 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Review of Barren Plateaus in Variational Quantum Computing
May 01, 2024Variational quantum computing offers a flexible computational paradigm with applications in diverse areas. However, a key obstacle to realizing their potential is the Barren Plateau (BP) phenomenon. When a model exhibits a BP, its parameter optimization landscape becomes exponentially flat and featureless as the problem size increases. Importantly, all the moving pieces of an algorithm -- choices of ansatz, initial state, observable, loss function and hardware noise -- can lead to BPs when ill-suited. Due to the significant impact of BPs on trainability, researchers have dedicated considerable effort to develop theoretical and heuristic methods to understand and mitigate their effects. As a result, the study of BPs has become a thriving area of research, influencing and cross-fertilizing other fields such as quantum optimal control, tensor networks, and learning theory. This article provides a comprehensive review of the current understanding of the BP phenomenon.
Exponential concentration and untrainability in quantum kernel methods
Aug 23, 2022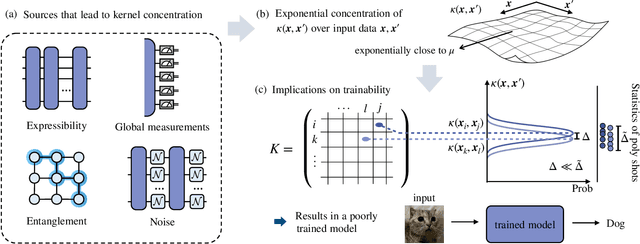
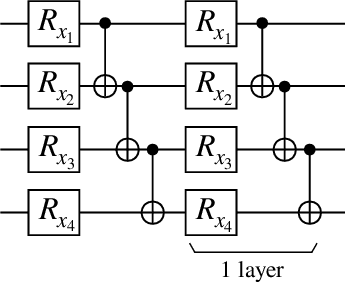
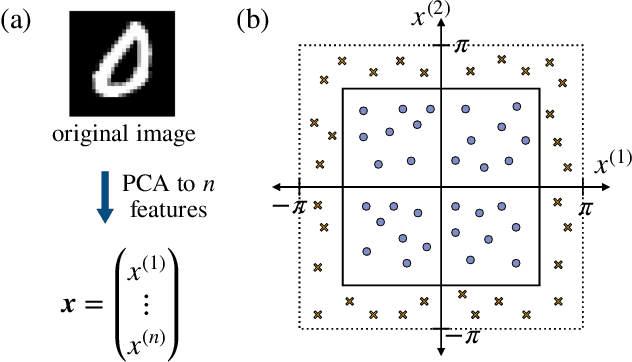
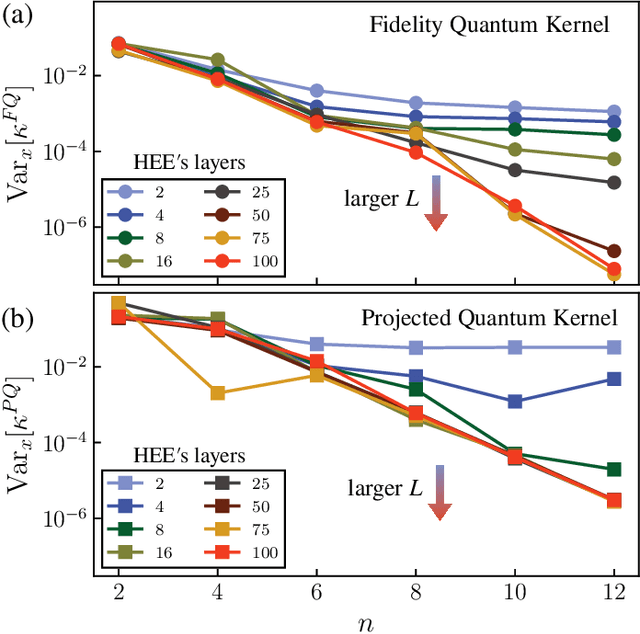
Kernel methods in Quantum Machine Learning (QML) have recently gained significant attention as a potential candidate for achieving a quantum advantage in data analysis. Among other attractive properties, when training a kernel-based model one is guaranteed to find the optimal model's parameters due to the convexity of the training landscape. However, this is based on the assumption that the quantum kernel can be efficiently obtained from a quantum hardware. In this work we study the trainability of quantum kernels from the perspective of the resources needed to accurately estimate kernel values. We show that, under certain conditions, values of quantum kernels over different input data can be exponentially concentrated (in the number of qubits) towards some fixed value, leading to an exponential scaling of the number of measurements required for successful training. We identify four sources that can lead to concentration including: the expressibility of data embedding, global measurements, entanglement and noise. For each source, an associated concentration bound of quantum kernels is analytically derived. Lastly, we show that when dealing with classical data, training a parametrized data embedding with a kernel alignment method is also susceptible to exponential concentration. Our results are verified through numerical simulations for several QML tasks. Altogether, we provide guidelines indicating that certain features should be avoided to ensure the efficient evaluation and the trainability of quantum kernel methods.
Subtleties in the trainability of quantum machine learning models
Oct 27, 2021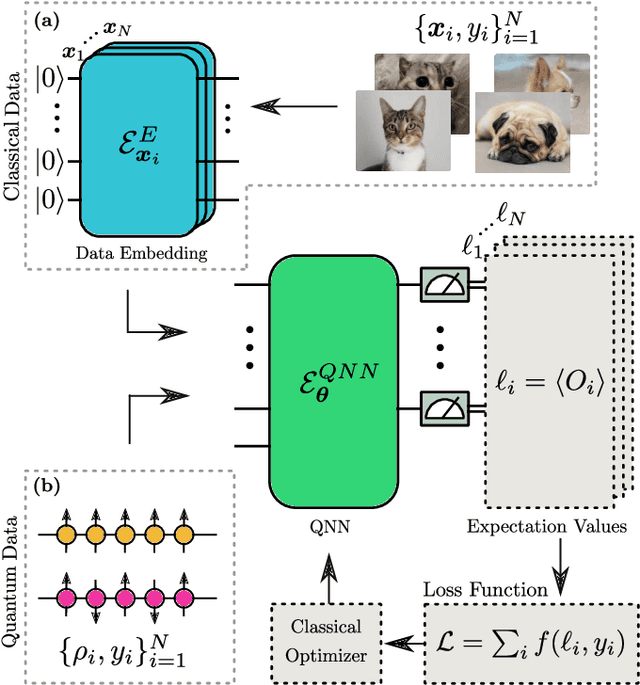


A new paradigm for data science has emerged, with quantum data, quantum models, and quantum computational devices. This field, called Quantum Machine Learning (QML), aims to achieve a speedup over traditional machine learning for data analysis. However, its success usually hinges on efficiently training the parameters in quantum neural networks, and the field of QML is still lacking theoretical scaling results for their trainability. Some trainability results have been proven for a closely related field called Variational Quantum Algorithms (VQAs). While both fields involve training a parametrized quantum circuit, there are crucial differences that make the results for one setting not readily applicable to the other. In this work we bridge the two frameworks and show that gradient scaling results for VQAs can also be applied to study the gradient scaling of QML models. Our results indicate that features deemed detrimental for VQA trainability can also lead to issues such as barren plateaus in QML. Consequently, our work has implications for several QML proposals in the literature. In addition, we provide theoretical and numerical evidence that QML models exhibit further trainability issues not present in VQAs, arising from the use of a training dataset. We refer to these as dataset-induced barren plateaus. These results are most relevant when dealing with classical data, as here the choice of embedding scheme (i.e., the map between classical data and quantum states) can greatly affect the gradient scaling.
Can Error Mitigation Improve Trainability of Noisy Variational Quantum Algorithms?
Sep 02, 2021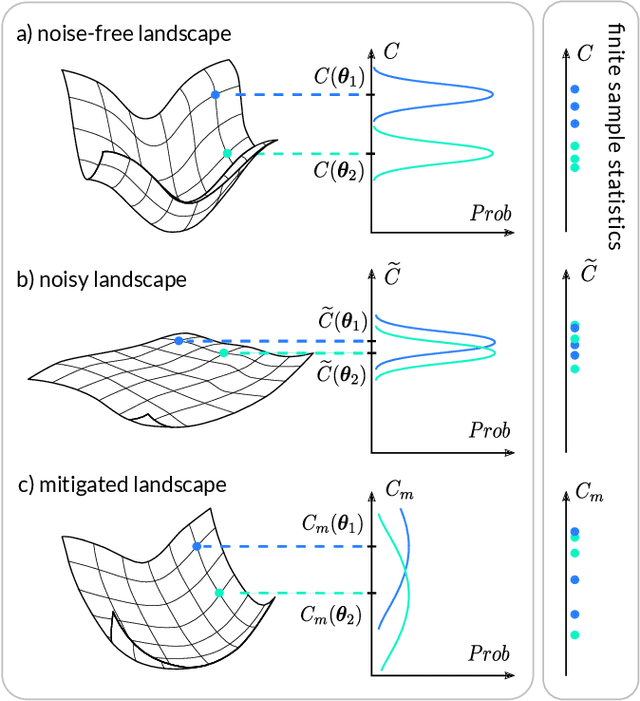
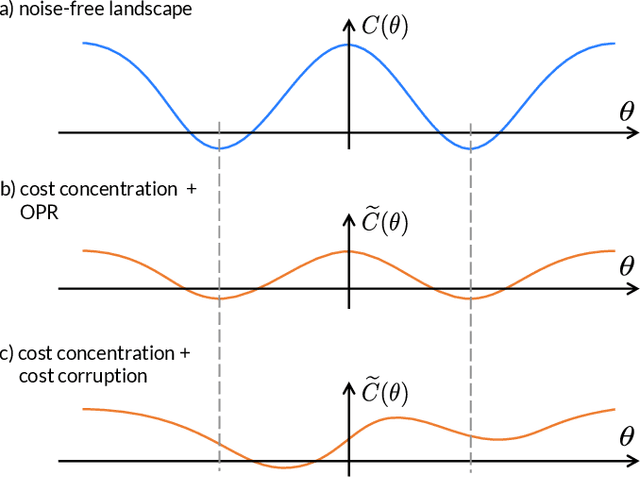
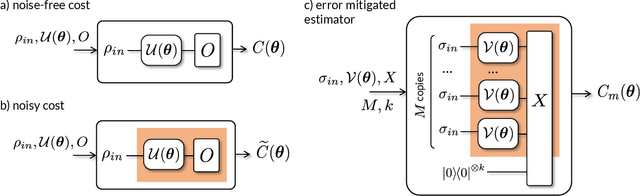
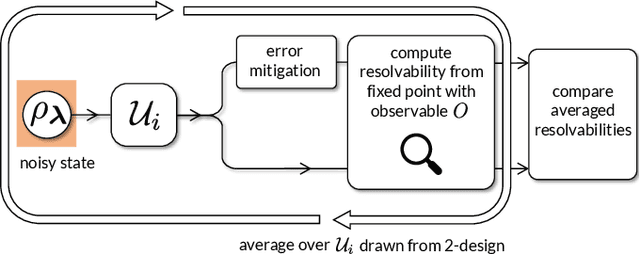
Variational Quantum Algorithms (VQAs) are widely viewed as the best hope for near-term quantum advantage. However, recent studies have shown that noise can severely limit the trainability of VQAs, e.g., by exponentially flattening the cost landscape and suppressing the magnitudes of cost gradients. Error Mitigation (EM) shows promise in reducing the impact of noise on near-term devices. Thus, it is natural to ask whether EM can improve the trainability of VQAs. In this work, we first show that, for a broad class of EM strategies, exponential cost concentration cannot be resolved without committing exponential resources elsewhere. This class of strategies includes as special cases Zero Noise Extrapolation, Virtual Distillation, Probabilistic Error Cancellation, and Clifford Data Regression. Second, we perform analytical and numerical analysis of these EM protocols, and we find that some of them (e.g., Virtual Distillation) can make it harder to resolve cost function values compared to running no EM at all. As a positive result, we do find numerical evidence that Clifford Data Regression (CDR) can aid the training process in certain settings where cost concentration is not too severe. Our results show that care should be taken in applying EM protocols as they can either worsen or not improve trainability. On the other hand, our positive results for CDR highlight the possibility of engineering error mitigation methods to improve trainability.
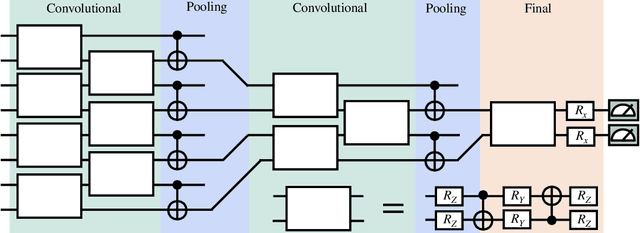
Absence of Barren Plateaus in Quantum Convolutional Neural Networks
Nov 05, 2020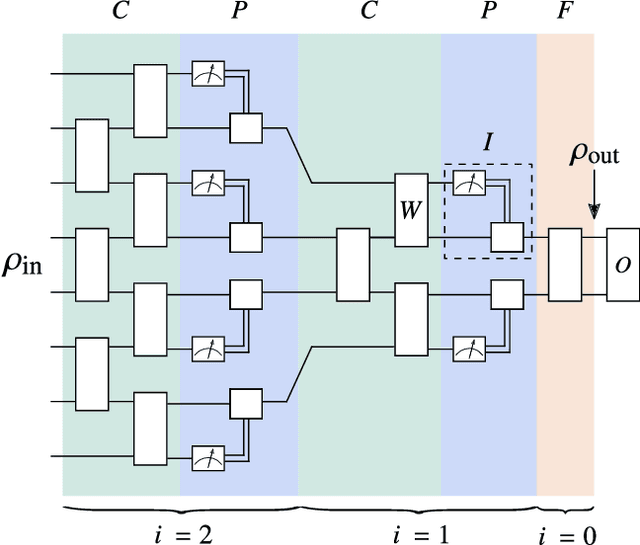
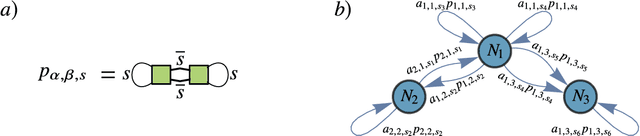


Quantum neural networks (QNNs) have generated excitement around the possibility of efficiently analyzing quantum data. But this excitement has been tempered by the existence of exponentially vanishing gradients, known as barren plateau landscapes, for many QNN architectures. Recently, Quantum Convolutional Neural Networks (QCNNs) have been proposed, involving a sequence of convolutional and pooling layers that reduce the number of qubits while preserving information about relevant data features. In this work we rigorously analyze the gradient scaling for the parameters in the QCNN architecture. We find that the variance of the gradient vanishes no faster than polynomially, implying that QCNNs do not exhibit barren plateaus. This provides an analytical guarantee for the trainability of randomly initialized QCNNs, which singles out QCNNs as being trainable unlike many other QNN architectures. To derive our results we introduce a novel graph-based method to analyze expectation values over Haar-distributed unitaries, which will likely be useful in other contexts. Finally, we perform numerical simulations to verify our analytical results.
Noise-Induced Barren Plateaus in Variational Quantum Algorithms
Jul 28, 2020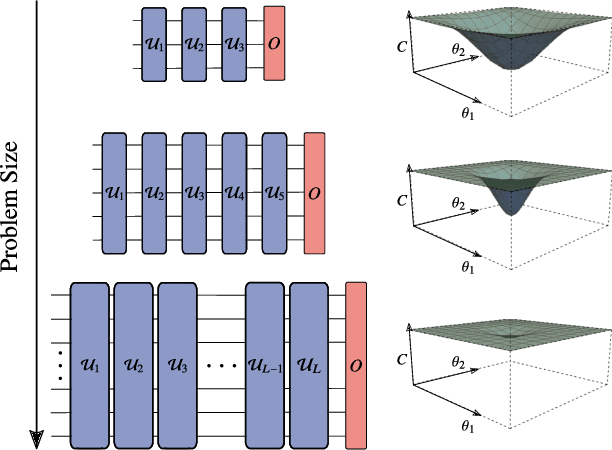
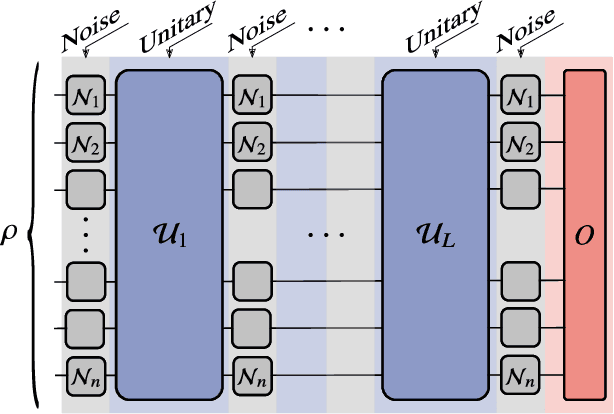
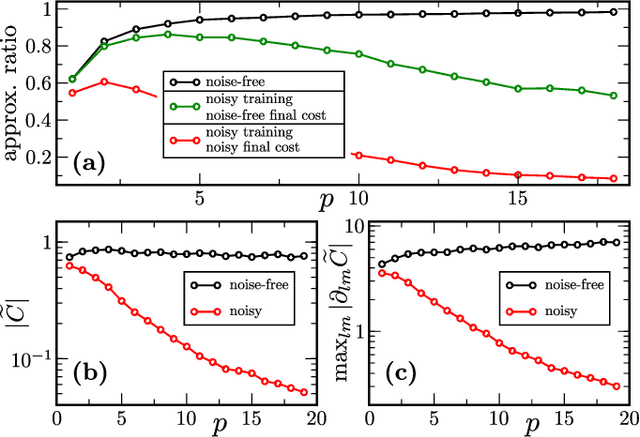
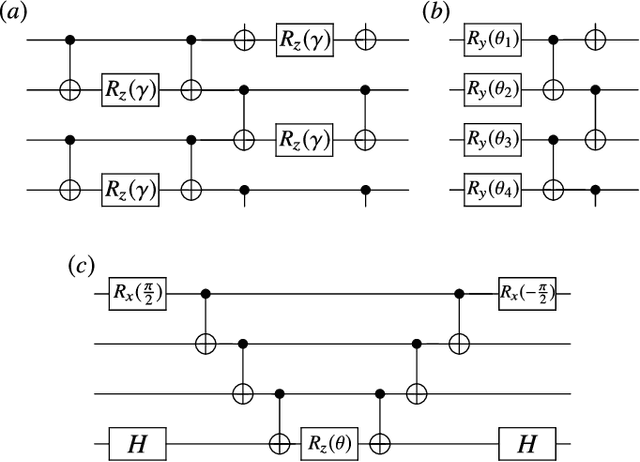
Variational Quantum Algorithms (VQAs) may be a path to quantum advantage on Noisy Intermediate-Scale Quantum (NISQ) computers. A natural question is whether the noise on NISQ devices places any fundamental limitations on the performance of VQAs. In this work, we rigorously prove a serious limitation for noisy VQAs, in that the noise causes the training landscape to have a barren plateau (i.e., vanishing gradient). Specifically, for the local Pauli noise considered, we prove that the gradient vanishes exponentially in the number of layers $L$. This implies exponential decay in the number of qubits $n$ when $L$ scales as $\operatorname{poly}(n)$, for sufficiently large coefficients in the polynomial. These noise-induced barren plateaus (NIBPs) are conceptually different from noise-free barren plateaus, which are linked to random parameter initialization. Our result is formulated for an abstract ansatz that includes as special cases the Quantum Alternating Operator Ansatz (QAOA) and the Unitary Coupled Cluster Ansatz, among others. In the case of the QAOA, we implement numerical heuristics that confirm the NIBP phenomenon for a realistic hardware noise model.