 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNetwork-Constrained Policy Optimization for Adaptive Multi-agent Vehicle Routing
Oct 30, 2025Traffic congestion in urban road networks leads to longer trip times and higher emissions, especially during peak periods. While the Shortest Path First (SPF) algorithm is optimal for a single vehicle in a static network, it performs poorly in dynamic, multi-vehicle settings, often worsening congestion by routing all vehicles along identical paths. We address dynamic vehicle routing through a multi-agent reinforcement learning (MARL) framework for coordinated, network-aware fleet navigation. We first propose Adaptive Navigation (AN), a decentralized MARL model where each intersection agent provides routing guidance based on (i) local traffic and (ii) neighborhood state modeled using Graph Attention Networks (GAT). To improve scalability in large networks, we further propose Hierarchical Hub-based Adaptive Navigation (HHAN), an extension of AN that assigns agents only to key intersections (hubs). Vehicles are routed hub-to-hub under agent control, while SPF handles micro-routing within each hub region. For hub coordination, HHAN adopts centralized training with decentralized execution (CTDE) under the Attentive Q-Mixing (A-QMIX) framework, which aggregates asynchronous vehicle decisions via attention. Hub agents use flow-aware state features that combine local congestion and predictive dynamics for proactive routing. Experiments on synthetic grids and real urban maps (Toronto, Manhattan) show that AN reduces average travel time versus SPF and learning baselines, maintaining 100% routing success. HHAN scales to networks with hundreds of intersections, achieving up to 15.9% improvement under heavy traffic. These findings highlight the potential of network-constrained MARL for scalable, coordinated, and congestion-aware routing in intelligent transportation systems.
TrajLearn: Trajectory Prediction Learning using Deep Generative Models
Dec 30, 2024



Trajectory prediction aims to estimate an entity's future path using its current position and historical movement data, benefiting fields like autonomous navigation, robotics, and human movement analytics. Deep learning approaches have become key in this area, utilizing large-scale trajectory datasets to model movement patterns, but face challenges in managing complex spatial dependencies and adapting to dynamic environments. To address these challenges, we introduce TrajLearn, a novel model for trajectory prediction that leverages generative modeling of higher-order mobility flows based on hexagonal spatial representation. TrajLearn predicts the next $k$ steps by integrating a customized beam search for exploring multiple potential paths while maintaining spatial continuity. We conducted a rigorous evaluation of TrajLearn, benchmarking it against leading state-of-the-art approaches and meaningful baselines. The results indicate that TrajLearn achieves significant performance gains, with improvements of up to ~40% across multiple real-world trajectory datasets. In addition, we evaluated different prediction horizons (i.e., various values of $k$), conducted resolution sensitivity analysis, and performed ablation studies to assess the impact of key model components. Furthermore, we developed a novel algorithm to generate mixed-resolution maps by hierarchically subdividing hexagonal regions into finer segments within a specified observation area. This approach supports selective detailing, applying finer resolution to areas of interest or high activity (e.g., urban centers) while using coarser resolution for less significant regions (e.g., rural areas), effectively reducing data storage requirements and computational overhead. We promote reproducibility and adaptability by offering complete code, data, and detailed documentation with flexible configuration options for various applications.
PathletRL++: Optimizing Trajectory Pathlet Extraction and Dictionary Formation via Reinforcement Learning
Dec 04, 2024



Advances in tracking technologies have spurred the rapid growth of large-scale trajectory data. Building a compact collection of pathlets, referred to as a trajectory pathlet dictionary, is essential for supporting mobility-related applications. Existing methods typically adopt a top-down approach, generating numerous candidate pathlets and selecting a subset, leading to high memory usage and redundant storage from overlapping pathlets. To overcome these limitations, we propose a bottom-up strategy that incrementally merges basic pathlets to build the dictionary, reducing memory requirements by up to 24,000 times compared to baseline methods. The approach begins with unit-length pathlets and iteratively merges them while optimizing utility, which is defined using newly introduced metrics of trajectory loss and representability. We develop a deep reinforcement learning framework, PathletRL, which utilizes Deep Q-Networks (DQN) to approximate the utility function, resulting in a compact and efficient pathlet dictionary. Experiments on both synthetic and real-world datasets demonstrate that our method outperforms state-of-the-art techniques, reducing the size of the constructed dictionary by up to 65.8%. Additionally, our results show that only half of the dictionary pathlets are needed to reconstruct 85% of the original trajectory data. Building on PathletRL, we introduce PathletRL++, which extends the original model by incorporating a richer state representation and an improved reward function to optimize decision-making during pathlet merging. These enhancements enable the agent to gain a more nuanced understanding of the environment, leading to higher-quality pathlet dictionaries. PathletRL++ achieves even greater dictionary size reduction, surpassing the performance of PathletRL, while maintaining high trajectory representability.
Disease Outbreak Detection and Forecasting: A Review of Methods and Data Sources
Oct 21, 2024Infectious diseases occur when pathogens from other individuals or animals infect a person, resulting in harm to both individuals and society as a whole. The outbreak of such diseases can pose a significant threat to human health. However, early detection and tracking of these outbreaks have the potential to reduce the mortality impact. To address these threats, public health authorities have endeavored to establish comprehensive mechanisms for collecting disease data. Many countries have implemented infectious disease surveillance systems, with the detection of epidemics being a primary objective. The clinical healthcare system, local/state health agencies, federal agencies, academic/professional groups, and collaborating governmental entities all play pivotal roles within this system. Moreover, nowadays, search engines and social media platforms can serve as valuable tools for monitoring disease trends. The Internet and social media have become significant platforms where users share information about their preferences and relationships. This real-time information can be harnessed to gauge the influence of ideas and societal opinions, making it highly useful across various domains and research areas, such as marketing campaigns, financial predictions, and public health, among others. This article provides a review of the existing standard methods developed by researchers for detecting outbreaks using time series data. These methods leverage various data sources, including conventional data sources and social media data or Internet data sources. The review particularly concentrates on works published within the timeframe of 2015 to 2022.
Knowledge-Aware Conversation Derailment Forecasting Using Graph Convolutional Networks
Aug 24, 2024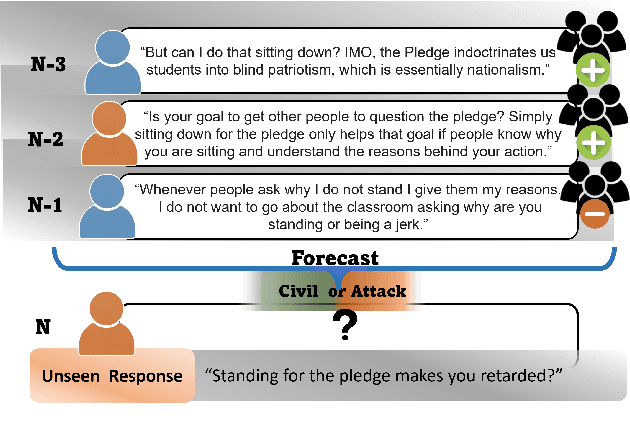
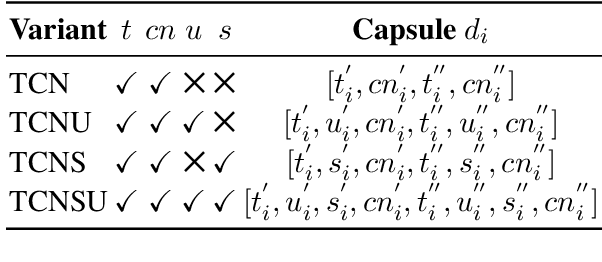
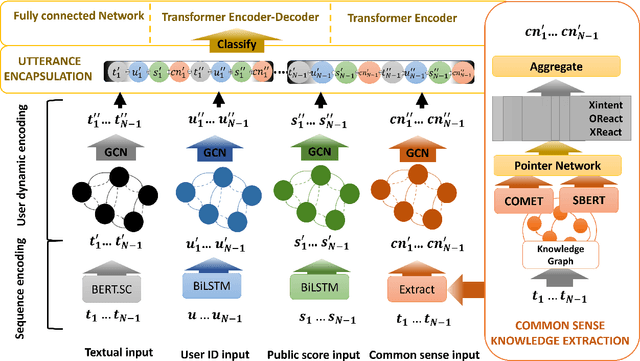
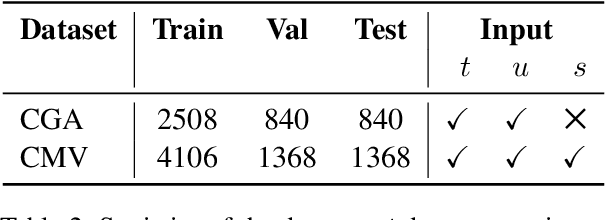
Online conversations are particularly susceptible to derailment, which can manifest itself in the form of toxic communication patterns including disrespectful comments and abuse. Forecasting conversation derailment predicts signs of derailment in advance enabling proactive moderation of conversations. State-of-the-art approaches to conversation derailment forecasting sequentially encode conversations and use graph neural networks to model dialogue user dynamics. However, existing graph models are not able to capture complex conversational characteristics such as context propagation and emotional shifts. The use of common sense knowledge enables a model to capture such characteristics, thus improving performance. Following this approach, here we derive commonsense statements from a knowledge base of dialogue contextual information to enrich a graph neural network classification architecture. We fuse the multi-source information on utterance into capsules, which are used by a transformer-based forecaster to predict conversation derailment. Our model captures conversation dynamics and context propagation, outperforming the state-of-the-art models on the CGA and CMV benchmark datasets
LearnedWMP: Workload Memory Prediction Using Distribution of Query Templates
Jan 22, 2024



In a modern DBMS, working memory is frequently the limiting factor when processing in-memory analytic query operations such as joins, sorting, and aggregation. Existing resource estimation approaches for a DBMS estimate the resource consumption of a query by computing an estimate of each individual database operator in the query execution plan. Such an approach is slow and error-prone as it relies upon simplifying assumptions, such as uniformity and independence of the underlying data. Additionally, the existing approach focuses on individual queries separately and does not factor in other queries in the workload that may be executed concurrently. In this research, we are interested in query performance optimization under concurrent execution of a batch of queries (a workload). Specifically, we focus on predicting the memory demand for a workload rather than providing separate estimates for each query within it. We introduce the problem of workload memory prediction and formalize it as a distribution regression problem. We propose Learned Workload Memory Prediction (LearnedWMP) to improve and simplify estimating the working memory demands of workloads. Through a comprehensive experimental evaluation, we show that LearnedWMP reduces the memory estimation error of the state-of-the-practice method by up to 47.6%. Compared to an alternative single-query model, during training and inferencing, the LearnedWMP model and its variants were 3x to 10x faster. Moreover, LearnedWMP-based models were at least 50% smaller in most cases. Overall, the results demonstrate the advantages of the LearnedWMP approach and its potential for a broader impact on query performance optimization.
Predicting Evoked Emotions in Conversations
Dec 31, 2023Understanding and predicting the emotional trajectory in multi-party multi-turn conversations is of great significance. Such information can be used, for example, to generate empathetic response in human-machine interaction or to inform models of pre-emptive toxicity detection. In this work, we introduce the novel problem of Predicting Emotions in Conversations (PEC) for the next turn (n+1), given combinations of textual and/or emotion input up to turn n. We systematically approach the problem by modeling three dimensions inherently connected to evoked emotions in dialogues, including (i) sequence modeling, (ii) self-dependency modeling, and (iii) recency modeling. These modeling dimensions are then incorporated into two deep neural network architectures, a sequence model and a graph convolutional network model. The former is designed to capture the sequence of utterances in a dialogue, while the latter captures the sequence of utterances and the network formation of multi-party dialogues. We perform a comprehensive empirical evaluation of the various proposed models for addressing the PEC problem. The results indicate (i) the importance of the self-dependency and recency model dimensions for the prediction task, (ii) the quality of simpler sequence models in short dialogues, (iii) the importance of the graph neural models in improving the predictions in long dialogues.
Conversation Derailment Forecasting with Graph Convolutional Networks
Jun 22, 2023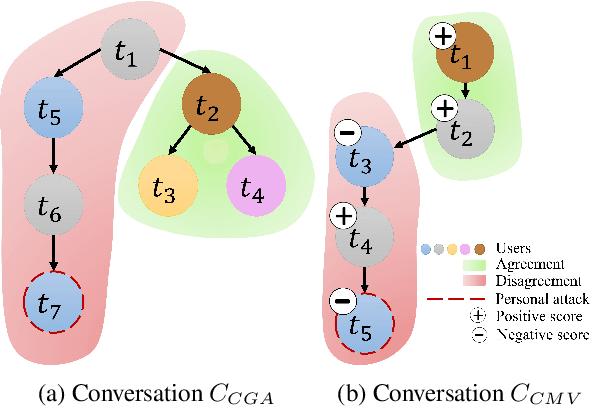

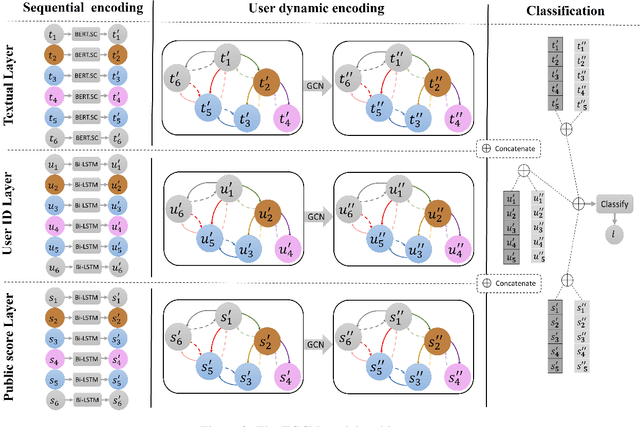
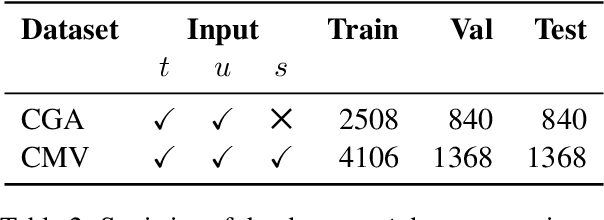
Online conversations are particularly susceptible to derailment, which can manifest itself in the form of toxic communication patterns like disrespectful comments or verbal abuse. Forecasting conversation derailment predicts signs of derailment in advance enabling proactive moderation of conversations. Current state-of-the-art approaches to address this problem rely on sequence models that treat dialogues as text streams. We propose a novel model based on a graph convolutional neural network that considers dialogue user dynamics and the influence of public perception on conversation utterances. Through empirical evaluation, we show that our model effectively captures conversation dynamics and outperforms the state-of-the-art models on the CGA and CMV benchmark datasets by 1.5\% and 1.7\%, respectively.
Industry and Academic Research in Computer Vision
Jul 17, 2021



This work aims to study the dynamic between research in the industry and academia in computer vision. The results are demonstrated on a set of top-5 vision conferences that are representative of the field. Since data for such analysis was not readily available, significant effort was spent on gathering and processing meta-data from the original publications. First, this study quantifies the share of industry-sponsored research. Specifically, it shows that the proportion of papers published by industry-affiliated researchers is increasing and that more academics join companies or collaborate with them. Next, the possible impact of industry presence is further explored, namely in the distribution of research topics and citation patterns. The results indicate that the distribution of the research topics is similar in industry and academic papers. However, there is a strong preference towards citing industry papers. Finally, possible reasons for citation bias, such as code availability and influence, are investigated.
Elastic Bulk Synchronous Parallel Model for Distributed Deep Learning
Jan 06, 2020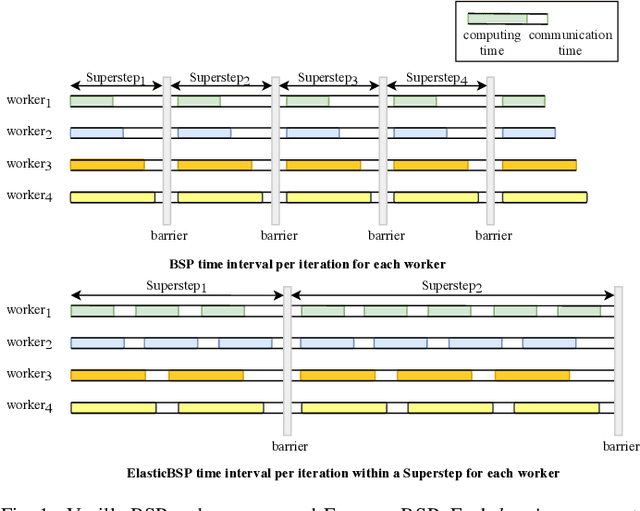
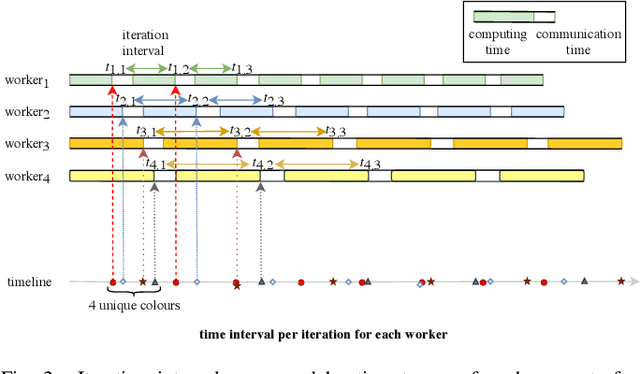
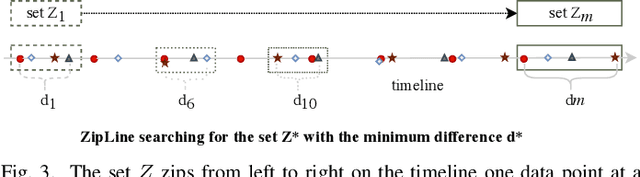
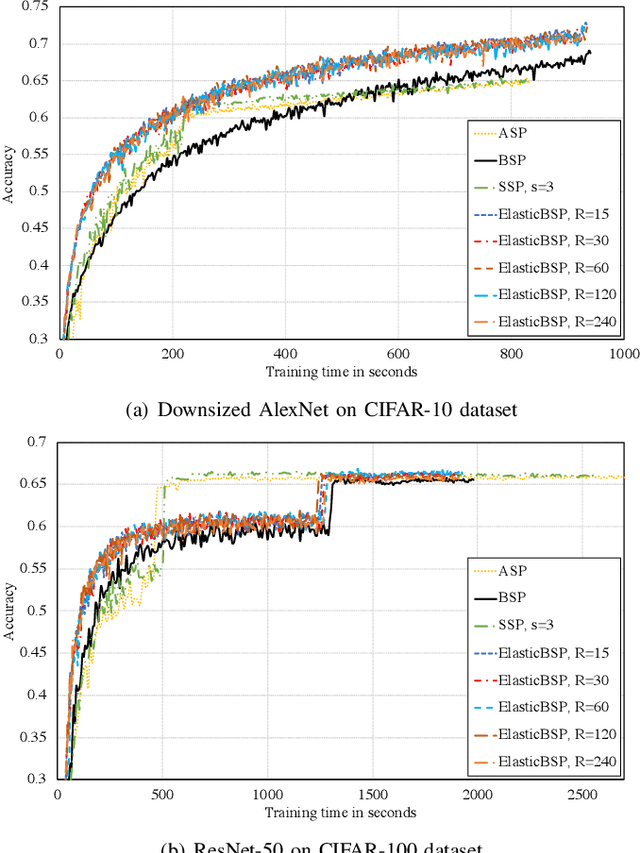
The bulk synchronous parallel (BSP) is a celebrated synchronization model for general-purpose parallel computing that has successfully been employed for distributed training of machine learning models. A prevalent shortcoming of the BSP is that it requires workers to wait for the straggler at every iteration. To ameliorate this shortcoming of classic BSP, we propose ELASTICBSP a model that aims to relax its strict synchronization requirement. The proposed model offers more flexibility and adaptability during the training phase, without sacrificing on the accuracy of the trained model. We also propose an efficient method that materializes the model, named ZIPLINE. The algorithm is tunable and can effectively balance the trade-off between quality of convergence and iteration throughput, in order to accommodate different environments or applications. A thorough experimental evaluation demonstrates that our proposed ELASTICBSP model converges faster and to a higher accuracy than the classic BSP. It also achieves comparable (if not higher) accuracy than the other sensible synchronization models.
* The paper was accepted in the proceedings of the IEEE International Conference on Data Mining 2019 (ICDM'19), 1504-1509