 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantum Circuit Pre-Synthesis: Learning Local Edits to Reduce $T$-count
Jan 27, 2026Compiling quantum circuits into Clifford+$T$ gates is a central task for fault-tolerant quantum computing using stabilizer codes. In the near term, $T$ gates will dominate the cost of fault tolerant implementations, and any reduction in the number of such expensive gates could mean the difference between being able to run a circuit or not. While exact synthesis is exponentially hard in the number of qubits, local synthesis approaches are commonly used to compile large circuits by decomposing them into substructures. However, composing local methods leads to suboptimal compilations in key metrics such as $T$-count or circuit depth, and their performance strongly depends on circuit representation. In this work, we address this challenge by proposing \textsc{Q-PreSyn}, a strategy that, given a set of local edits preserving circuit equivalence, uses a RL agent to identify effective sequences of such actions and thereby obtain circuit representations that yield a reduced $T$-count upon synthesis. Experimental results of our proposed strategy, applied on top of well-known synthesis algorithms, show up to a $20\%$ reduction in $T$-count on circuits with up to 25 qubits, without introducing any additional approximation error prior to synthesis.
Efficient quantum-enhanced classical simulation for patches of quantum landscapes
Nov 29, 2024



Understanding the capabilities of classical simulation methods is key to identifying where quantum computers are advantageous. Not only does this ensure that quantum computers are used only where necessary, but also one can potentially identify subroutines that can be offloaded onto a classical device. In this work, we show that it is always possible to generate a classical surrogate of a sub-region (dubbed a "patch") of an expectation landscape produced by a parameterized quantum circuit. That is, we provide a quantum-enhanced classical algorithm which, after simple measurements on a quantum device, allows one to classically simulate approximate expectation values of a subregion of a landscape. We provide time and sample complexity guarantees for a range of families of circuits of interest, and further numerically demonstrate our simulation algorithms on an exactly verifiable simulation of a Hamiltonian variational ansatz and long-time dynamics simulation on a 127-qubit heavy-hex topology.
Quantum Convolutional Neural Networks are (Effectively) Classically Simulable
Aug 22, 2024Quantum Convolutional Neural Networks (QCNNs) are widely regarded as a promising model for Quantum Machine Learning (QML). In this work we tie their heuristic success to two facts. First, that when randomly initialized, they can only operate on the information encoded in low-bodyness measurements of their input states. And second, that they are commonly benchmarked on "locally-easy'' datasets whose states are precisely classifiable by the information encoded in these low-bodyness observables subspace. We further show that the QCNN's action on this subspace can be efficiently classically simulated by a classical algorithm equipped with Pauli shadows on the dataset. Indeed, we present a shadow-based simulation of QCNNs on up-to $1024$ qubits for phases of matter classification. Our results can then be understood as highlighting a deeper symptom of QML: Models could only be showing heuristic success because they are benchmarked on simple problems, for which their action can be classically simulated. This insight points to the fact that non-trivial datasets are a truly necessary ingredient for moving forward with QML. To finish, we discuss how our results can be extrapolated to classically simulate other architectures.
Architectures and random properties of symplectic quantum circuits
May 16, 2024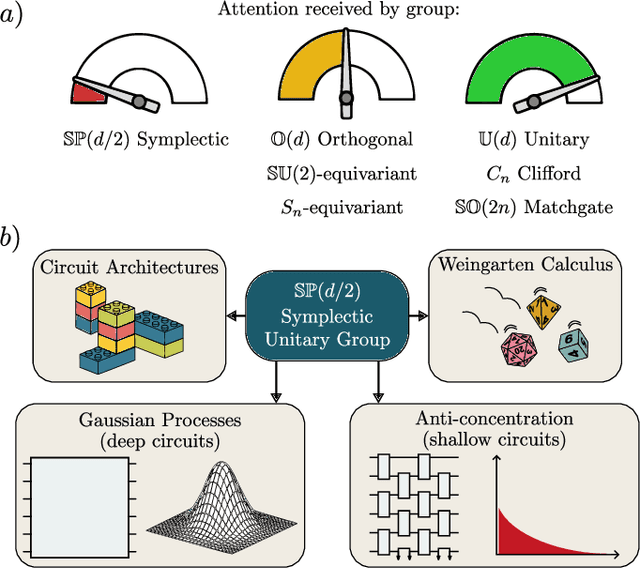

Parametrized and random unitary (or orthogonal) $n$-qubit circuits play a central role in quantum information. As such, one could naturally assume that circuits implementing symplectic transformation would attract similar attention. However, this is not the case, as $\mathbb{SP}(d/2)$ -- the group of $d\times d$ unitary symplectic matrices -- has thus far been overlooked. In this work, we aim at starting to right this wrong. We begin by presenting a universal set of generators $\mathcal{G}$ for the symplectic algebra $i\mathfrak{sp}(d/2)$, consisting of one- and two-qubit Pauli operators acting on neighboring sites in a one-dimensional lattice. Here, we uncover two critical differences between such set, and equivalent ones for unitary and orthogonal circuits. Namely, we find that the operators in $\mathcal{G}$ cannot generate arbitrary local symplectic unitaries and that they are not translationally invariant. We then review the Schur-Weyl duality between the symplectic group and the Brauer algebra, and use tools from Weingarten calculus to prove that Pauli measurements at the output of Haar random symplectic circuits can converge to Gaussian processes. As a by-product, such analysis provides us with concentration bounds for Pauli measurements in circuits that form $t$-designs over $\mathbb{SP}(d/2)$. To finish, we present tensor-network tools to analyze shallow random symplectic circuits, and we use these to numerically show that computational-basis measurements anti-concentrate at logarithmic depth.
A Review of Barren Plateaus in Variational Quantum Computing
May 01, 2024Variational quantum computing offers a flexible computational paradigm with applications in diverse areas. However, a key obstacle to realizing their potential is the Barren Plateau (BP) phenomenon. When a model exhibits a BP, its parameter optimization landscape becomes exponentially flat and featureless as the problem size increases. Importantly, all the moving pieces of an algorithm -- choices of ansatz, initial state, observable, loss function and hardware noise -- can lead to BPs when ill-suited. Due to the significant impact of BPs on trainability, researchers have dedicated considerable effort to develop theoretical and heuristic methods to understand and mitigate their effects. As a result, the study of BPs has become a thriving area of research, influencing and cross-fertilizing other fields such as quantum optimal control, tensor networks, and learning theory. This article provides a comprehensive review of the current understanding of the BP phenomenon.
Does provable absence of barren plateaus imply classical simulability? Or, why we need to rethink variational quantum computing
Dec 14, 2023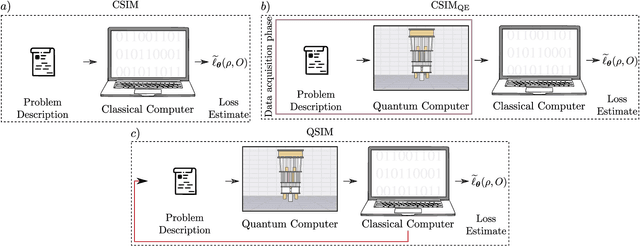
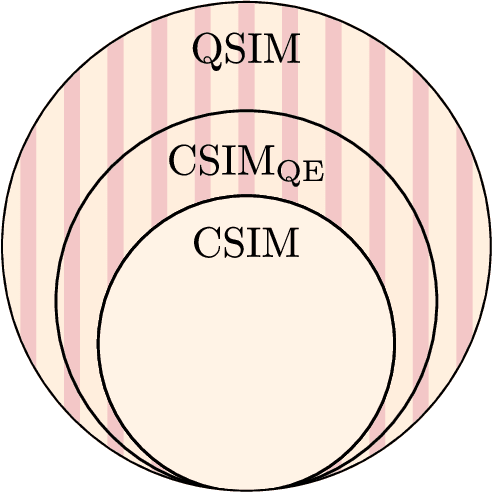
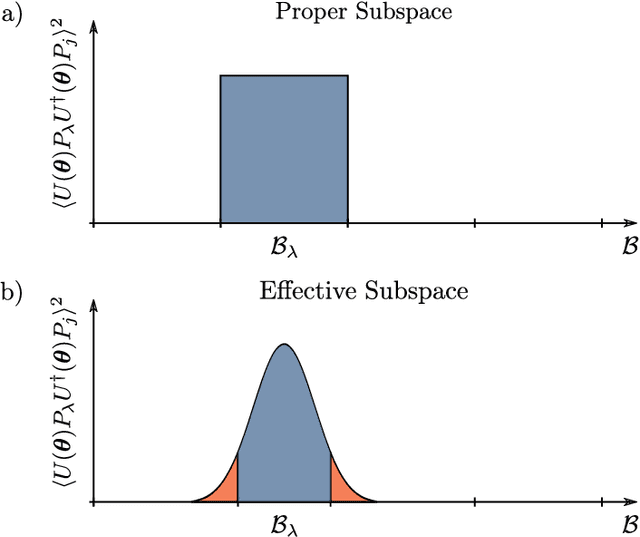
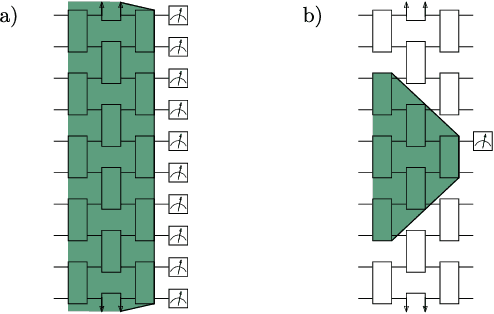
A large amount of effort has recently been put into understanding the barren plateau phenomenon. In this perspective article, we face the increasingly loud elephant in the room and ask a question that has been hinted at by many but not explicitly addressed: Can the structure that allows one to avoid barren plateaus also be leveraged to efficiently simulate the loss classically? We present strong evidence that commonly used models with provable absence of barren plateaus are also classically simulable, provided that one can collect some classical data from quantum devices during an initial data acquisition phase. This follows from the observation that barren plateaus result from a curse of dimensionality, and that current approaches for solving them end up encoding the problem into some small, classically simulable, subspaces. This sheds serious doubt on the non-classicality of the information processing capabilities of parametrized quantum circuits for barren plateau-free landscapes and on the possibility of superpolynomial advantages from running them on quantum hardware. We end by discussing caveats in our arguments, the role of smart initializations, and by highlighting new opportunities that our perspective raises.
Deep quantum neural networks form Gaussian processes
May 17, 2023It is well known that artificial neural networks initialized from independent and identically distributed priors converge to Gaussian processes in the limit of large number of neurons per hidden layer. In this work we prove an analogous result for Quantum Neural Networks (QNNs). Namely, we show that the outputs of certain models based on Haar random unitary or orthogonal deep QNNs converge to Gaussian processes in the limit of large Hilbert space dimension $d$. The derivation of this result is more nuanced than in the classical case due the role played by the input states, the measurement observable, and the fact that the entries of unitary matrices are not independent. An important consequence of our analysis is that the ensuing Gaussian processes cannot be used to efficiently predict the outputs of the QNN via Bayesian statistics. Furthermore, our theorems imply that the concentration of measure phenomenon in Haar random QNNs is much worse than previously thought, as we prove that expectation values and gradients concentrate as $\mathcal{O}\left(\frac{1}{e^d \sqrt{d}}\right)$ -- exponentially in the Hilbert space dimension. Finally, we discuss how our results improve our understanding of concentration in $t$-designs.
Challenges and Opportunities in Quantum Machine Learning
Mar 16, 2023At the intersection of machine learning and quantum computing, Quantum Machine Learning (QML) has the potential of accelerating data analysis, especially for quantum data, with applications for quantum materials, biochemistry, and high-energy physics. Nevertheless, challenges remain regarding the trainability of QML models. Here we review current methods and applications for QML. We highlight differences between quantum and classical machine learning, with a focus on quantum neural networks and quantum deep learning. Finally, we discuss opportunities for quantum advantage with QML.
* 14 pages, 5 figures
On the universality of $S_n$-equivariant $k$-body gates
Mar 01, 2023The importance of symmetries has recently been recognized in quantum machine learning from the simple motto: if a task exhibits a symmetry (given by a group $\mathfrak{G}$), the learning model should respect said symmetry. This can be instantiated via $\mathfrak{G}$-equivariant Quantum Neural Networks (QNNs), i.e., parametrized quantum circuits whose gates are generated by operators commuting with a given representation of $\mathfrak{G}$. In practice, however, there might be additional restrictions to the types of gates one can use, such as being able to act on at most $k$ qubits. In this work we study how the interplay between symmetry and $k$-bodyness in the QNN generators affect its expressiveness for the special case of $\mathfrak{G}=S_n$, the symmetric group. Our results show that if the QNN is generated by one- and two-body $S_n$-equivariant gates, the QNN is semi-universal but not universal. That is, the QNN can generate any arbitrary special unitary matrix in the invariant subspaces, but has no control over the relative phases between them. Then, we show that in order to reach universality one needs to include $n$-body generators (if $n$ is even) or $(n-1)$-body generators (if $n$ is odd). As such, our results brings us a step closer to better understanding the capabilities and limitations of equivariant QNNs.
Effects of noise on the overparametrization of quantum neural networks
Feb 10, 2023



Overparametrization is one of the most surprising and notorious phenomena in machine learning. Recently, there have been several efforts to study if, and how, Quantum Neural Networks (QNNs) acting in the absence of hardware noise can be overparametrized. In particular, it has been proposed that a QNN can be defined as overparametrized if it has enough parameters to explore all available directions in state space. That is, if the rank of the Quantum Fisher Information Matrix (QFIM) for the QNN's output state is saturated. Here, we explore how the presence of noise affects the overparametrization phenomenon. Our results show that noise can "turn on" previously-zero eigenvalues of the QFIM. This enables the parametrized state to explore directions that were otherwise inaccessible, thus potentially turning an overparametrized QNN into an underparametrized one. For small noise levels, the QNN is quasi-overparametrized, as large eigenvalues coexists with small ones. Then, we prove that as the magnitude of noise increases all the eigenvalues of the QFIM become exponentially suppressed, indicating that the state becomes insensitive to any change in the parameters. As such, there is a pull-and-tug effect where noise can enable new directions, but also suppress the sensitivity to parameter updates. Finally, our results imply that current QNN capacity measures are ill-defined when hardware noise is present.