 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmartMixed: A Two-Phase Training Strategy for Adaptive Activation Function Learning in Neural Networks
Oct 25, 2025The choice of activation function plays a critical role in neural networks, yet most architectures still rely on fixed, uniform activation functions across all neurons. We introduce SmartMixed, a two-phase training strategy that allows networks to learn optimal per-neuron activation functions while preserving computational efficiency at inference. In the first phase, neurons adaptively select from a pool of candidate activation functions (ReLU, Sigmoid, Tanh, Leaky ReLU, ELU, SELU) using a differentiable hard-mixture mechanism. In the second phase, each neuron's activation function is fixed according to the learned selection, resulting in a computationally efficient network that supports continued training with optimized vectorized operations. We evaluate SmartMixed on the MNIST dataset using feedforward neural networks of varying depths. The analysis shows that neurons in different layers exhibit distinct preferences for activation functions, providing insights into the functional diversity within neural architectures.
Learning to Determine the Quality of News Headlines
Nov 26, 2019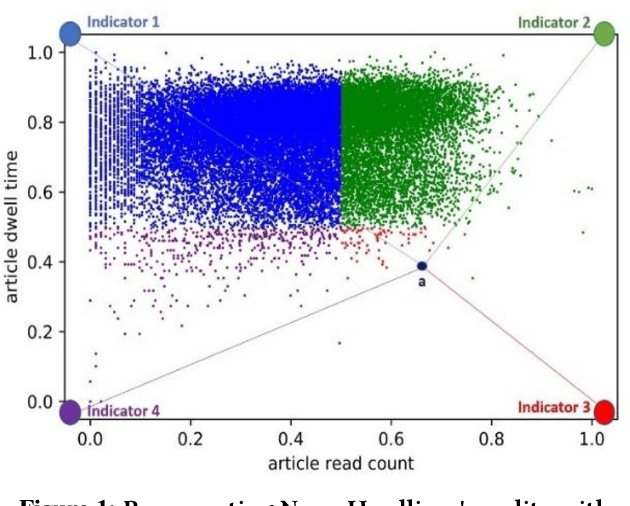
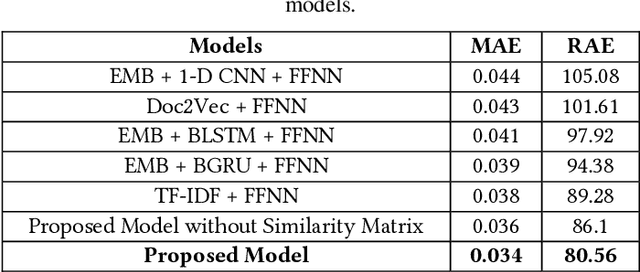
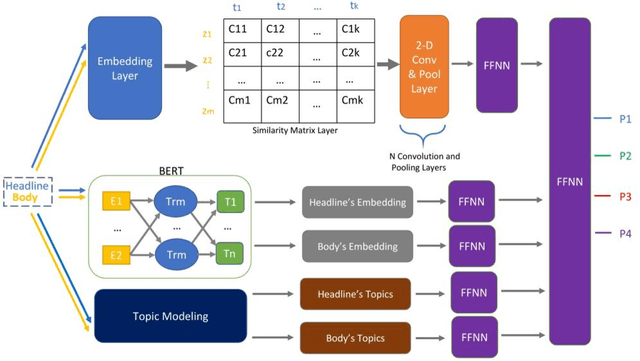
Today, most newsreaders read the online version of news articles rather than traditional paper-based newspapers. Also, news media publishers rely heavily on the income generated from subscriptions and website visits made by newsreaders. Thus, online user engagement is a very important issue for online newspapers. Much effort has been spent on writing interesting headlines to catch the attention of online users. On the other hand, headlines should not be misleading (e.g., clickbaits); otherwise, readers would be disappointed when reading the content. In this paper, we propose four indicators to determine the quality of published news headlines based on their click count and dwell time, which are obtained by website log analysis. Then, we use soft target distribution of the calculated quality indicators to train our proposed deep learning model which can predict the quality of unpublished news headlines. The proposed model not only processes the latent features of both headline and body of the article to predict its headline quality but also considers the semantic relation between headline and body as well. To evaluate our model, we use a real dataset from a major Canadian newspaper. Results show our proposed model outperforms other state-of-the-art NLP models.
Using Neural Network for Identifying Clickbaits in Online News Media
Jun 20, 2018
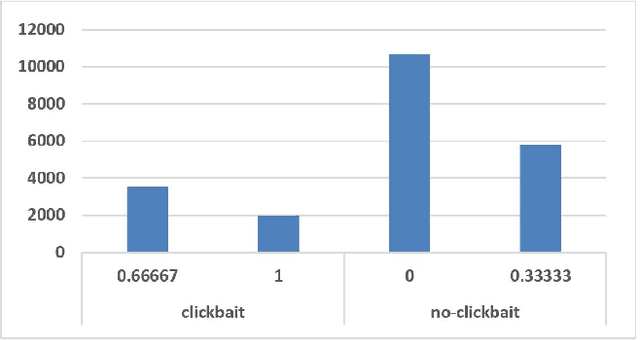
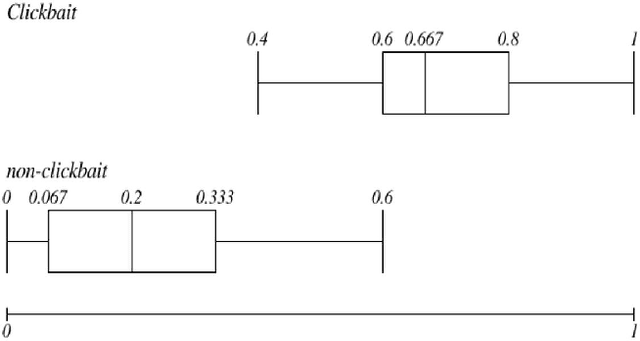

Online news media sometimes use misleading headlines to lure users to open the news article. These catchy headlines that attract users but disappointed them at the end, are called Clickbaits. Because of the importance of automatic clickbait detection in online medias, lots of machine learning methods were proposed and employed to find the clickbait headlines. In this research, a model using deep learning methods is proposed to find the clickbaits in Clickbait Challenge 2017's dataset. The proposed model gained the first rank in the Clickbait Challenge 2017 in terms of Mean Squared Error. Also, data analytics and visualization techniques are employed to explore and discover the provided dataset to get more insight from the data.