 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRole of scrambling and noise in temporal information processing with quantum systems
May 15, 2025Scrambling quantum systems have been demonstrated as effective substrates for temporal information processing. While their role in providing rich feature maps has been widely studied, a theoretical understanding of their performance in temporal tasks is still lacking. Here we consider a general quantum reservoir processing framework that captures a broad range of physical computing models with quantum systems. We examine the scalability and memory retention of the model with scrambling reservoirs modelled by high-order unitary designs in both noiseless and noisy settings. In the former regime, we show that measurement readouts become exponentially concentrated with increasing reservoir size, yet strikingly do not worsen with the reservoir iterations. Thus, while repeatedly reusing a small scrambling reservoir with quantum data might be viable, scaling up the problem size deteriorates generalization unless one can afford an exponential shot overhead. In contrast, the memory of early inputs and initial states decays exponentially in both reservoir size and reservoir iterations. In the noisy regime, we also prove exponential memory decays with iterations for local noisy channels. Proving these results required us to introduce new proof techniques for bounding concentration in temporal quantum learning models.
A unifying account of warm start guarantees for patches of quantum landscapes
Feb 11, 2025Barren plateaus are fundamentally a statement about quantum loss landscapes on average but there can, and generally will, exist patches of barren plateau landscapes with substantial gradients. Previous work has studied certain classes of parameterized quantum circuits and found example regions where gradients vanish at worst polynomially in system size. Here we present a general bound that unifies all these previous cases and that can tackle physically-motivated ans\"atze that could not be analyzed previously. Concretely, we analytically prove a lower-bound on the variance of the loss that can be used to show that in a non-exponentially narrow region around a point with curvature the loss variance cannot decay exponentially fast. This result is complemented by numerics and an upper-bound that suggest that any loss function with a barren plateau will have exponentially vanishing gradients in any constant radius subregion. Our work thus suggests that while there are hopes to be able to warm-start variational quantum algorithms, any initialization strategy that cannot get increasingly close to the region of attraction with increasing problem size is likely inadequate.
Efficient quantum-enhanced classical simulation for patches of quantum landscapes
Nov 29, 2024



Understanding the capabilities of classical simulation methods is key to identifying where quantum computers are advantageous. Not only does this ensure that quantum computers are used only where necessary, but also one can potentially identify subroutines that can be offloaded onto a classical device. In this work, we show that it is always possible to generate a classical surrogate of a sub-region (dubbed a "patch") of an expectation landscape produced by a parameterized quantum circuit. That is, we provide a quantum-enhanced classical algorithm which, after simple measurements on a quantum device, allows one to classically simulate approximate expectation values of a subregion of a landscape. We provide time and sample complexity guarantees for a range of families of circuits of interest, and further numerically demonstrate our simulation algorithms on an exactly verifiable simulation of a Hamiltonian variational ansatz and long-time dynamics simulation on a 127-qubit heavy-hex topology.
Exact gradients for linear optics with single photons
Sep 24, 2024Though parameter shift rules have drastically improved gradient estimation methods for several types of quantum circuits, leading to improved performance in downstream tasks, so far they have not been transferable to linear optics with single photons. In this work, we derive an analytical formula for the gradients in these circuits with respect to phaseshifters via a generalized parameter shift rule, where the number of parameter shifts depends linearly on the total number of photons. Experimentally, this enables access to derivatives in photonic systems without the need for finite difference approximations. Building on this, we propose two strategies through which one can reduce the number of shifts in the expression, and hence reduce the overall sample complexity. Numerically, we show that this generalized parameter-shift rule can converge to the minimum of a cost function with fewer parameter update steps than alternative techniques. We anticipate that this method will open up new avenues to solving optimization problems with photonic systems, as well as provide new techniques for the experimental characterization and control of linear optical systems.
Quantum Convolutional Neural Networks are (Effectively) Classically Simulable
Aug 22, 2024Quantum Convolutional Neural Networks (QCNNs) are widely regarded as a promising model for Quantum Machine Learning (QML). In this work we tie their heuristic success to two facts. First, that when randomly initialized, they can only operate on the information encoded in low-bodyness measurements of their input states. And second, that they are commonly benchmarked on "locally-easy'' datasets whose states are precisely classifiable by the information encoded in these low-bodyness observables subspace. We further show that the QCNN's action on this subspace can be efficiently classically simulated by a classical algorithm equipped with Pauli shadows on the dataset. Indeed, we present a shadow-based simulation of QCNNs on up-to $1024$ qubits for phases of matter classification. Our results can then be understood as highlighting a deeper symptom of QML: Models could only be showing heuristic success because they are benchmarked on simple problems, for which their action can be classically simulated. This insight points to the fact that non-trivial datasets are a truly necessary ingredient for moving forward with QML. To finish, we discuss how our results can be extrapolated to classically simulate other architectures.
A Review of Barren Plateaus in Variational Quantum Computing
May 01, 2024Variational quantum computing offers a flexible computational paradigm with applications in diverse areas. However, a key obstacle to realizing their potential is the Barren Plateau (BP) phenomenon. When a model exhibits a BP, its parameter optimization landscape becomes exponentially flat and featureless as the problem size increases. Importantly, all the moving pieces of an algorithm -- choices of ansatz, initial state, observable, loss function and hardware noise -- can lead to BPs when ill-suited. Due to the significant impact of BPs on trainability, researchers have dedicated considerable effort to develop theoretical and heuristic methods to understand and mitigate their effects. As a result, the study of BPs has become a thriving area of research, influencing and cross-fertilizing other fields such as quantum optimal control, tensor networks, and learning theory. This article provides a comprehensive review of the current understanding of the BP phenomenon.
Variational quantum simulation: a case study for understanding warm starts
Apr 15, 2024
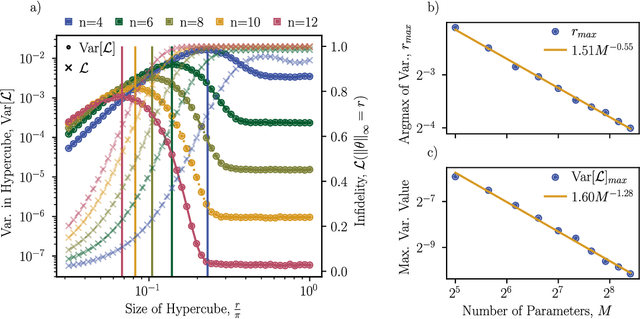
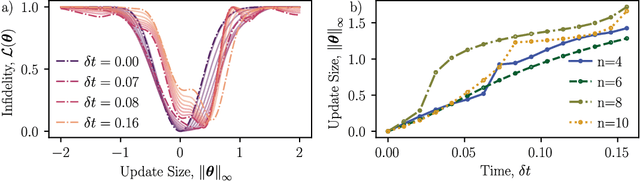
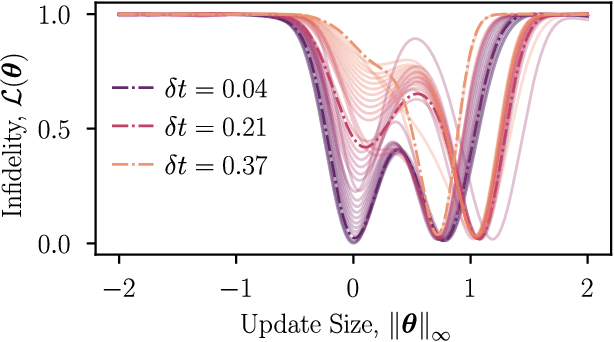
The barren plateau phenomenon, characterized by loss gradients that vanish exponentially with system size, poses a challenge to scaling variational quantum algorithms. Here we explore the potential of warm starts, whereby one initializes closer to a solution in the hope of enjoying larger loss variances. Focusing on an iterative variational method for learning shorter-depth circuits for quantum real and imaginary time evolution we conduct a case study to elucidate the potential and limitations of warm starts. We start by proving that the iterative variational algorithm will exhibit substantial (at worst vanishing polynomially in system size) gradients in a small region around the initializations at each time-step. Convexity guarantees for these regions are then established, suggesting trainability for polynomial size time-steps. However, our study highlights scenarios where a good minimum shifts outside the region with trainability guarantees. Our analysis leaves open the question whether such minima jumps necessitate optimization across barren plateau landscapes or whether there exist gradient flows, i.e., fertile valleys away from the plateau with substantial gradients, that allow for training.
On fundamental aspects of quantum extreme learning machines
Dec 23, 2023Quantum Extreme Learning Machines (QELMs) have emerged as a promising framework for quantum machine learning. Their appeal lies in the rich feature map induced by the dynamics of a quantum substrate - the quantum reservoir - and the efficient post-measurement training via linear regression. Here we study the expressivity of QELMs by decomposing the prediction of QELMs into a Fourier series. We show that the achievable Fourier frequencies are determined by the data encoding scheme, while Fourier coefficients depend on both the reservoir and the measurement. Notably, the expressivity of QELMs is fundamentally limited by the number of Fourier frequencies and the number of observables, while the complexity of the prediction hinges on the reservoir. As a cautionary note on scalability, we identify four sources that can lead to the exponential concentration of the observables as the system size grows (randomness, hardware noise, entanglement, and global measurements) and show how this can turn QELMs into useless input-agnostic oracles. Our analysis elucidates the potential and fundamental limitations of QELMs, and lays the groundwork for systematically exploring quantum reservoir systems for other machine learning tasks.
Does provable absence of barren plateaus imply classical simulability? Or, why we need to rethink variational quantum computing
Dec 14, 2023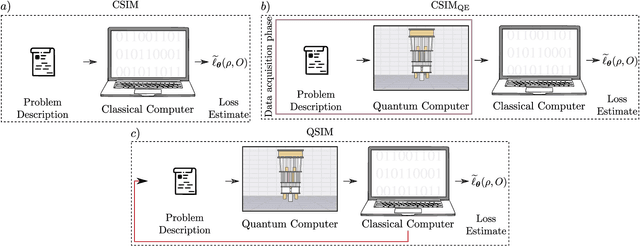
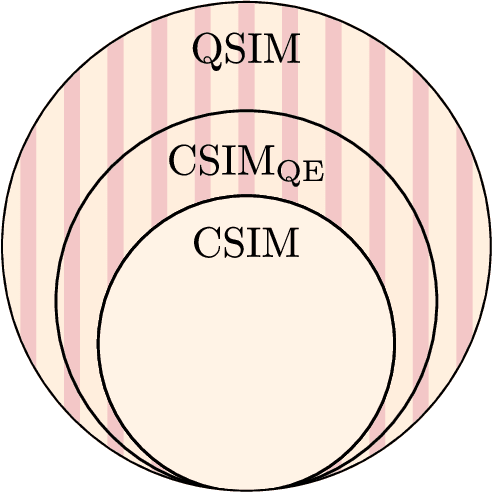
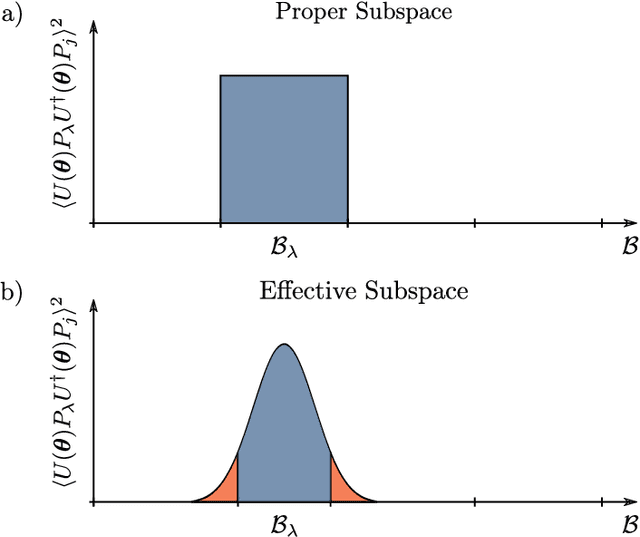
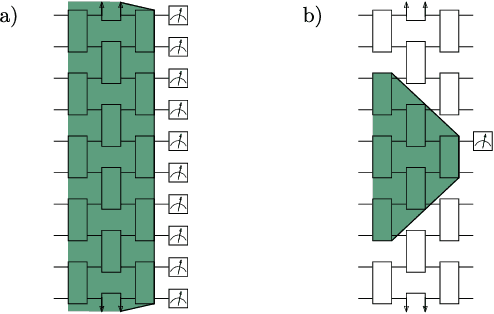
A large amount of effort has recently been put into understanding the barren plateau phenomenon. In this perspective article, we face the increasingly loud elephant in the room and ask a question that has been hinted at by many but not explicitly addressed: Can the structure that allows one to avoid barren plateaus also be leveraged to efficiently simulate the loss classically? We present strong evidence that commonly used models with provable absence of barren plateaus are also classically simulable, provided that one can collect some classical data from quantum devices during an initial data acquisition phase. This follows from the observation that barren plateaus result from a curse of dimensionality, and that current approaches for solving them end up encoding the problem into some small, classically simulable, subspaces. This sheds serious doubt on the non-classicality of the information processing capabilities of parametrized quantum circuits for barren plateau-free landscapes and on the possibility of superpolynomial advantages from running them on quantum hardware. We end by discussing caveats in our arguments, the role of smart initializations, and by highlighting new opportunities that our perspective raises.
Trainability barriers and opportunities in quantum generative modeling
May 04, 2023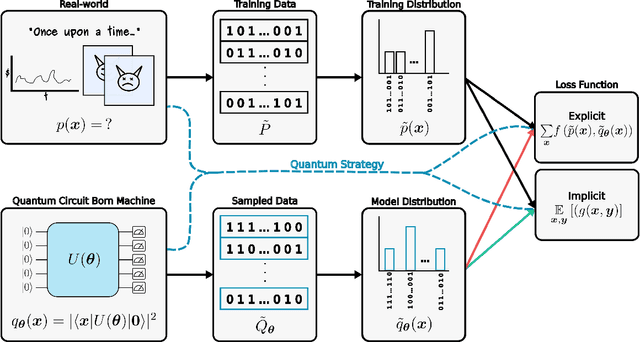
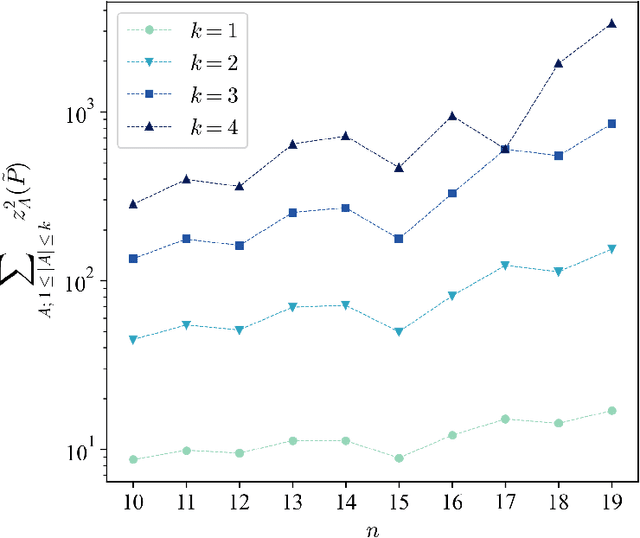
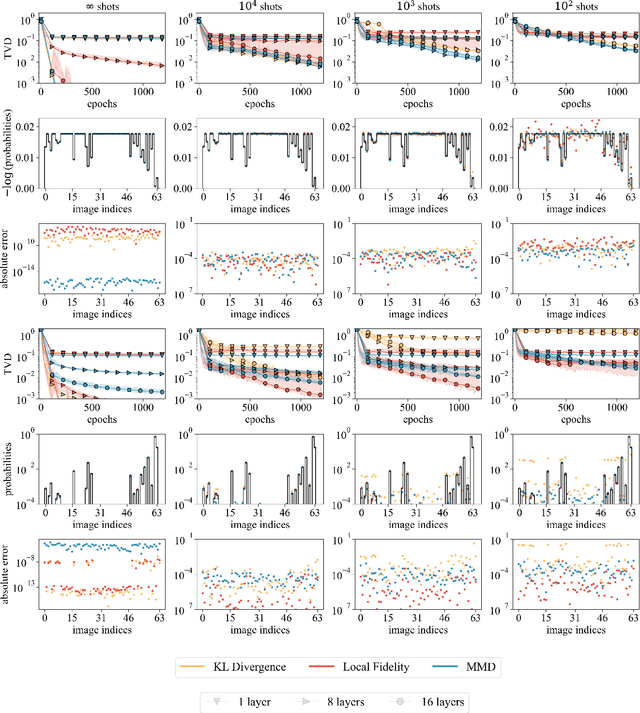
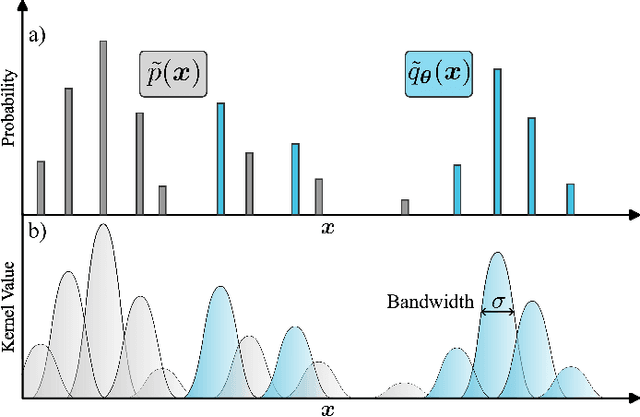
Quantum generative models, in providing inherently efficient sampling strategies, show promise for achieving a near-term advantage on quantum hardware. Nonetheless, important questions remain regarding their scalability. In this work, we investigate the barriers to the trainability of quantum generative models posed by barren plateaus and exponential loss concentration. We explore the interplay between explicit and implicit models and losses, and show that using implicit generative models (such as quantum circuit-based models) with explicit losses (such as the KL divergence) leads to a new flavour of barren plateau. In contrast, the Maximum Mean Discrepancy (MMD), which is a popular example of an implicit loss, can be viewed as the expectation value of an observable that is either low-bodied and trainable, or global and untrainable depending on the choice of kernel. However, in parallel, we highlight that the low-bodied losses required for trainability cannot in general distinguish high-order correlations, leading to a fundamental tension between exponential concentration and the emergence of spurious minima. We further propose a new local quantum fidelity-type loss which, by leveraging quantum circuits to estimate the quality of the encoded distribution, is both faithful and enjoys trainability guarantees. Finally, we compare the performance of different loss functions for modelling real-world data from the High-Energy-Physics domain and confirm the trends predicted by our theoretical results.