 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Learning-Based Caching Mechanism for Edge Content Delivery
Feb 05, 2024



With the advent of 5G networks and the rise of the Internet of Things (IoT), Content Delivery Networks (CDNs) are increasingly extending into the network edge. This shift introduces unique challenges, particularly due to the limited cache storage and the diverse request patterns at the edge. These edge environments can host traffic classes characterized by varied object-size distributions and object-access patterns. Such complexity makes it difficult for traditional caching strategies, which often rely on metrics like request frequency or time intervals, to be effective. Despite these complexities, the optimization of edge caching is crucial. Improved byte hit rates at the edge not only alleviate the load on the network backbone but also minimize operational costs and expedite content delivery to end-users. In this paper, we introduce HR-Cache, a comprehensive learning-based caching framework grounded in the principles of Hazard Rate (HR) ordering, a rule originally formulated to compute an upper bound on cache performance. HR-Cache leverages this rule to guide future object eviction decisions. It employs a lightweight machine learning model to learn from caching decisions made based on HR ordering, subsequently predicting the "cache-friendliness" of incoming requests. Objects deemed "cache-averse" are placed into cache as priority candidates for eviction. Through extensive experimentation, we demonstrate that HR-Cache not only consistently enhances byte hit rates compared to existing state-of-the-art methods but also achieves this with minimal prediction overhead. Our experimental results, using three real-world traces and one synthetic trace, indicate that HR-Cache consistently achieves 2.2-14.6% greater WAN traffic savings than LRU. It outperforms not only heuristic caching strategies but also the state-of-the-art learning-based algorithm.
LearnedWMP: Workload Memory Prediction Using Distribution of Query Templates
Jan 22, 2024



In a modern DBMS, working memory is frequently the limiting factor when processing in-memory analytic query operations such as joins, sorting, and aggregation. Existing resource estimation approaches for a DBMS estimate the resource consumption of a query by computing an estimate of each individual database operator in the query execution plan. Such an approach is slow and error-prone as it relies upon simplifying assumptions, such as uniformity and independence of the underlying data. Additionally, the existing approach focuses on individual queries separately and does not factor in other queries in the workload that may be executed concurrently. In this research, we are interested in query performance optimization under concurrent execution of a batch of queries (a workload). Specifically, we focus on predicting the memory demand for a workload rather than providing separate estimates for each query within it. We introduce the problem of workload memory prediction and formalize it as a distribution regression problem. We propose Learned Workload Memory Prediction (LearnedWMP) to improve and simplify estimating the working memory demands of workloads. Through a comprehensive experimental evaluation, we show that LearnedWMP reduces the memory estimation error of the state-of-the-practice method by up to 47.6%. Compared to an alternative single-query model, during training and inferencing, the LearnedWMP model and its variants were 3x to 10x faster. Moreover, LearnedWMP-based models were at least 50% smaller in most cases. Overall, the results demonstrate the advantages of the LearnedWMP approach and its potential for a broader impact on query performance optimization.
Towards Better Adaptive Systems by Combining MAPE, Control Theory, and Machine Learning
Mar 19, 2021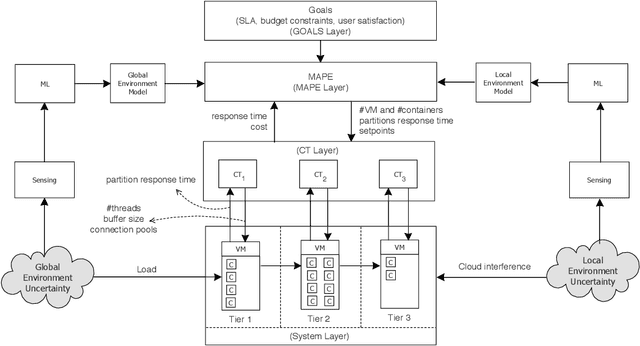


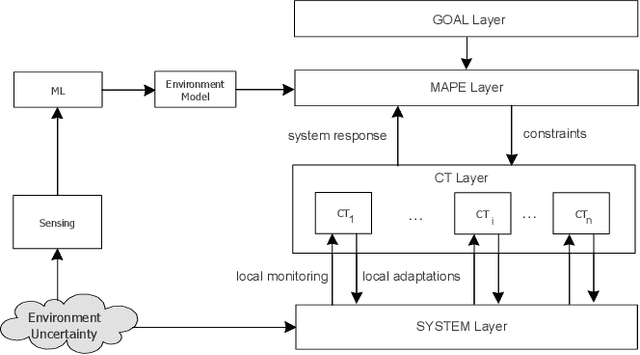
Two established approaches to engineer adaptive systems are architecture-based adaptation that uses a Monitor-Analysis-Planning-Executing (MAPE) loop that reasons over architectural models (aka Knowledge) to make adaptation decisions, and control-based adaptation that relies on principles of control theory (CT) to realize adaptation. Recently, we also observe a rapidly growing interest in applying machine learning (ML) to support different adaptation mechanisms. While MAPE and CT have particular characteristics and strengths to be applied independently, in this paper, we are concerned with the question of how these approaches are related with one another and whether combining them and supporting them with ML can produce better adaptive systems. We motivate the combined use of different adaptation approaches using a scenario of a cloud-based enterprise system and illustrate the analysis when combining the different approaches. To conclude, we offer a set of open questions for further research in this interesting area.
Understanding Brain Dynamics for Color Perception using Wearable EEG headband
Aug 17, 2020



The perception of color is an important cognitive feature of the human brain. The variety of colors that impinge upon the human eye can trigger changes in brain activity which can be captured using electroencephalography (EEG). In this work, we have designed a multiclass classification model to detect the primary colors from the features of raw EEG signals. In contrast to previous research, our method employs spectral power features, statistical features as well as correlation features from the signal band power obtained from continuous Morlet wavelet transform instead of raw EEG, for the classification task. We have applied dimensionality reduction techniques such as Forward Feature Selection and Stacked Autoencoders to reduce the dimension of data eventually increasing the model's efficiency. Our proposed methodology using Forward Selection and Random Forest Classifier gave the best overall accuracy of 80.6\% for intra-subject classification. Our approach shows promise in developing techniques for cognitive tasks using color cues such as controlling Internet of Thing (IoT) devices by looking at primary colors for individuals with restricted motor abilities.
* 10 pages,10 figures, Conference- EVOKE CASCON 2020