 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIQP Born Machines under Data-dependent and Agnostic Initialization Strategies
Mar 15, 2026Quantum circuit Born machines based on instantaneous quantum polynomial-time (IQP) circuits are natural candidates for quantum generative modeling, both because of their probabilistic structure and because IQP sampling is provably classically hard in certain regimes. Recent proposals focus on training IQP-QCBMs using Maximum Mean Discrepancy (MMD) losses built from low-body Pauli-$Z$ correlators, but the effect of initialization on the resulting optimization landscape remains poorly understood. In this work, we address this by first proving that the MMD loss landscape suffers from barren plateaus for random full-angle-range initializations of IQP circuits. We then establish lower bounds on the loss variance for identity and an unbiased data-agnostic initialization. We then additionally consider a data-dependent initialization that is better aligned with the target distribution and, under suitable assumptions, yields provable gradients and generally converges quicker to a good minimum (as indicated by our training of circuits with 150 qubits on genomic data). Finally, as a by-product, the developed variance lower bound framework is applicable to a general class of non-linear losses, offering a broader toolset for analyzing warm-starts in quantum machine learning.
A unifying account of warm start guarantees for patches of quantum landscapes
Feb 11, 2025Barren plateaus are fundamentally a statement about quantum loss landscapes on average but there can, and generally will, exist patches of barren plateau landscapes with substantial gradients. Previous work has studied certain classes of parameterized quantum circuits and found example regions where gradients vanish at worst polynomially in system size. Here we present a general bound that unifies all these previous cases and that can tackle physically-motivated ans\"atze that could not be analyzed previously. Concretely, we analytically prove a lower-bound on the variance of the loss that can be used to show that in a non-exponentially narrow region around a point with curvature the loss variance cannot decay exponentially fast. This result is complemented by numerics and an upper-bound that suggest that any loss function with a barren plateau will have exponentially vanishing gradients in any constant radius subregion. Our work thus suggests that while there are hopes to be able to warm-start variational quantum algorithms, any initialization strategy that cannot get increasingly close to the region of attraction with increasing problem size is likely inadequate.
Efficient quantum-enhanced classical simulation for patches of quantum landscapes
Nov 29, 2024



Understanding the capabilities of classical simulation methods is key to identifying where quantum computers are advantageous. Not only does this ensure that quantum computers are used only where necessary, but also one can potentially identify subroutines that can be offloaded onto a classical device. In this work, we show that it is always possible to generate a classical surrogate of a sub-region (dubbed a "patch") of an expectation landscape produced by a parameterized quantum circuit. That is, we provide a quantum-enhanced classical algorithm which, after simple measurements on a quantum device, allows one to classically simulate approximate expectation values of a subregion of a landscape. We provide time and sample complexity guarantees for a range of families of circuits of interest, and further numerically demonstrate our simulation algorithms on an exactly verifiable simulation of a Hamiltonian variational ansatz and long-time dynamics simulation on a 127-qubit heavy-hex topology.
Trainability barriers and opportunities in quantum generative modeling
May 04, 2023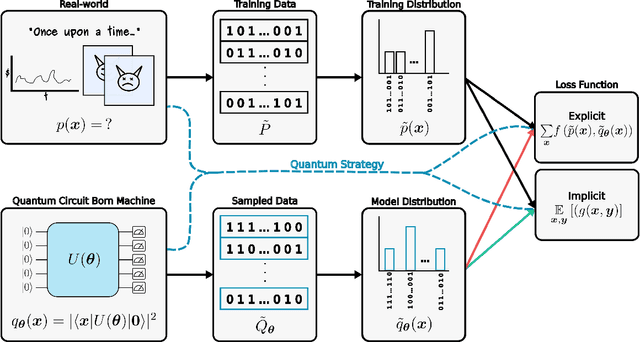
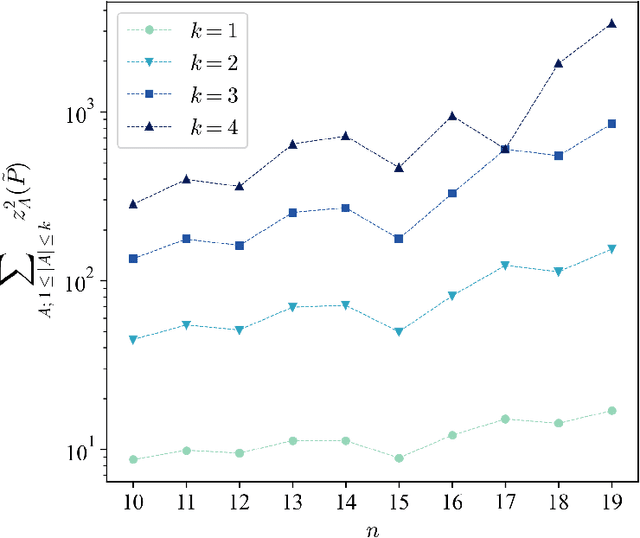
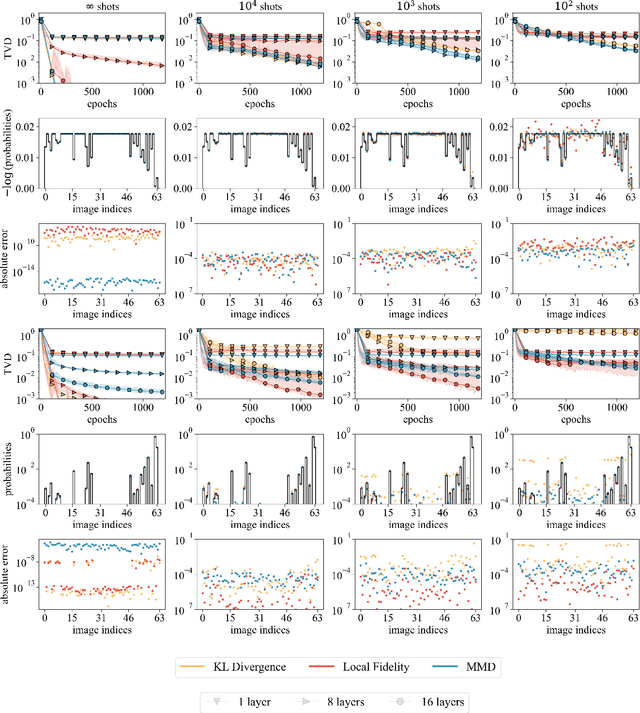
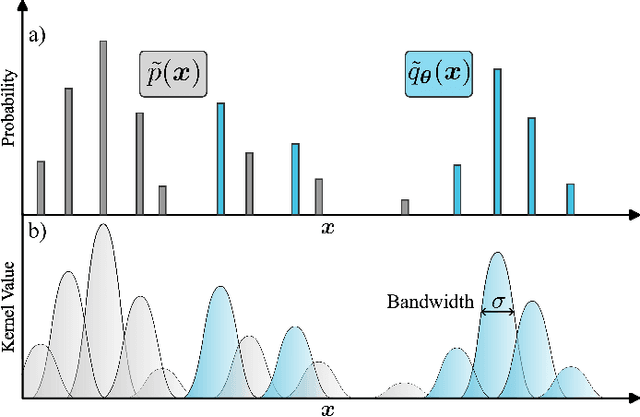
Quantum generative models, in providing inherently efficient sampling strategies, show promise for achieving a near-term advantage on quantum hardware. Nonetheless, important questions remain regarding their scalability. In this work, we investigate the barriers to the trainability of quantum generative models posed by barren plateaus and exponential loss concentration. We explore the interplay between explicit and implicit models and losses, and show that using implicit generative models (such as quantum circuit-based models) with explicit losses (such as the KL divergence) leads to a new flavour of barren plateau. In contrast, the Maximum Mean Discrepancy (MMD), which is a popular example of an implicit loss, can be viewed as the expectation value of an observable that is either low-bodied and trainable, or global and untrainable depending on the choice of kernel. However, in parallel, we highlight that the low-bodied losses required for trainability cannot in general distinguish high-order correlations, leading to a fundamental tension between exponential concentration and the emergence of spurious minima. We further propose a new local quantum fidelity-type loss which, by leveraging quantum circuits to estimate the quality of the encoded distribution, is both faithful and enjoys trainability guarantees. Finally, we compare the performance of different loss functions for modelling real-world data from the High-Energy-Physics domain and confirm the trends predicted by our theoretical results.