 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrajLearn: Trajectory Prediction Learning using Deep Generative Models
Dec 30, 2024



Trajectory prediction aims to estimate an entity's future path using its current position and historical movement data, benefiting fields like autonomous navigation, robotics, and human movement analytics. Deep learning approaches have become key in this area, utilizing large-scale trajectory datasets to model movement patterns, but face challenges in managing complex spatial dependencies and adapting to dynamic environments. To address these challenges, we introduce TrajLearn, a novel model for trajectory prediction that leverages generative modeling of higher-order mobility flows based on hexagonal spatial representation. TrajLearn predicts the next $k$ steps by integrating a customized beam search for exploring multiple potential paths while maintaining spatial continuity. We conducted a rigorous evaluation of TrajLearn, benchmarking it against leading state-of-the-art approaches and meaningful baselines. The results indicate that TrajLearn achieves significant performance gains, with improvements of up to ~40% across multiple real-world trajectory datasets. In addition, we evaluated different prediction horizons (i.e., various values of $k$), conducted resolution sensitivity analysis, and performed ablation studies to assess the impact of key model components. Furthermore, we developed a novel algorithm to generate mixed-resolution maps by hierarchically subdividing hexagonal regions into finer segments within a specified observation area. This approach supports selective detailing, applying finer resolution to areas of interest or high activity (e.g., urban centers) while using coarser resolution for less significant regions (e.g., rural areas), effectively reducing data storage requirements and computational overhead. We promote reproducibility and adaptability by offering complete code, data, and detailed documentation with flexible configuration options for various applications.
LearnedWMP: Workload Memory Prediction Using Distribution of Query Templates
Jan 22, 2024



In a modern DBMS, working memory is frequently the limiting factor when processing in-memory analytic query operations such as joins, sorting, and aggregation. Existing resource estimation approaches for a DBMS estimate the resource consumption of a query by computing an estimate of each individual database operator in the query execution plan. Such an approach is slow and error-prone as it relies upon simplifying assumptions, such as uniformity and independence of the underlying data. Additionally, the existing approach focuses on individual queries separately and does not factor in other queries in the workload that may be executed concurrently. In this research, we are interested in query performance optimization under concurrent execution of a batch of queries (a workload). Specifically, we focus on predicting the memory demand for a workload rather than providing separate estimates for each query within it. We introduce the problem of workload memory prediction and formalize it as a distribution regression problem. We propose Learned Workload Memory Prediction (LearnedWMP) to improve and simplify estimating the working memory demands of workloads. Through a comprehensive experimental evaluation, we show that LearnedWMP reduces the memory estimation error of the state-of-the-practice method by up to 47.6%. Compared to an alternative single-query model, during training and inferencing, the LearnedWMP model and its variants were 3x to 10x faster. Moreover, LearnedWMP-based models were at least 50% smaller in most cases. Overall, the results demonstrate the advantages of the LearnedWMP approach and its potential for a broader impact on query performance optimization.
RDFFrames: Knowledge Graph Access for Machine Learning Tools
Feb 10, 2020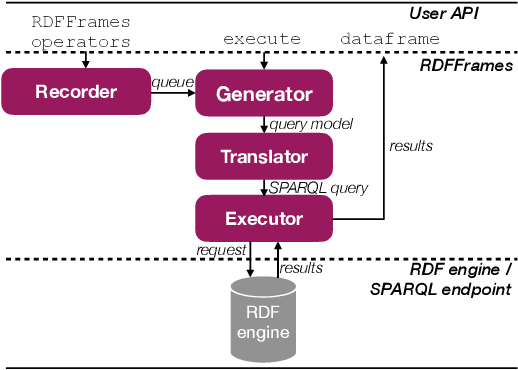

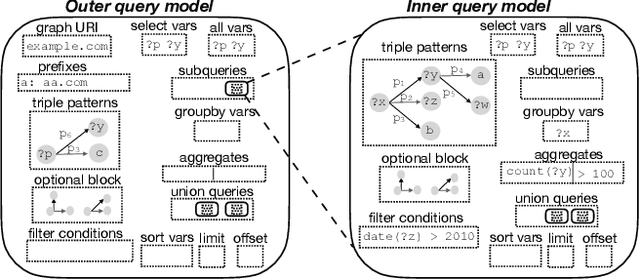
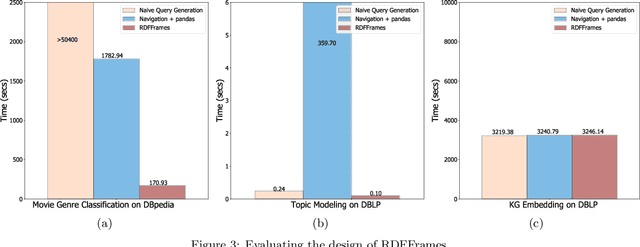
Knowledge graphs represented as RDF datasets are becoming increasingly popular, and they are an integral part of many machine learning applications. A rich ecosystem of data management systems and tools that support RDF has evolved over the years to facilitate high performance storage and retrieval of RDF data, most notably RDF database management systems that support the SPARQL query language. Surprisingly, machine learning tools for knowledge graphs typically do not use SPARQL, despite the obvious advantages of using a database system. This is due to the mismatch between SPARQL and machine learning tools in terms of the expected data model and the programming style. Machine learning tools work on data in tabular format and process it using an imperative programming style, while SPARQL is declarative and has as the basic query operation matching graph patterns to RDF triples. We posit that a good interface to knowledge graphs from a machine learning software stack should use an imperative, navigational programming paradigm based on graph traversal rather than the SPARQL query paradigm based on graph patterns. In this paper, we introduce RDFFrames, a framework that provides such an interface. RDFFrames enables the user to make a sequence of calls in a programming language such as Python to define the data to be extracted from a knowledge graph stored in an RDF database system. It then translates these calls into compact SPQARL queries, executes these queries on the database system, and returns the results in a standard tabular format. Thus, RDFframes combines the usability of a machine learning software stack with the performance of an RDF database system.
Link Prediction via Higher-Order Motif Features
Feb 08, 2019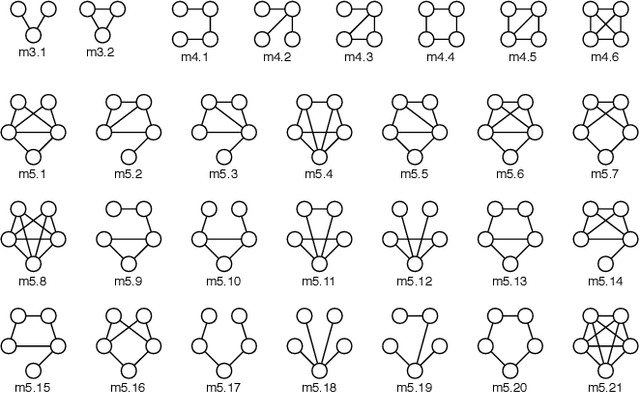
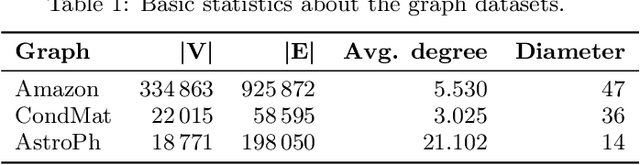
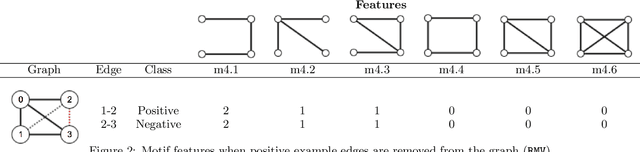

Link prediction requires predicting which new links are likely to appear in a graph. Being able to predict unseen links with good accuracy has important applications in several domains such as social media, security, transportation, and recommendation systems. A common approach is to use features based on the common neighbors of an unconnected pair of nodes to predict whether the pair will form a link in the future. In this paper, we present an approach for link prediction that relies on higher-order analysis of the graph topology, well beyond common neighbors. We treat the link prediction problem as a supervised classification problem, and we propose a set of features that depend on the patterns or motifs that a pair of nodes occurs in. By using motifs of sizes 3, 4, and 5, our approach captures a high level of detail about the graph topology within the neighborhood of the pair of nodes, which leads to a higher classification accuracy. In addition to proposing the use of motif-based features, we also propose two optimizations related to constructing the classification dataset from the graph. First, to ensure that positive and negative examples are treated equally when extracting features, we propose adding the negative examples to the graph as an alternative to the common approach of removing the positive ones. Second, we show that it is important to control for the shortest-path distance when sampling pairs of nodes to form negative examples, since the difficulty of prediction varies with the shortest-path distance. We experimentally demonstrate that using off-the-shelf classifiers with a well constructed classification dataset results in up to 10 percentage points increase in accuracy over prior topology-based and feature learning methods.