 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSteerSeg: Attention Steering for Reasoning Video Segmentation
May 14, 2026Video reasoning segmentation requires localizing objects across video frames from natural language expressions, often involving spatial reasoning and implicit references. Recent approaches leverage frozen large vision-language models (LVLMs) by extracting attention maps and using them as spatial priors for segmentation, enabling training-free grounding. However, these attention maps are optimized for text generation rather than spatial localization, often resulting in diffuse and ambiguous grounding signals. In this work, we introduce SteerSeg, a lightweight framework that identifies attention misalignment as the key bottleneck in attention-based grounding and proposes to steer attention at its source through input-level conditioning. SteerSeg combines learnable soft prompts with reasoning-guided Chain-of-Thought (CoT) prompting. The soft prompts reshape the attention distribution to produce more spatially concentrated maps, while CoT-derived attributes resolve ambiguity among similar objects by guiding attention toward the correct instance. The resulting attention maps are converted into point prompts across keyframes to guide a segmentation model, while candidate tracklets are ranked and selected using correlation-based scoring. Our approach freezes the LVLM and segmentation model parameters and learns only a small set of soft prompts, preserving the model's pretrained reasoning capabilities while significantly improving grounding. Despite being trained only on Ref-YouTube-VOS, SteerSeg generalizes well across diverse benchmarks, significantly improving the spatial grounding capability of LVLMs. Project page: https://steerseg.github.io
Fighting Hallucinations with Counterfactuals: Diffusion-Guided Perturbations for LVLM Hallucination Suppression
Mar 11, 2026While large vision-language models (LVLMs) achieve strong performance on multimodal tasks, they frequently generate hallucinations -- unfaithful outputs misaligned with the visual input. To address this issue, we introduce CIPHER (Counterfactual Image Perturbations for Hallucination Extraction and Removal), a training-free method that suppresses vision-induced hallucinations via lightweight feature-level correction. Unlike prior training-free approaches that primarily focus on text-induced hallucinations, CIPHER explicitly targets hallucinations arising from the visual modality. CIPHER operates in two phases. In the offline phase, we construct OHC-25K (Object-Hallucinated Counterfactuals, 25,000 samples), a counterfactual dataset consisting of diffusion-edited images that intentionally contradict the original ground-truth captions. We pair these edited images with the unchanged ground-truth captions and process them through an LVLM to extract hallucination-related representations. Contrasting these representations with those from authentic (image, caption) pairs reveals structured, systematic shifts spanning a low-rank subspace characterizing vision-induced hallucination. In the inference phase, CIPHER suppresses hallucinations by projecting intermediate hidden states away from this subspace. Experiments across multiple benchmarks show that CIPHER significantly reduces hallucination rates while preserving task performance, demonstrating the effectiveness of counterfactual visual perturbations for improving LVLM faithfulness. Code and additional materials are available at https://hamidreza-dastmalchi.github.io/cipher-cvpr2026/.
Adapt-As-You-Walk Through the Clouds: Training-Free Online Test-Time Adaptation of 3D Vision-Language Foundation Models
Nov 19, 2025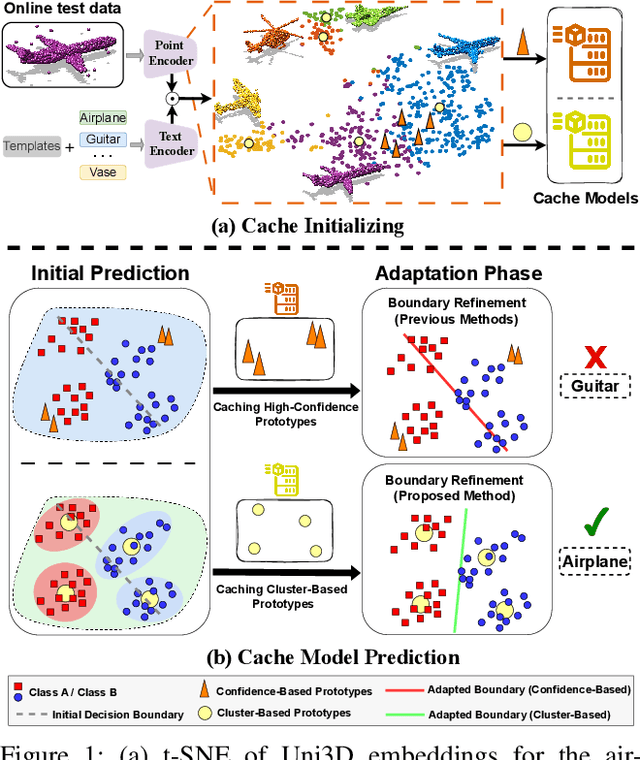
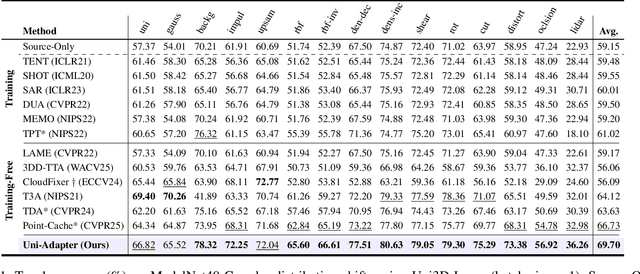
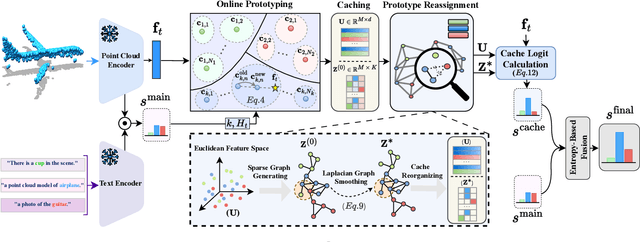
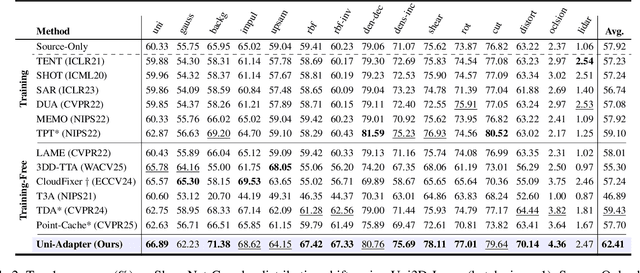
3D Vision-Language Foundation Models (VLFMs) have shown strong generalization and zero-shot recognition capabilities in open-world point cloud processing tasks. However, these models often underperform in practical scenarios where data are noisy, incomplete, or drawn from a different distribution than the training data. To address this, we propose Uni-Adapter, a novel training-free online test-time adaptation (TTA) strategy for 3D VLFMs based on dynamic prototype learning. We define a 3D cache to store class-specific cluster centers as prototypes, which are continuously updated to capture intra-class variability in heterogeneous data distributions. These dynamic prototypes serve as anchors for cache-based logit computation via similarity scoring. Simultaneously, a graph-based label smoothing module captures inter-prototype similarities to enforce label consistency among similar prototypes. Finally, we unify predictions from the original 3D VLFM and the refined 3D cache using entropy-weighted aggregation for reliable adaptation. Without retraining, Uni-Adapter effectively mitigates distribution shifts, achieving state-of-the-art performance on diverse 3D benchmarks over different 3D VLFMs, improving ModelNet-40C by 10.55%, ScanObjectNN-C by 8.26%, and ShapeNet-C by 4.49% over the source 3D VLFMs.
Evolution of ReID: From Early Methods to LLM Integration
Jun 16, 2025



Person re-identification (ReID) has evolved from handcrafted feature-based methods to deep learning approaches and, more recently, to models incorporating large language models (LLMs). Early methods struggled with variations in lighting, pose, and viewpoint, but deep learning addressed these issues by learning robust visual features. Building on this, LLMs now enable ReID systems to integrate semantic and contextual information through natural language. This survey traces that full evolution and offers one of the first comprehensive reviews of ReID approaches that leverage LLMs, where textual descriptions are used as privileged information to improve visual matching. A key contribution is the use of dynamic, identity-specific prompts generated by GPT-4o, which enhance the alignment between images and text in vision-language ReID systems. Experimental results show that these descriptions improve accuracy, especially in complex or ambiguous cases. To support further research, we release a large set of GPT-4o-generated descriptions for standard ReID datasets. By bridging computer vision and natural language processing, this survey offers a unified perspective on the field's development and outlines key future directions such as better prompt design, cross-modal transfer learning, and real-world adaptability.
Test-Time Adaptation of 3D Point Clouds via Denoising Diffusion Models
Nov 21, 2024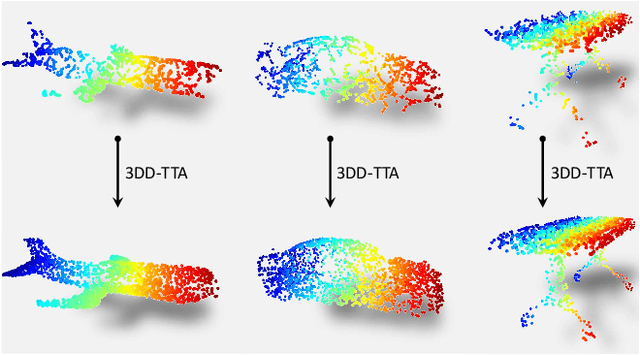
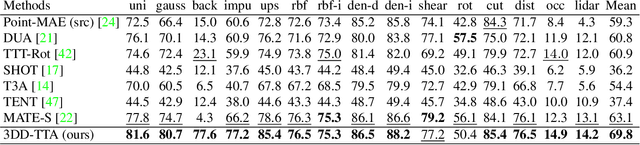
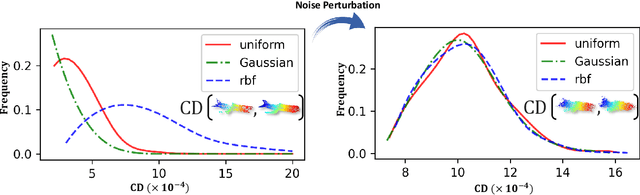
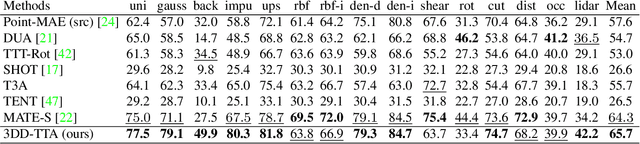
Test-time adaptation (TTA) of 3D point clouds is crucial for mitigating discrepancies between training and testing samples in real-world scenarios, particularly when handling corrupted point clouds. LiDAR data, for instance, can be affected by sensor failures or environmental factors, causing domain gaps. Adapting models to these distribution shifts online is crucial, as training for every possible variation is impractical. Existing methods often focus on fine-tuning pre-trained models based on self-supervised learning or pseudo-labeling, which can lead to forgetting valuable source domain knowledge over time and reduce generalization on future tests. In this paper, we introduce a novel 3D test-time adaptation method, termed 3DD-TTA, which stands for 3D Denoising Diffusion Test-Time Adaptation. This method uses a diffusion strategy that adapts input point cloud samples to the source domain while keeping the source model parameters intact. The approach uses a Variational Autoencoder (VAE) to encode the corrupted point cloud into a shape latent and latent points. These latent points are corrupted with Gaussian noise and subjected to a denoising diffusion process. During this process, both the shape latent and latent points are updated to preserve fidelity, guiding the denoising toward generating consistent samples that align more closely with the source domain. We conduct extensive experiments on the ShapeNet dataset and investigate its generalizability on ModelNet40 and ScanObjectNN, achieving state-of-the-art results. The code has been released at \url{https://github.com/hamidreza-dastmalchi/3DD-TTA}.
Disease Outbreak Detection and Forecasting: A Review of Methods and Data Sources
Oct 21, 2024Infectious diseases occur when pathogens from other individuals or animals infect a person, resulting in harm to both individuals and society as a whole. The outbreak of such diseases can pose a significant threat to human health. However, early detection and tracking of these outbreaks have the potential to reduce the mortality impact. To address these threats, public health authorities have endeavored to establish comprehensive mechanisms for collecting disease data. Many countries have implemented infectious disease surveillance systems, with the detection of epidemics being a primary objective. The clinical healthcare system, local/state health agencies, federal agencies, academic/professional groups, and collaborating governmental entities all play pivotal roles within this system. Moreover, nowadays, search engines and social media platforms can serve as valuable tools for monitoring disease trends. The Internet and social media have become significant platforms where users share information about their preferences and relationships. This real-time information can be harnessed to gauge the influence of ideas and societal opinions, making it highly useful across various domains and research areas, such as marketing campaigns, financial predictions, and public health, among others. This article provides a review of the existing standard methods developed by researchers for detecting outbreaks using time series data. These methods leverage various data sources, including conventional data sources and social media data or Internet data sources. The review particularly concentrates on works published within the timeframe of 2015 to 2022.
A Survey on Graph Representation Learning Methods
Apr 04, 2022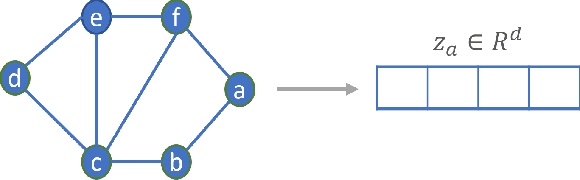

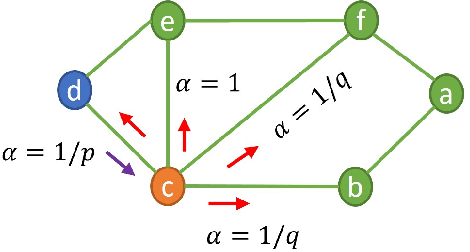

Graphs representation learning has been a very active research area in recent years. The goal of graph representation learning is to generate graph representation vectors that capture the structure and features of large graphs accurately. This is especially important because the quality of the graph representation vectors will affect the performance of these vectors in downstream tasks such as node classification, link prediction and anomaly detection. Many techniques are proposed for generating effective graph representation vectors. Two of the most prevalent categories of graph representation learning are graph embedding methods without using graph neural nets (GNN), which we denote as non-GNN based graph embedding methods, and graph neural nets (GNN) based methods. Non-GNN graph embedding methods are based on techniques such as random walks, temporal point processes and neural network learning methods. GNN-based methods, on the other hand, are the application of deep learning on graph data. In this survey, we provide an overview of these two categories and cover the current state-of-the-art methods for both static and dynamic graphs. Finally, we explore some open and ongoing research directions for future work.
Extending Isolation Forest for Anomaly Detection in Big Data via K-Means
Apr 27, 2021


Industrial Information Technology (IT) infrastructures are often vulnerable to cyberattacks. To ensure security to the computer systems in an industrial environment, it is required to build effective intrusion detection systems to monitor the cyber-physical systems (e.g., computer networks) in the industry for malicious activities. This paper aims to build such intrusion detection systems to protect the computer networks from cyberattacks. More specifically, we propose a novel unsupervised machine learning approach that combines the K-Means algorithm with the Isolation Forest for anomaly detection in industrial big data scenarios. Since our objective is to build the intrusion detection system for the big data scenario in the industrial domain, we utilize the Apache Spark framework to implement our proposed model which was trained in large network traffic data (about 123 million instances of network traffic) stored in Elasticsearch. Moreover, we evaluate our proposed model on the live streaming data and find that our proposed system can be used for real-time anomaly detection in the industrial setup. In addition, we address different challenges that we face while training our model on large datasets and explicitly describe how these issues were resolved. Based on our empirical evaluation in different use-cases for anomaly detection in real-world network traffic data, we observe that our proposed system is effective to detect anomalies in big data scenarios. Finally, we evaluate our proposed model on several academic datasets to compare with other models and find that it provides comparable performance with other state-of-the-art approaches.
Elastic Bulk Synchronous Parallel Model for Distributed Deep Learning
Jan 06, 2020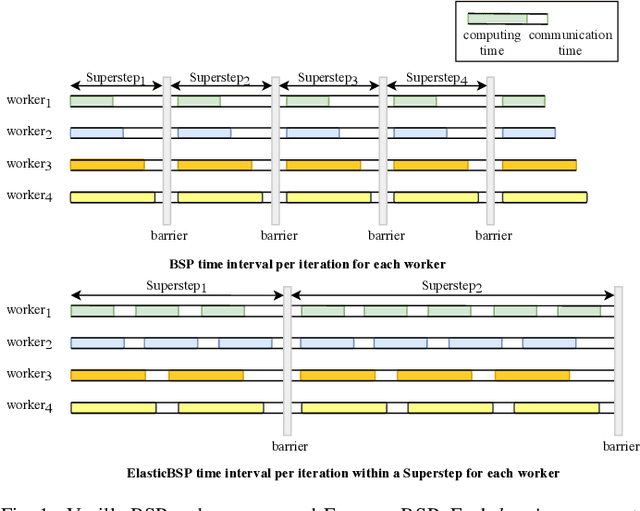
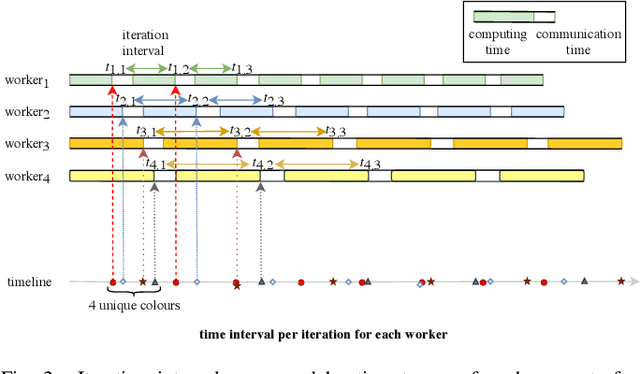
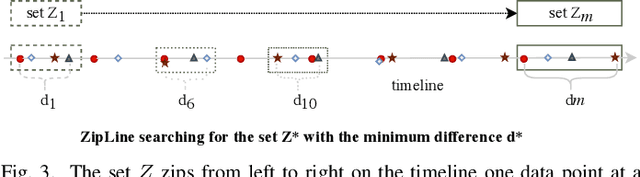
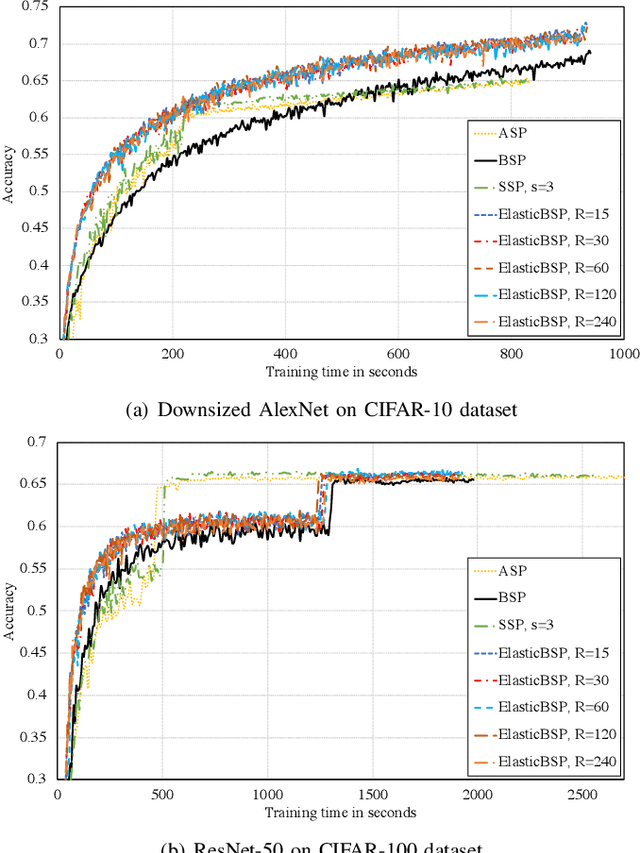
The bulk synchronous parallel (BSP) is a celebrated synchronization model for general-purpose parallel computing that has successfully been employed for distributed training of machine learning models. A prevalent shortcoming of the BSP is that it requires workers to wait for the straggler at every iteration. To ameliorate this shortcoming of classic BSP, we propose ELASTICBSP a model that aims to relax its strict synchronization requirement. The proposed model offers more flexibility and adaptability during the training phase, without sacrificing on the accuracy of the trained model. We also propose an efficient method that materializes the model, named ZIPLINE. The algorithm is tunable and can effectively balance the trade-off between quality of convergence and iteration throughput, in order to accommodate different environments or applications. A thorough experimental evaluation demonstrates that our proposed ELASTICBSP model converges faster and to a higher accuracy than the classic BSP. It also achieves comparable (if not higher) accuracy than the other sensible synchronization models.
* The paper was accepted in the proceedings of the IEEE International Conference on Data Mining 2019 (ICDM'19), 1504-1509
Learning to Determine the Quality of News Headlines
Nov 26, 2019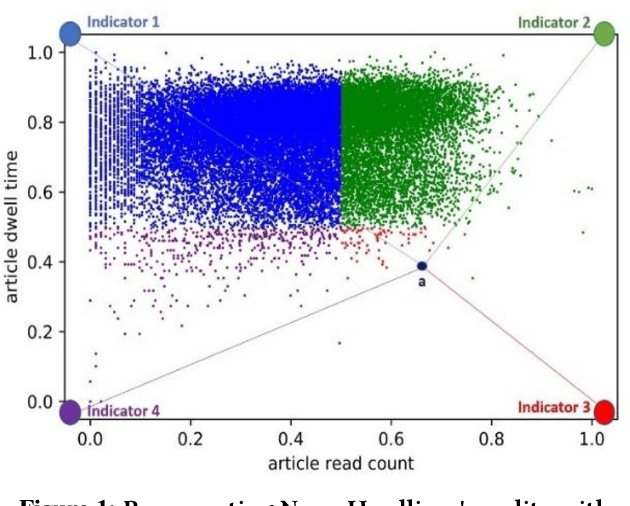
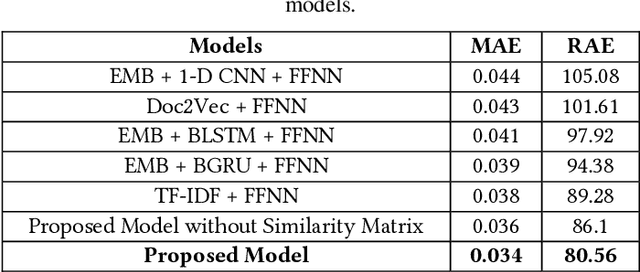
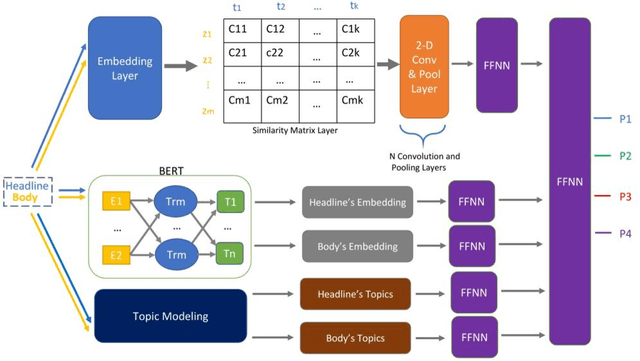
Today, most newsreaders read the online version of news articles rather than traditional paper-based newspapers. Also, news media publishers rely heavily on the income generated from subscriptions and website visits made by newsreaders. Thus, online user engagement is a very important issue for online newspapers. Much effort has been spent on writing interesting headlines to catch the attention of online users. On the other hand, headlines should not be misleading (e.g., clickbaits); otherwise, readers would be disappointed when reading the content. In this paper, we propose four indicators to determine the quality of published news headlines based on their click count and dwell time, which are obtained by website log analysis. Then, we use soft target distribution of the calculated quality indicators to train our proposed deep learning model which can predict the quality of unpublished news headlines. The proposed model not only processes the latent features of both headline and body of the article to predict its headline quality but also considers the semantic relation between headline and body as well. To evaluate our model, we use a real dataset from a major Canadian newspaper. Results show our proposed model outperforms other state-of-the-art NLP models.