 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting the Role of Political Trolls in Social Media
Oct 04, 2019
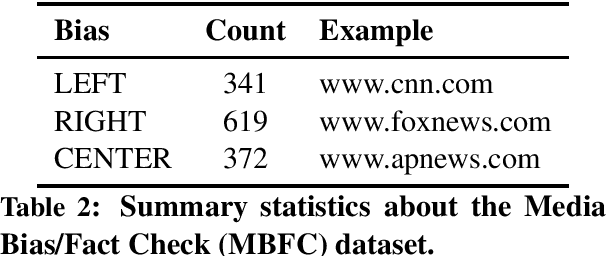
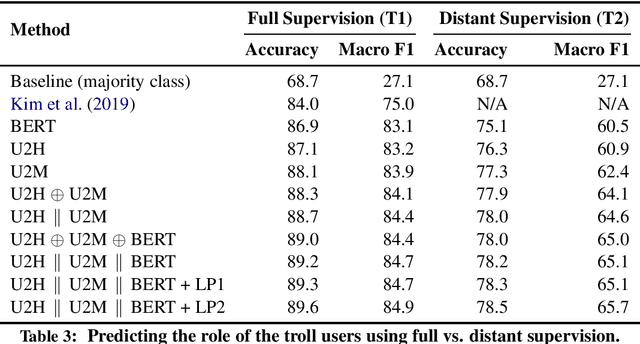
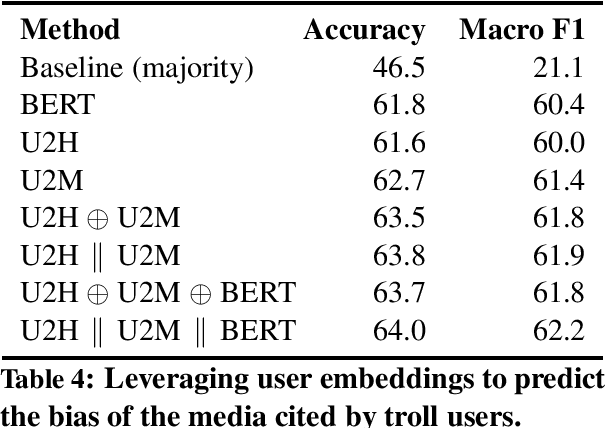
We investigate the political roles of "Internet trolls" in social media. Political trolls, such as the ones linked to the Russian Internet Research Agency (IRA), have recently gained enormous attention for their ability to sway public opinion and even influence elections. Analysis of the online traces of trolls has shown different behavioral patterns, which target different slices of the population. However, this analysis is manual and labor-intensive, thus making it impractical as a first-response tool for newly-discovered troll farms. In this paper, we show how to automate this analysis by using machine learning in a realistic setting. In particular, we show how to classify trolls according to their political role ---left, news feed, right--- by using features extracted from social media, i.e., Twitter, in two scenarios: (i) in a traditional supervised learning scenario, where labels for trolls are available, and (ii) in a distant supervision scenario, where labels for trolls are not available, and we rely on more-commonly-available labels for news outlets mentioned by the trolls. Technically, we leverage the community structure and the text of the messages in the online social network of trolls represented as a graph, from which we extract several types of learned representations, i.e.,~embeddings, for the trolls. Experiments on the "IRA Russian Troll" dataset show that our methodology improves over the state-of-the-art in the first scenario, while providing a compelling case for the second scenario, which has not been explored in the literature thus far.
Recursive Style Breach Detection with Multifaceted Ensemble Learning
Jun 17, 2019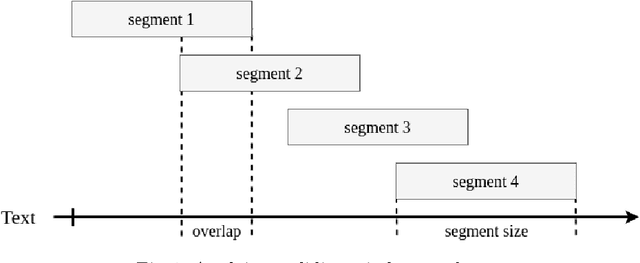

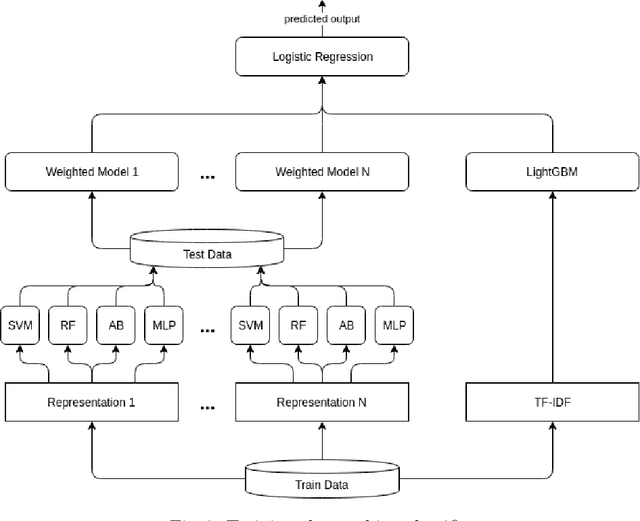
We present a supervised approach for style change detection, which aims at predicting whether there are changes in the style in a given text document, as well as at finding the exact positions where such changes occur. In particular, we combine a TF.IDF representation of the document with features specifically engineered for the task, and we make predictions via an ensemble of diverse classifiers including SVM, Random Forest, AdaBoost, MLP, and LightGBM. Whenever the model detects that style change is present, we apply it recursively, looking to find the specific positions of the change. Our approach powered the winning system for the PAN@CLEF 2018 task on Style Change Detection.
Resolving Gendered Ambiguous Pronouns with BERT
Jun 13, 2019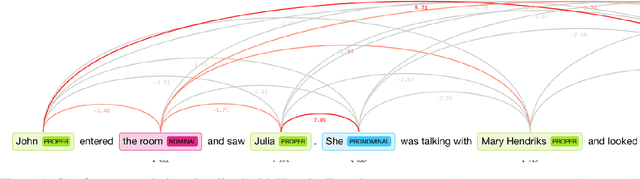
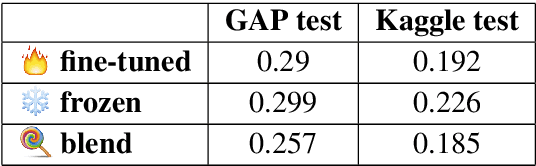


Pronoun resolution is part of coreference resolution, the task of pairing an expression to its referring entity. This is an important task for natural language understanding and a necessary component of machine translation systems, chat bots and assistants. Neural machine learning systems perform far from ideally in this task, reaching as low as 73% F1 scores on modern benchmark datasets. Moreover, they tend to perform better for masculine pronouns than for feminine ones. Thus, the problem is both challenging and important for NLP researchers and practitioners. In this project, we describe our BERT-based approach to solving the problem of gender-balanced pronoun resolution. We are able to reach 92% F1 score and a much lower gender bias on the benchmark dataset shared by Google AI Language team.
Deploying AI Frameworks on Secure HPC Systems with Containers
May 24, 2019

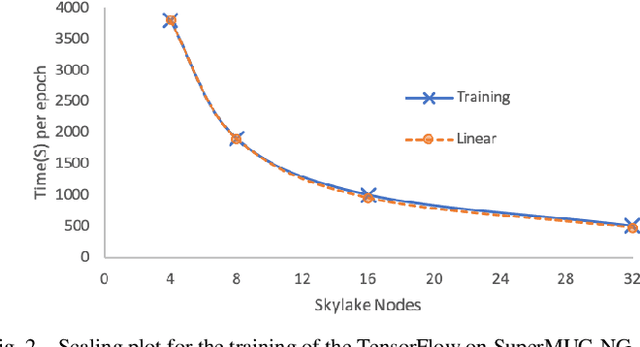
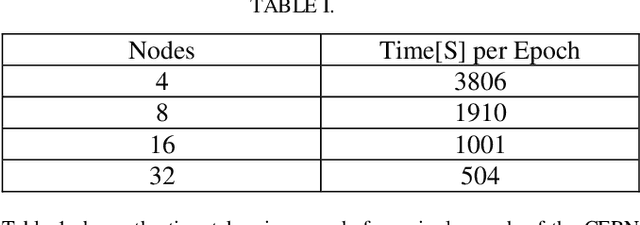
The increasing interest in the usage of Artificial Intelligence techniques (AI) from the research community and industry to tackle "real world" problems, requires High Performance Computing (HPC) resources to efficiently compute and scale complex algorithms across thousands of nodes. Unfortunately, typical data scientists are not familiar with the unique requirements and characteristics of HPC environments. They usually develop their applications with high-level scripting languages or frameworks such as TensorFlow and the installation process often requires connection to external systems to download open source software during the build. HPC environments, on the other hand, are often based on closed source applications that incorporate parallel and distributed computing API's such as MPI and OpenMP, while users have restricted administrator privileges, and face security restrictions such as not allowing access to external systems. In this paper we discuss the issues associated with the deployment of AI frameworks in a secure HPC environment and how we successfully deploy AI frameworks on SuperMUC-NG with Charliecloud.