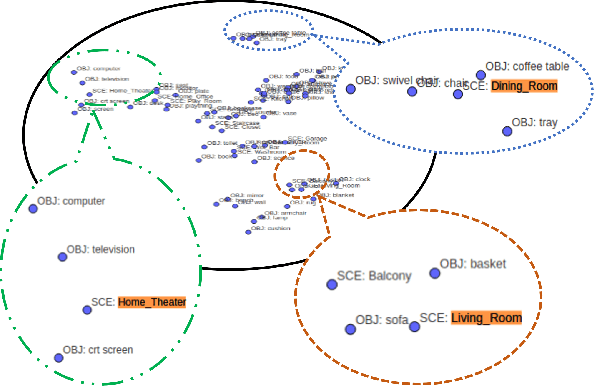

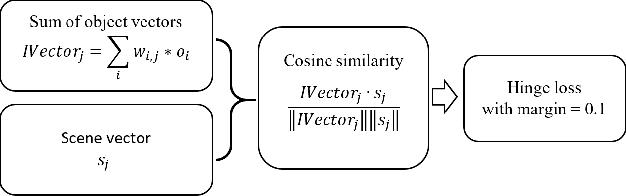

Scene Classification has been addressed with numerous techniques in computer vision literature. However, with the increasing number of scene classes in datasets in the field, it has become difficult to achieve high accuracy in the context of robotics. In this paper, we implement an approach which combines traditional deep learning techniques with natural language processing methods to generate a word embedding based Scene Classification algorithm. We use the key idea that context (objects in the scene) of an image should be representative of the scene label meaning a group of objects could assist to predict the scene class. Objects present in the scene are represented by vectors and the images are re-classified based on the objects present in the scene to refine the initial classification by a Convolutional Neural Network (CNN). In our approach we address indoor Scene Classification task using a model trained with a reduced pre-processed version of the Places365 dataset and an empirical analysis is done on a real-world dataset that we built by capturing image sequences using a GoPro camera. We also report results obtained on a subset of the Places365 dataset using our approach and additionally show a deployment of our approach on a robot operating in a real-world environment.
Dynamic Stale Synchronous Parallel Distributed Training for Deep Learning
Aug 16, 2019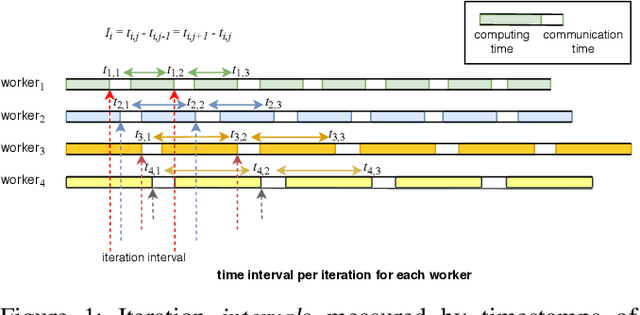
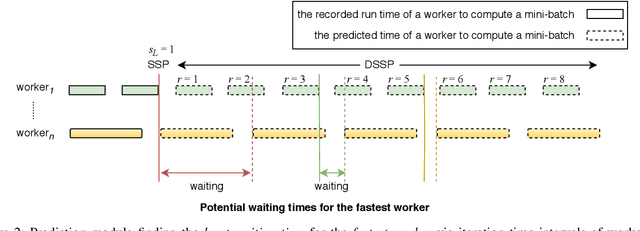
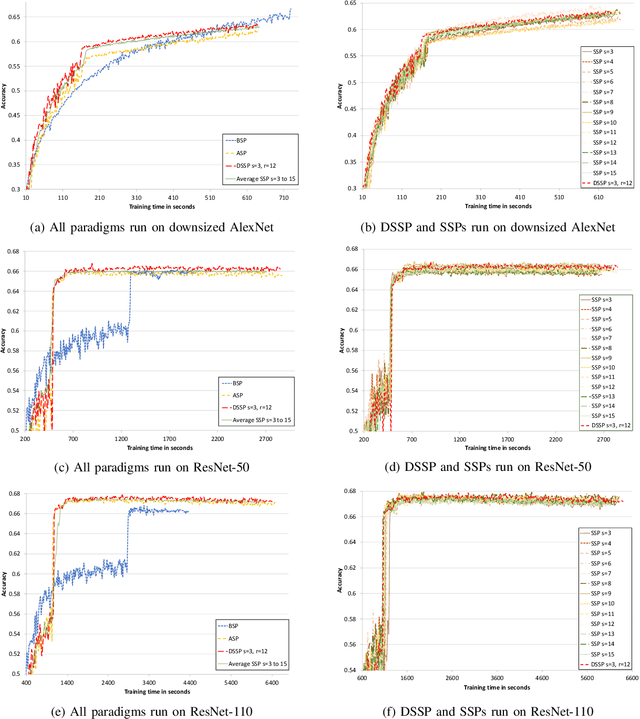
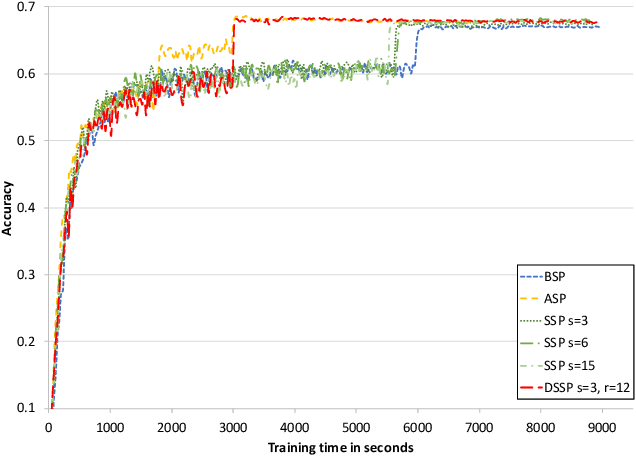
Deep learning is a popular machine learning technique and has been applied to many real-world problems. However, training a deep neural network is very time-consuming, especially on big data. It has become difficult for a single machine to train a large model over large datasets. A popular solution is to distribute and parallelize the training process across multiple machines using the parameter server framework. In this paper, we present a distributed paradigm on the parameter server framework called Dynamic Stale Synchronous Parallel (DSSP) which improves the state-of-the-art Stale Synchronous Parallel (SSP) paradigm by dynamically determining the staleness threshold at the run time. Conventionally to run distributed training in SSP, the user needs to specify a particular staleness threshold as a hyper-parameter. However, a user does not usually know how to set the threshold and thus often finds a threshold value through trial and error, which is time-consuming. Based on workers' recent processing time, our approach DSSP adaptively adjusts the threshold per iteration at running time to reduce the waiting time of faster workers for synchronization of the globally shared parameters, and consequently increases the frequency of parameters updates (increases iteration throughput), which speedups the convergence rate. We compare DSSP with other paradigms such as Bulk Synchronous Parallel (BSP), Asynchronous Parallel (ASP), and SSP by running deep neural networks (DNN) models over GPU clusters in both homogeneous and heterogeneous environments. The results show that in a heterogeneous environment where the cluster consists of mixed models of GPUs, DSSP converges to a higher accuracy much earlier than SSP and BSP and performs similarly to ASP. In a homogeneous distributed cluster, DSSP has more stable and slightly better performance than SSP and ASP, and converges much faster than BSP.
A data-driven method for syndrome type identification and classification in traditional Chinese medicine
Feb 24, 2016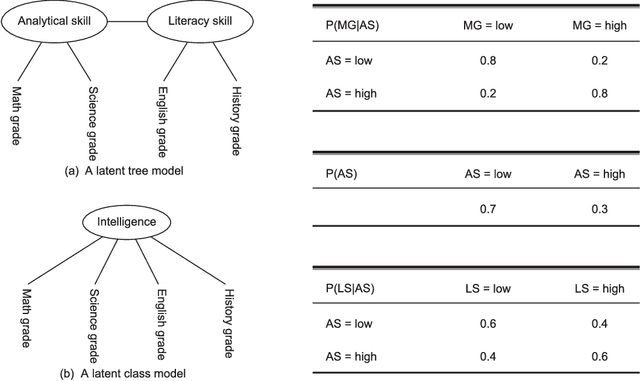


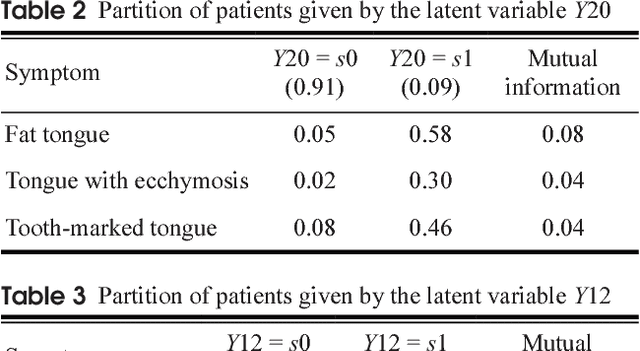
Objective: The efficacy of traditional Chinese medicine (TCM) treatments for Western medicine (WM) diseases relies heavily on the proper classification of patients into TCM syndrome types. We develop a data-driven method for solving the classification problem, where syndrome types are identified and quantified based on patterns detected in unlabeled symptom survey data. Method: Latent class analysis (LCA) has been applied in WM research to solve a similar problem, i.e., to identify subtypes of a patient population in the absence of a gold standard. A widely known weakness of LCA is that it makes an unrealistically strong independence assumption. We relax the assumption by first detecting symptom co-occurrence patterns from survey data and use those patterns instead of the symptoms as features for LCA. Results: The result of the investigation is a six-step method: Data collection, symptom co-occurrence pattern discovery, pattern interpretation, syndrome identification, syndrome type identification, and syndrome type classification. A software package called Lantern is developed to support the application of the method. The method is illustrated using a data set on Vascular Mild Cognitive Impairment (VMCI). Conclusions: A data-driven method for TCM syndrome identification and classification is presented. The method can be used to answer the following questions about a Western medicine disease: What TCM syndrome types are there among the patients with the disease? What is the prevalence of each syndrome type? What are the statistical characteristics of each syndrome type in terms of occurrence of symptoms? How can we determine the syndrome type(s) of a patient?
Identification and classification of TCM syndrome types among patients with vascular mild cognitive impairment using latent tree analysis
Feb 24, 2016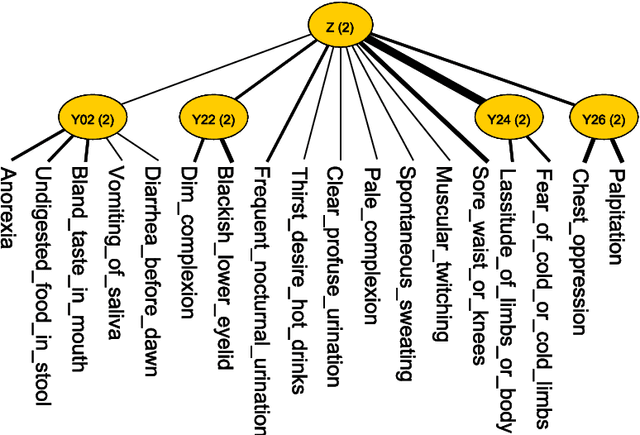
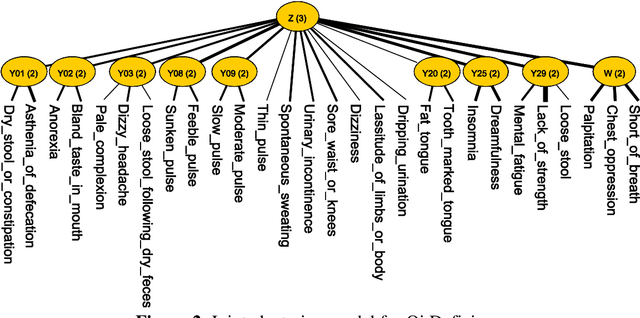
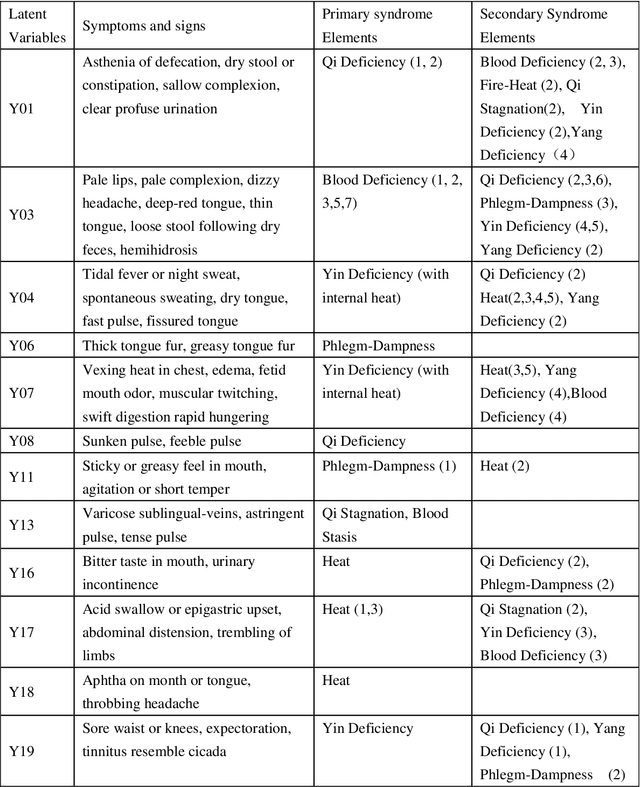
Objective: To treat patients with vascular mild cognitive impairment (VMCI) using TCM, it is necessary to classify the patients into TCM syndrome types and to apply different treatments to different types. We investigate how to properly carry out the classification using a novel data-driven method known as latent tree analysis. Method: A cross-sectional survey on VMCI was carried out in several regions in northern China from 2008 to 2011, which resulted in a data set that involves 803 patients and 93 symptoms. Latent tree analysis was performed on the data to reveal symptom co-occurrence patterns, and the patients were partitioned into clusters in multiple ways based on the patterns. The patient clusters were matched up with syndrome types, and population statistics of the clusters are used to quantify the syndrome types and to establish classification rules. Results: Eight syndrome types are identified: Qi Deficiency, Qi Stagnation, Blood Deficiency, Blood Stasis, Phlegm-Dampness, Fire-Heat, Yang Deficiency, and Yin Deficiency. The prevalence and symptom occurrence characteristics of each syndrome type are determined. Quantitative classification rules are established for determining whether a patient belongs to each of the syndrome types. Conclusions: A solution for the TCM syndrome classification problem associated with VMCI is established based on the latent tree analysis of unlabeled symptom survey data. The results can be used as a reference in clinic practice to improve the quality of syndrome differentiation and to reduce diagnosis variances across physicians. They can also be used for patient selection in research projects aimed at finding biomarkers for the syndrome types and in randomized control trials aimed at determining the efficacy of TCM treatments of VMCI.