 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantum Computing for Large-scale Network Optimization: Opportunities and Challenges
Sep 09, 2025The complexity of large-scale 6G-and-beyond networks demands innovative approaches for multi-objective optimization over vast search spaces, a task often intractable. Quantum computing (QC) emerges as a promising technology for efficient large-scale optimization. We present our vision of leveraging QC to tackle key classes of problems in future mobile networks. By analyzing and identifying common features, particularly their graph-centric representation, we propose a unified strategy involving QC algorithms. Specifically, we outline a methodology for optimization using quantum annealing as well as quantum reinforcement learning. Additionally, we discuss the main challenges that QC algorithms and hardware must overcome to effectively optimize future networks.
Guided Graph Compression for Quantum Graph Neural Networks
Jun 11, 2025



Graph Neural Networks (GNNs) are effective for processing graph-structured data but face challenges with large graphs due to high memory requirements and inefficient sparse matrix operations on GPUs. Quantum Computing (QC) offers a promising avenue to address these issues and inspires new algorithmic approaches. In particular, Quantum Graph Neural Networks (QGNNs) have been explored in recent literature. However, current quantum hardware limits the dimension of the data that can be effectively encoded. Existing approaches either simplify datasets manually or use artificial graph datasets. This work introduces the Guided Graph Compression (GGC) framework, which uses a graph autoencoder to reduce both the number of nodes and the dimensionality of node features. The compression is guided to enhance the performance of a downstream classification task, which can be applied either with a quantum or a classical classifier. The framework is evaluated on the Jet Tagging task, a classification problem of fundamental importance in high energy physics that involves distinguishing particle jets initiated by quarks from those by gluons. The GGC is compared against using the autoencoder as a standalone preprocessing step and against a baseline classical GNN classifier. Our numerical results demonstrate that GGC outperforms both alternatives, while also facilitating the testing of novel QGNN ansatzes on realistic datasets.
CaloChallenge 2022: A Community Challenge for Fast Calorimeter Simulation
Oct 28, 2024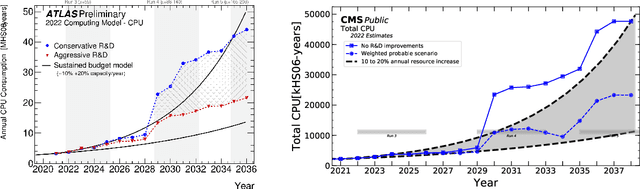
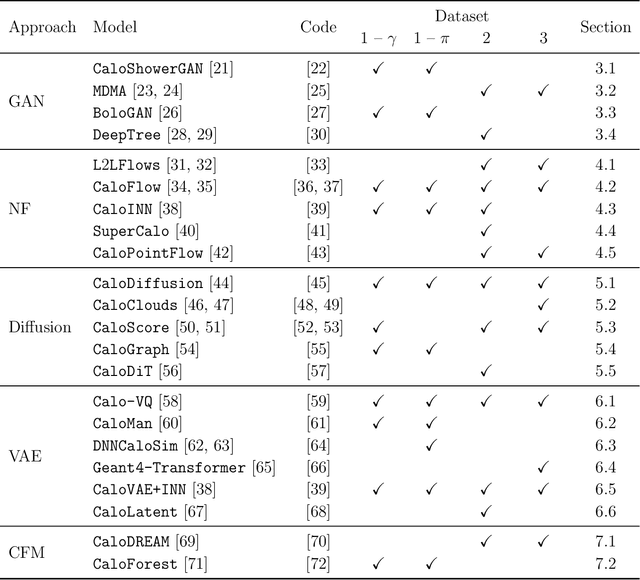
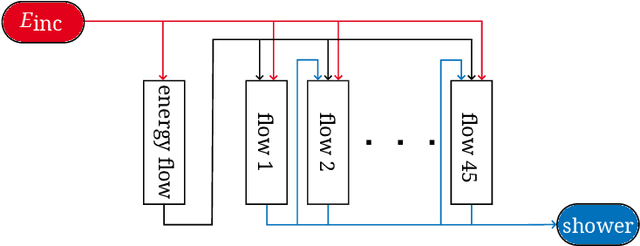
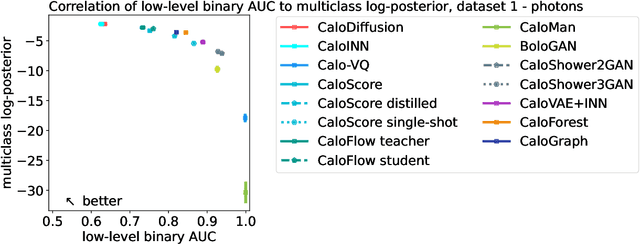
We present the results of the "Fast Calorimeter Simulation Challenge 2022" - the CaloChallenge. We study state-of-the-art generative models on four calorimeter shower datasets of increasing dimensionality, ranging from a few hundred voxels to a few tens of thousand voxels. The 31 individual submissions span a wide range of current popular generative architectures, including Variational AutoEncoders (VAEs), Generative Adversarial Networks (GANs), Normalizing Flows, Diffusion models, and models based on Conditional Flow Matching. We compare all submissions in terms of quality of generated calorimeter showers, as well as shower generation time and model size. To assess the quality we use a broad range of different metrics including differences in 1-dimensional histograms of observables, KPD/FPD scores, AUCs of binary classifiers, and the log-posterior of a multiclass classifier. The results of the CaloChallenge provide the most complete and comprehensive survey of cutting-edge approaches to calorimeter fast simulation to date. In addition, our work provides a uniquely detailed perspective on the important problem of how to evaluate generative models. As such, the results presented here should be applicable for other domains that use generative AI and require fast and faithful generation of samples in a large phase space.
Guided Quantum Compression for Higgs Identification
Feb 14, 2024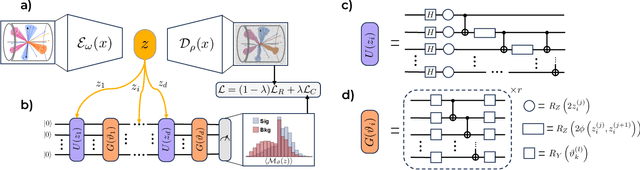
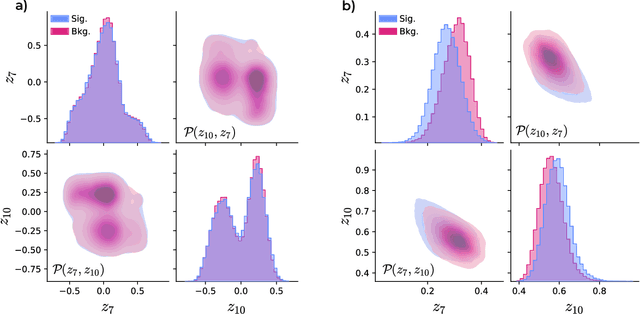
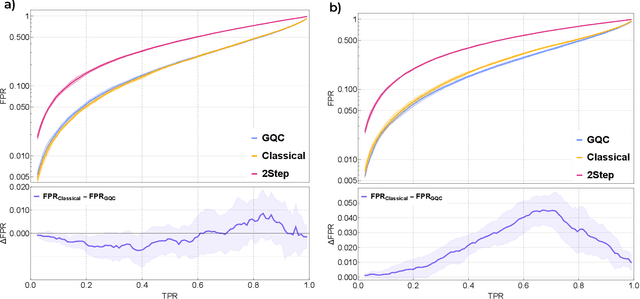

Quantum machine learning provides a fundamentally novel and promising approach to analyzing data. However, many data sets are too complex for currently available quantum computers. Consequently, quantum machine learning applications conventionally resort to dimensionality reduction algorithms, e.g., auto-encoders, before passing data through the quantum models. We show that using a classical auto-encoder as an independent preprocessing step can significantly decrease the classification performance of a quantum machine learning algorithm. To ameliorate this issue, we design an architecture that unifies the preprocessing and quantum classification algorithms into a single trainable model: the guided quantum compression model. The utility of this model is demonstrated by using it to identify the Higgs boson in proton-proton collisions at the LHC, where the conventional approach proves ineffective. Conversely, the guided quantum compression model excels at solving this classification problem, achieving a good accuracy. Additionally, the model developed herein shows better performance compared to the classical benchmark when using only low-level kinematic features.
Symmetry breaking in geometric quantum machine learning in the presence of noise
Jan 17, 2024Geometric quantum machine learning based on equivariant quantum neural networks (EQNN) recently appeared as a promising direction in quantum machine learning. Despite the encouraging progress, the studies are still limited to theory, and the role of hardware noise in EQNN training has never been explored. This work studies the behavior of EQNN models in the presence of noise. We show that certain EQNN models can preserve equivariance under Pauli channels, while this is not possible under the amplitude damping channel. We claim that the symmetry breaking grows linearly in the number of layers and noise strength. We support our claims with numerical data from simulations as well as hardware up to 64 qubits. Furthermore, we provide strategies to enhance the symmetry protection of EQNN models in the presence of noise.
Approximately Equivariant Quantum Neural Network for $p4m$ Group Symmetries in Images
Oct 03, 2023



Quantum Neural Networks (QNNs) are suggested as one of the quantum algorithms which can be efficiently simulated with a low depth on near-term quantum hardware in the presence of noises. However, their performance highly relies on choosing the most suitable architecture of Variational Quantum Algorithms (VQAs), and the problem-agnostic models often suffer issues regarding trainability and generalization power. As a solution, the most recent works explore Geometric Quantum Machine Learning (GQML) using QNNs equivariant with respect to the underlying symmetry of the dataset. GQML adds an inductive bias to the model by incorporating the prior knowledge on the given dataset and leads to enhancing the optimization performance while constraining the search space. This work proposes equivariant Quantum Convolutional Neural Networks (EquivQCNNs) for image classification under planar $p4m$ symmetry, including reflectional and $90^\circ$ rotational symmetry. We present the results tested in different use cases, such as phase detection of the 2D Ising model and classification of the extended MNIST dataset, and compare them with those obtained with the non-equivariant model, proving that the equivariance fosters better generalization of the model.
Hybrid Ground-State Quantum Algorithms based on Neural Schrödinger Forging
Jul 05, 2023



Entanglement forging based variational algorithms leverage the bi-partition of quantum systems for addressing ground state problems. The primary limitation of these approaches lies in the exponential summation required over the numerous potential basis states, or bitstrings, when performing the Schmidt decomposition of the whole system. To overcome this challenge, we propose a new method for entanglement forging employing generative neural networks to identify the most pertinent bitstrings, eliminating the need for the exponential sum. Through empirical demonstrations on systems of increasing complexity, we show that the proposed algorithm achieves comparable or superior performance compared to the existing standard implementation of entanglement forging. Moreover, by controlling the amount of required resources, this scheme can be applied to larger, as well as non permutation invariant systems, where the latter constraint is associated with the Heisenberg forging procedure. We substantiate our findings through numerical simulations conducted on spins models exhibiting one-dimensional ring, two-dimensional triangular lattice topologies, and nuclear shell model configurations.
Assessment of few-hits machine learning classification algorithms for low energy physics in liquid argon detectors
May 16, 2023
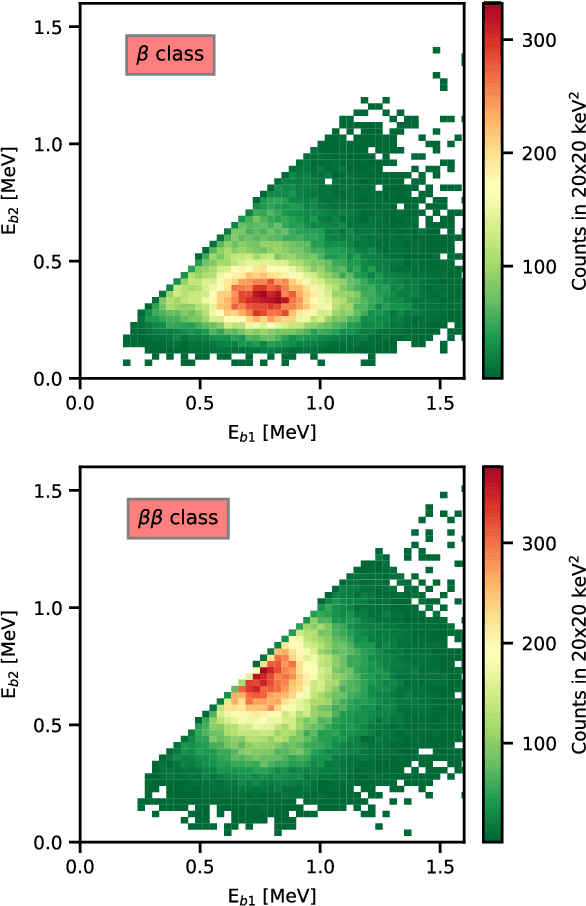


The physics potential of massive liquid argon TPCs in the low-energy regime is still to be fully reaped because few-hits events encode information that can hardly be exploited by conventional classification algorithms. Machine learning (ML) techniques give their best in these types of classification problems. In this paper, we evaluate their performance against conventional (deterministic) algorithms. We demonstrate that both Convolutional Neural Networks (CNN) and Transformer-Encoder methods outperform deterministic algorithms in one of the most challenging classification problems of low-energy physics (single- versus double-beta events). We discuss the advantages and pitfalls of Transformer-Encoder methods versus CNN and employ these methods to optimize the detector parameters, with an emphasis on the DUNE Phase II detectors ("Module of Opportunity").
Trainability barriers and opportunities in quantum generative modeling
May 04, 2023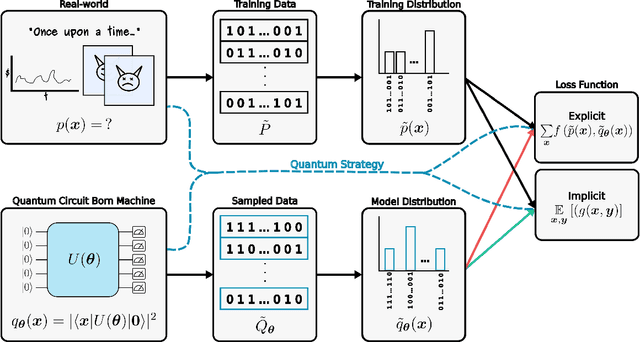
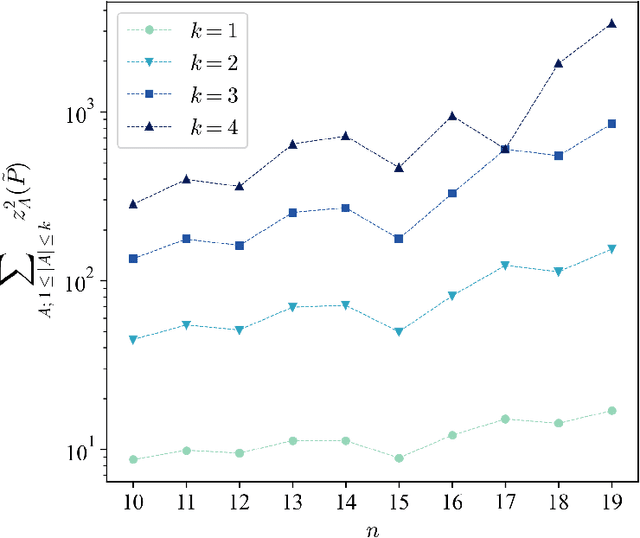
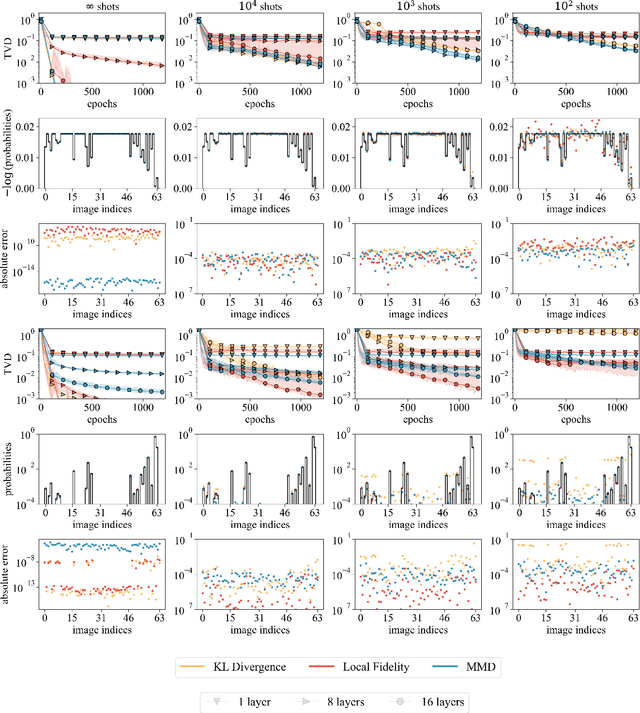
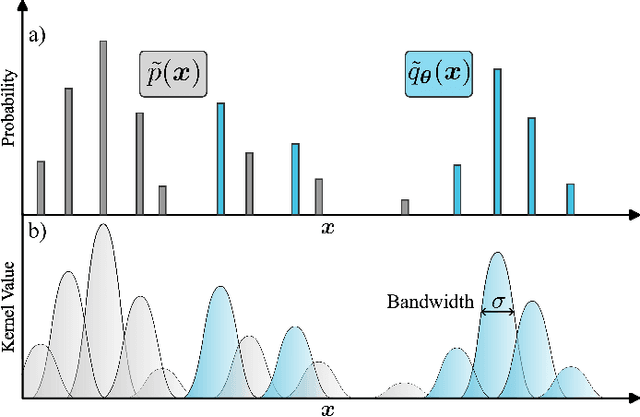
Quantum generative models, in providing inherently efficient sampling strategies, show promise for achieving a near-term advantage on quantum hardware. Nonetheless, important questions remain regarding their scalability. In this work, we investigate the barriers to the trainability of quantum generative models posed by barren plateaus and exponential loss concentration. We explore the interplay between explicit and implicit models and losses, and show that using implicit generative models (such as quantum circuit-based models) with explicit losses (such as the KL divergence) leads to a new flavour of barren plateau. In contrast, the Maximum Mean Discrepancy (MMD), which is a popular example of an implicit loss, can be viewed as the expectation value of an observable that is either low-bodied and trainable, or global and untrainable depending on the choice of kernel. However, in parallel, we highlight that the low-bodied losses required for trainability cannot in general distinguish high-order correlations, leading to a fundamental tension between exponential concentration and the emergence of spurious minima. We further propose a new local quantum fidelity-type loss which, by leveraging quantum circuits to estimate the quality of the encoded distribution, is both faithful and enjoys trainability guarantees. Finally, we compare the performance of different loss functions for modelling real-world data from the High-Energy-Physics domain and confirm the trends predicted by our theoretical results.
Unravelling physics beyond the standard model with classical and quantum anomaly detection
Jan 27, 2023Much hope for finding new physics phenomena at microscopic scale relies on the observations obtained from High Energy Physics experiments, like the ones performed at the Large Hadron Collider (LHC). However, current experiments do not indicate clear signs of new physics that could guide the development of additional Beyond Standard Model (BSM) theories. Identifying signatures of new physics out of the enormous amount of data produced at the LHC falls into the class of anomaly detection and constitutes one of the greatest computational challenges. In this article, we propose a novel strategy to perform anomaly detection in a supervised learning setting, based on the artificial creation of anomalies through a random process. For the resulting supervised learning problem, we successfully apply classical and quantum Support Vector Classifiers (CSVC and QSVC respectively) to identify the artificial anomalies among the SM events. Even more promising, we find that employing an SVC trained to identify the artificial anomalies, it is possible to identify realistic BSM events with high accuracy. In parallel, we also explore the potential of quantum algorithms for improving the classification accuracy and provide plausible conditions for the best exploitation of this novel computational paradigm.