 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubtleties in the trainability of quantum machine learning models
Paper and Code
Oct 27, 2021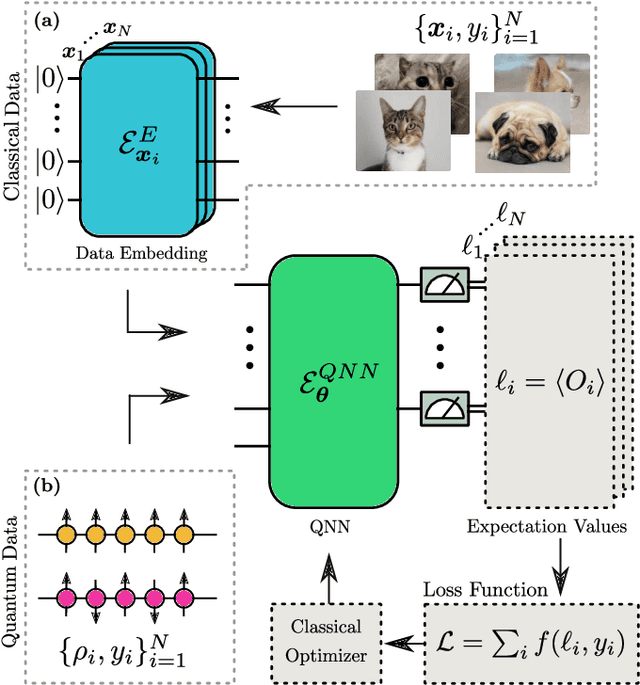


A new paradigm for data science has emerged, with quantum data, quantum models, and quantum computational devices. This field, called Quantum Machine Learning (QML), aims to achieve a speedup over traditional machine learning for data analysis. However, its success usually hinges on efficiently training the parameters in quantum neural networks, and the field of QML is still lacking theoretical scaling results for their trainability. Some trainability results have been proven for a closely related field called Variational Quantum Algorithms (VQAs). While both fields involve training a parametrized quantum circuit, there are crucial differences that make the results for one setting not readily applicable to the other. In this work we bridge the two frameworks and show that gradient scaling results for VQAs can also be applied to study the gradient scaling of QML models. Our results indicate that features deemed detrimental for VQA trainability can also lead to issues such as barren plateaus in QML. Consequently, our work has implications for several QML proposals in the literature. In addition, we provide theoretical and numerical evidence that QML models exhibit further trainability issues not present in VQAs, arising from the use of a training dataset. We refer to these as dataset-induced barren plateaus. These results are most relevant when dealing with classical data, as here the choice of embedding scheme (i.e., the map between classical data and quantum states) can greatly affect the gradient scaling.