 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Perspectivist Social Meaning via Demographic-Conditioned Fusion Embeddings
Jun 05, 2026Social meaning in language is inherently perspectival, varying across annotator backgrounds, demographics, and ideological positions. However, most NLP systems collapse this variation into a single ground-truth label, ignoring the diversity of interpretations. In this work, we model social dimensions along a perspectivist spectrum, capturing how interpretations vary across demographic groups on a dataset consisting of 28k human annotations. We benchmark multiple modeling paradigms, including zero-shot, few-shot, and fine-tuned approaches, and propose fusion embeddings that integrate textual and demographic representations. Our fusion models yield consistent and statistically significant improvements over text-only baselines across all fusion strategies (+5.9-6.5% relative macro PR-AUC), with shuffle ablations confirming that demographic profiles carry genuine predictive signal rather than spurious correlations.
Beyond the Rabbit Hole: Mapping the Relational Harms of QAnon Radicalization
Jan 25, 2026The rise of conspiracy theories has created far-reaching societal harm in the public discourse by eroding trust and fueling polarization. Beyond this public impact lies a deeply personal toll on the friends and families of conspiracy believers, a dimension often overlooked in large-scale computational research. This study fills this gap by systematically mapping radicalization journeys and quantifying the associated emotional toll inflicted on loved ones. We use the prominent case of QAnon as a case study, analyzing 12747 narratives from the r/QAnonCasualties support community through a novel mixed-methods approach. First, we use topic modeling (BERTopic) to map the radicalization trajectories, identifying key pre-existing conditions, triggers, and post-radicalization characteristics. From this, we apply an LDA-based graphical model to uncover six recurring archetypes of QAnon adherents, which we term "radicalization personas." Finally, using LLM-assisted emotion detection and regression modeling, we link these personas to the specific emotional toll reported by narrators. Our findings reveal that these personas are not just descriptive; they are powerful predictors of the specific emotional harms experienced by narrators. Radicalization perceived as a deliberate ideological choice is associated with narrator anger and disgust, while those marked by personal and cognitive collapse are linked to fear and sadness. This work provides the first empirical framework for understanding radicalization as a relational phenomenon, offering a vital roadmap for researchers and practitioners to navigate its interpersonal fallout.
Do Androids Dream of Unseen Puppeteers? Probing for a Conspiracy Mindset in Large Language Models
Nov 05, 2025In this paper, we investigate whether Large Language Models (LLMs) exhibit conspiratorial tendencies, whether they display sociodemographic biases in this domain, and how easily they can be conditioned into adopting conspiratorial perspectives. Conspiracy beliefs play a central role in the spread of misinformation and in shaping distrust toward institutions, making them a critical testbed for evaluating the social fidelity of LLMs. LLMs are increasingly used as proxies for studying human behavior, yet little is known about whether they reproduce higher-order psychological constructs such as a conspiratorial mindset. To bridge this research gap, we administer validated psychometric surveys measuring conspiracy mindset to multiple models under different prompting and conditioning strategies. Our findings reveal that LLMs show partial agreement with elements of conspiracy belief, and conditioning with socio-demographic attributes produces uneven effects, exposing latent demographic biases. Moreover, targeted prompts can easily shift model responses toward conspiratorial directions, underscoring both the susceptibility of LLMs to manipulation and the potential risks of their deployment in sensitive contexts. These results highlight the importance of critically evaluating the psychological dimensions embedded in LLMs, both to advance computational social science and to inform possible mitigation strategies against harmful uses.
Bias and Identifiability in the Bounded Confidence Model
Jun 13, 2025



Opinion dynamics models such as the bounded confidence models (BCMs) describe how a population can reach consensus, fragmentation, or polarization, depending on a few parameters. Connecting such models to real-world data could help understanding such phenomena, testing model assumptions. To this end, estimation of model parameters is a key aspect, and maximum likelihood estimation provides a principled way to tackle it. Here, our goal is to outline the properties of statistical estimators of the two key BCM parameters: the confidence bound and the convergence rate. We find that their maximum likelihood estimators present different characteristics: the one for the confidence bound presents a small-sample bias but is consistent, while the estimator of the convergence rate shows a persistent bias. Moreover, the joint parameter estimation is affected by identifiability issues for specific regions of the parameter space, as several local maxima are present in the likelihood function. Our results show how the analysis of the likelihood function is a fruitful approach for better understanding the pitfalls and possibilities of estimating the parameters of opinion dynamics models, and more in general, agent-based models, and for offering formal guarantees for their calibration.
Alice and the Caterpillar: A more descriptive null model for assessing data mining results
Jun 11, 2025We introduce novel null models for assessing the results obtained from observed binary transactional and sequence datasets, using statistical hypothesis testing. Our null models maintain more properties of the observed dataset than existing ones. Specifically, they preserve the Bipartite Joint Degree Matrix of the bipartite (multi-)graph corresponding to the dataset, which ensures that the number of caterpillars, i.e., paths of length three, is preserved, in addition to other properties considered by other models. We describe Alice, a suite of Markov chain Monte Carlo algorithms for sampling datasets from our null models, based on a carefully defined set of states and efficient operations to move between them. The results of our experimental evaluation show that Alice mixes fast and scales well, and that our null model finds different significant results than ones previously considered in the literature.
Variational Inference of Parameters in Opinion Dynamics Models
Mar 08, 2024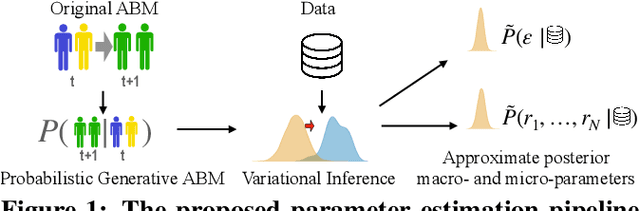
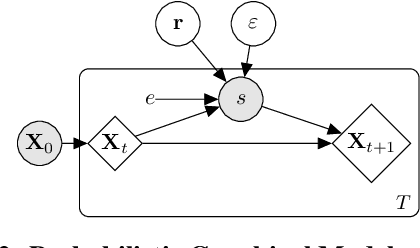
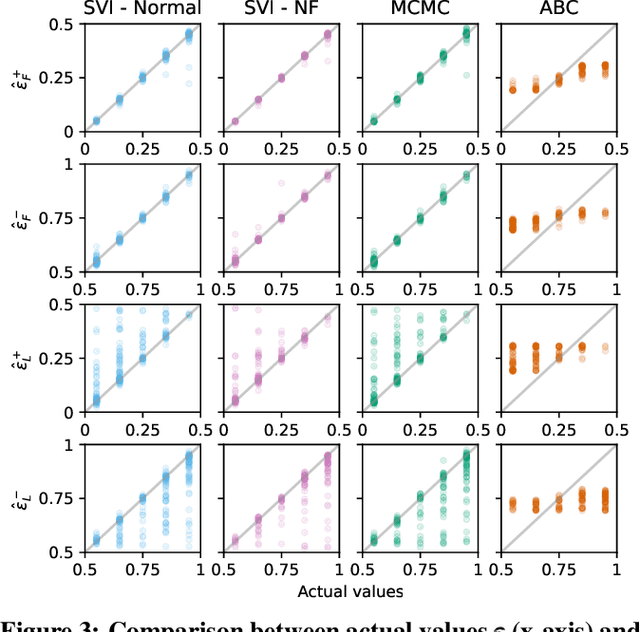
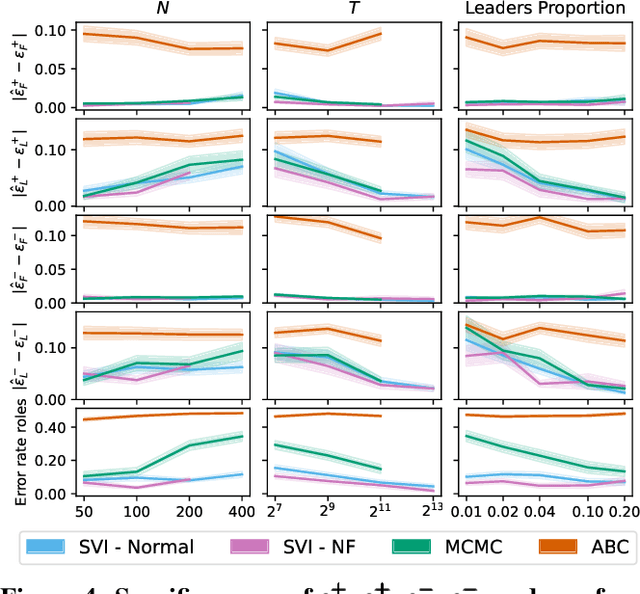
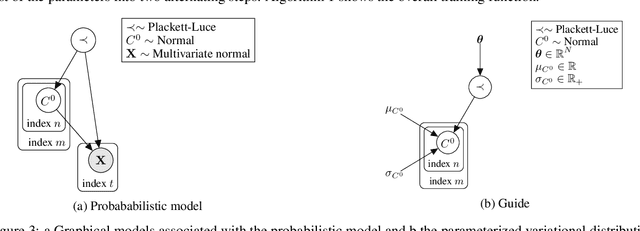
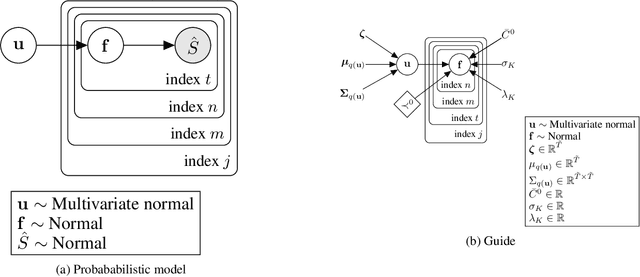
Despite the frequent use of agent-based models (ABMs) for studying social phenomena, parameter estimation remains a challenge, often relying on costly simulation-based heuristics. This work uses variational inference to estimate the parameters of an opinion dynamics ABM, by transforming the estimation problem into an optimization task that can be solved directly. Our proposal relies on probabilistic generative ABMs (PGABMs): we start by synthesizing a probabilistic generative model from the ABM rules. Then, we transform the inference process into an optimization problem suitable for automatic differentiation. In particular, we use the Gumbel-Softmax reparameterization for categorical agent attributes and stochastic variational inference for parameter estimation. Furthermore, we explore the trade-offs of using variational distributions with different complexity: normal distributions and normalizing flows. We validate our method on a bounded confidence model with agent roles (leaders and followers). Our approach estimates both macroscopic (bounded confidence intervals and backfire thresholds) and microscopic ($200$ categorical, agent-level roles) more accurately than simulation-based and MCMC methods. Consequently, our technique enables experts to tune and validate their ABMs against real-world observations, thus providing insights into human behavior in social systems via data-driven analysis.
Extracting the Multiscale Causal Backbone of Brain Dynamics
Oct 31, 2023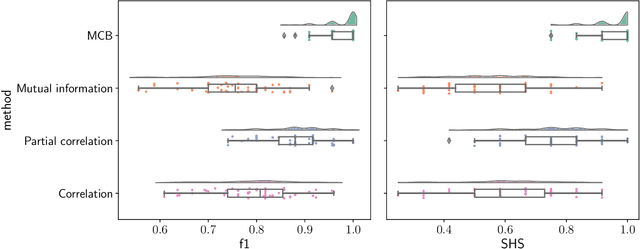
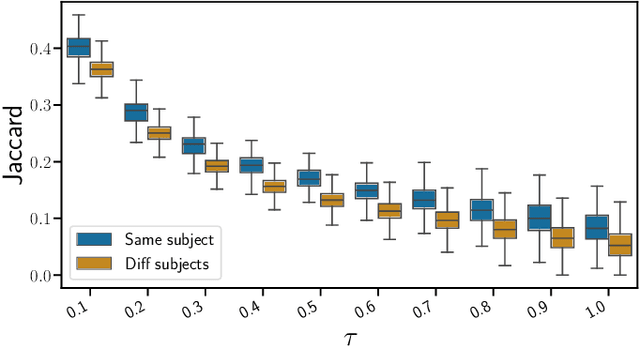
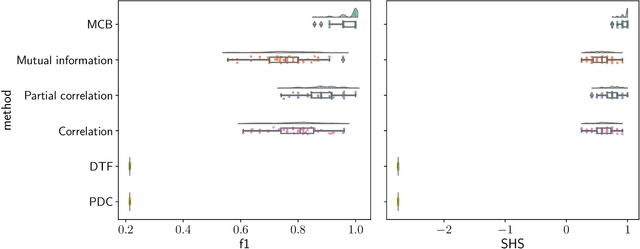
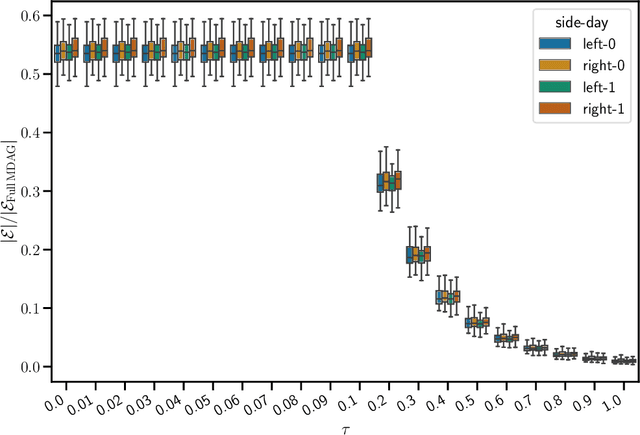
The bulk of the research effort on brain connectivity revolves around statistical associations among brain regions, which do not directly relate to the causal mechanisms governing brain dynamics. Here we propose the multiscale causal backbone (MCB) of brain dynamics shared by a set of individuals across multiple temporal scales, and devise a principled methodology to extract it. Our approach leverages recent advances in multiscale causal structure learning and optimizes the trade-off between the model fitting and its complexity. Empirical assessment on synthetic data shows the superiority of our methodology over a baseline based on canonical functional connectivity networks. When applied to resting-state fMRI data, we find sparse MCBs for both the left and right brain hemispheres. Thanks to its multiscale nature, our approach shows that at low-frequency bands, causal dynamics are driven by brain regions associated with high-level cognitive functions; at higher frequencies instead, nodes related to sensory processing play a crucial role. Finally, our analysis of individual multiscale causal structures confirms the existence of a causal fingerprint of brain connectivity, thus supporting from a causal perspective the existing extensive research in brain connectivity fingerprinting.
Multiscale Non-stationary Causal Structure Learning from Time Series Data
Aug 31, 2022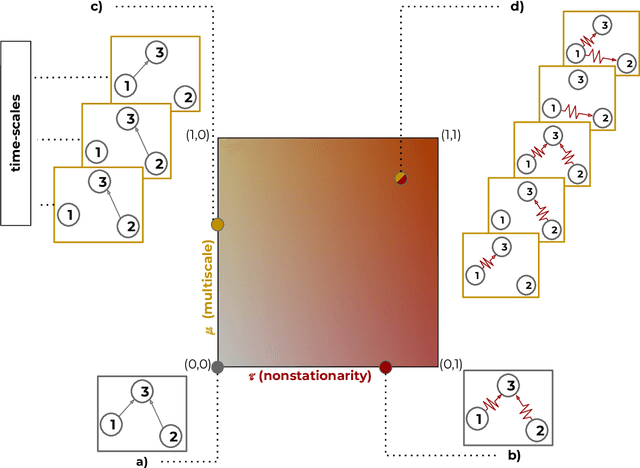
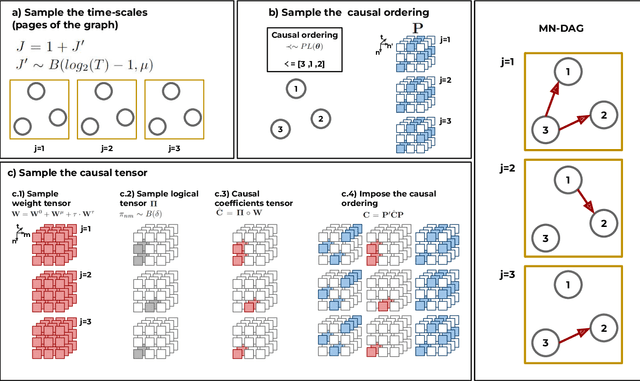
This paper introduces a new type of causal structure, namely multiscale non-stationary directed acyclic graph (MN-DAG), that generalizes DAGs to the time-frequency domain. Our contribution is twofold. First, by leveraging results from spectral and causality theories, we expose a novel probabilistic generative model, which allows to sample an MN-DAG according to user-specified priors concerning the time-dependence and multiscale properties of the causal graph. Second, we devise a Bayesian method for the estimation of MN-DAGs, by means of stochastic variational inference (SVI), called Multiscale Non-Stationary Causal Structure Learner (MN-CASTLE). In addition to direct observations, MN-CASTLE exploits information from the decomposition of the total power spectrum of time series over different time resolutions. In our experiments, we first use the proposed model to generate synthetic data according to a latent MN-DAG, showing that the data generated reproduces well-known features of time series in different domains. Then we compare our learning method MN-CASTLE against baseline models on synthetic data generated with different multiscale and non-stationary settings, confirming the good performance of MN-CASTLE. Finally, we show some insights derived from the application of MN-CASTLE to study the causal structure of 7 global equity markets during the Covid-19 pandemic.
On learning agent-based models from data
May 10, 2022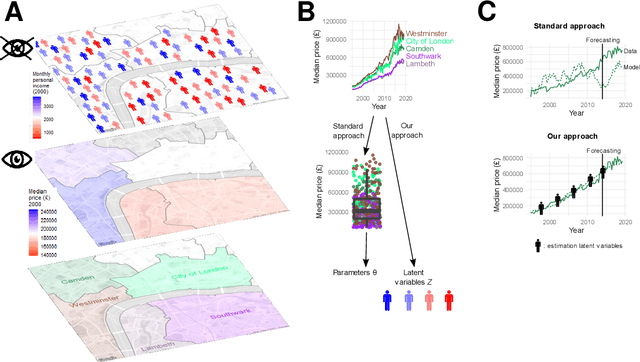
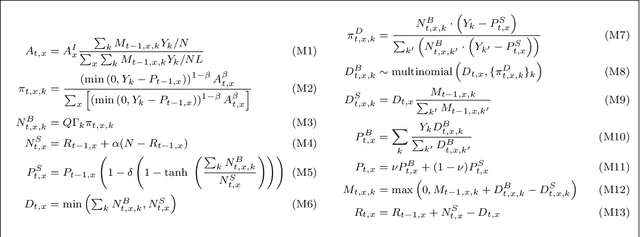
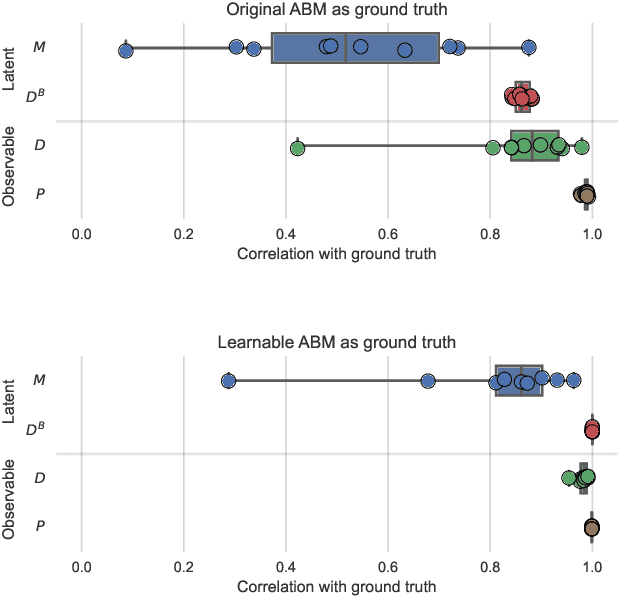
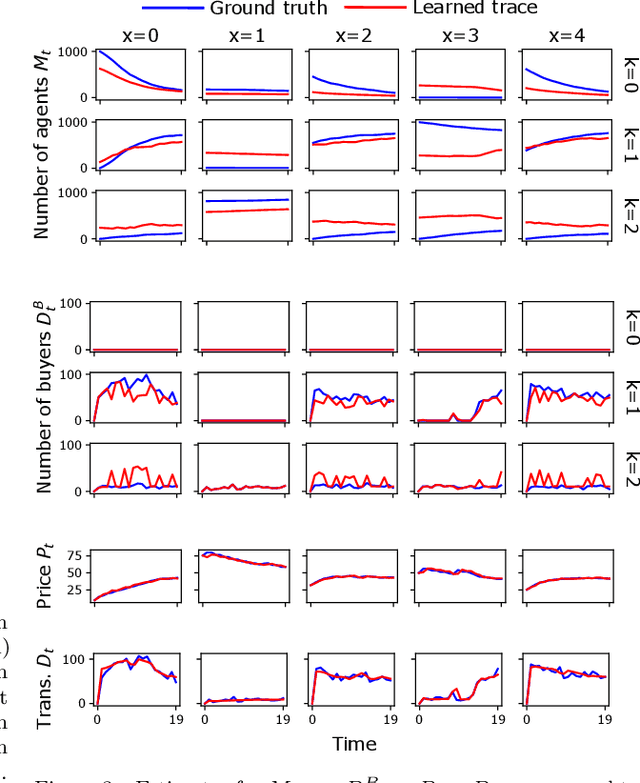
Agent-Based Models (ABMs) are used in several fields to study the evolution of complex systems from micro-level assumptions. However, ABMs typically can not estimate agent-specific (or "micro") variables: this is a major limitation which prevents ABMs from harnessing micro-level data availability and which greatly limits their predictive power. In this paper, we propose a protocol to learn the latent micro-variables of an ABM from data. The first step of our protocol is to reduce an ABM to a probabilistic model, characterized by a computationally tractable likelihood. This reduction follows two general design principles: balance of stochasticity and data availability, and replacement of unobservable discrete choices with differentiable approximations. Then, our protocol proceeds by maximizing the likelihood of the latent variables via a gradient-based expectation maximization algorithm. We demonstrate our protocol by applying it to an ABM of the housing market, in which agents with different incomes bid higher prices to live in high-income neighborhoods. We demonstrate that the obtained model allows accurate estimates of the latent variables, while preserving the general behavior of the ABM. We also show that our estimates can be used for out-of-sample forecasting. Our protocol can be seen as an alternative to black-box data assimilation methods, that forces the modeler to lay bare the assumptions of the model, to think about the inferential process, and to spot potential identification problems.
Learning Opinion Dynamics From Social Traces
Jun 02, 2020
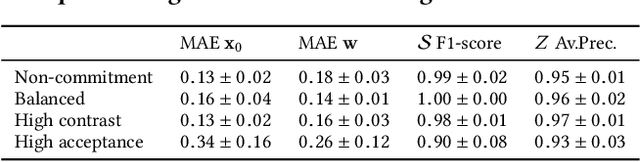
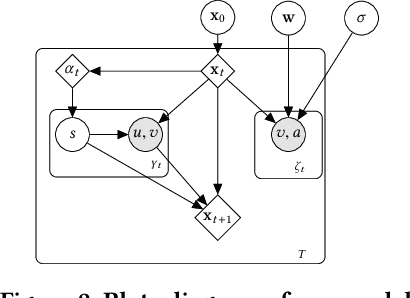
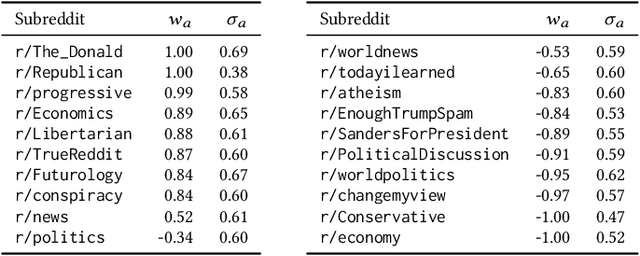
Opinion dynamics - the research field dealing with how people's opinions form and evolve in a social context - traditionally uses agent-based models to validate the implications of sociological theories. These models encode the causal mechanism that drives the opinion formation process, and have the advantage of being easy to interpret. However, as they do not exploit the availability of data, their predictive power is limited. Moreover, parameter calibration and model selection are manual and difficult tasks. In this work we propose an inference mechanism for fitting a generative, agent-like model of opinion dynamics to real-world social traces. Given a set of observables (e.g., actions and interactions between agents), our model can recover the most-likely latent opinion trajectories that are compatible with the assumptions about the process dynamics. This type of model retains the benefits of agent-based ones (i.e., causal interpretation), while adding the ability to perform model selection and hypothesis testing on real data. We showcase our proposal by translating a classical agent-based model of opinion dynamics into its generative counterpart. We then design an inference algorithm based on online expectation maximization to learn the latent parameters of the model. Such algorithm can recover the latent opinion trajectories from traces generated by the classical agent-based model. In addition, it can identify the most likely set of macro parameters used to generate a data trace, thus allowing testing of sociological hypotheses. Finally, we apply our model to real-world data from Reddit to explore the long-standing question about the impact of backfire effect. Our results suggest a low prominence of the effect in Reddit's political conversation.
* Published at KDD2020