 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantum latent distributions in deep generative models
Aug 27, 2025Many successful families of generative models leverage a low-dimensional latent distribution that is mapped to a data distribution. Though simple latent distributions are commonly used, it has been shown that more sophisticated distributions can improve performance. For instance, recent work has explored using the distributions produced by quantum processors and found empirical improvements. However, when latent space distributions produced by quantum processors can be expected to improve performance, and whether these improvements are reproducible, are open questions that we investigate in this work. We prove that, under certain conditions, these "quantum latent distributions" enable generative models to produce data distributions that classical latent distributions cannot efficiently produce. We also provide actionable intuitions to identify when such quantum advantages may arise in real-world settings. We perform benchmarking experiments on both a synthetic quantum dataset and the QM9 molecular dataset, using both simulated and real photonic quantum processors. Our results demonstrate that quantum latent distributions can lead to improved generative performance in GANs compared to a range of classical baselines. We also explore diffusion and flow matching models, identifying architectures compatible with quantum latent distributions. This work confirms that near-term quantum processors can expand the capabilities of deep generative models.
Exact gradients for linear optics with single photons
Sep 24, 2024Though parameter shift rules have drastically improved gradient estimation methods for several types of quantum circuits, leading to improved performance in downstream tasks, so far they have not been transferable to linear optics with single photons. In this work, we derive an analytical formula for the gradients in these circuits with respect to phaseshifters via a generalized parameter shift rule, where the number of parameter shifts depends linearly on the total number of photons. Experimentally, this enables access to derivatives in photonic systems without the need for finite difference approximations. Building on this, we propose two strategies through which one can reduce the number of shifts in the expression, and hence reduce the overall sample complexity. Numerically, we show that this generalized parameter-shift rule can converge to the minimum of a cost function with fewer parameter update steps than alternative techniques. We anticipate that this method will open up new avenues to solving optimization problems with photonic systems, as well as provide new techniques for the experimental characterization and control of linear optical systems.
Learning Group Structure and Disentangled Representations of Dynamical Environments
Feb 17, 2020

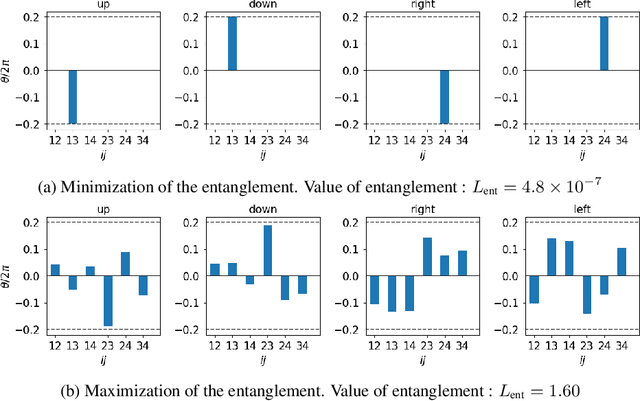
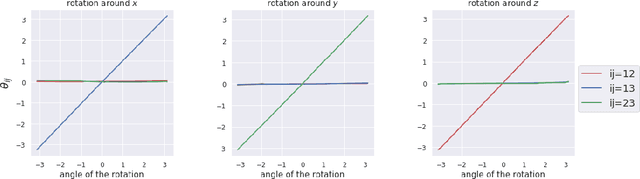
Discovering the underlying structure of a dynamical environment involves learning representations that are interpretable and disentangled, which is a challenging task. In physics, interpretable representations of our universe and its underlying dynamics are formulated in terms of representations of groups of symmetry transformations. We propose a physics-inspired method, built upon the theory of group representation, that learns a representation of an environment structured around the transformations that generate its evolution. Experimentally, we learn the structure of explicitly symmetric environments without supervision while ensuring the interpretability of the representations. We show that the learned representations allow for accurate long-horizon predictions and further demonstrate a correlation between the quality of predictions and disentanglement in the latent space.
Robust Domain Randomization for Reinforcement Learning
Oct 23, 2019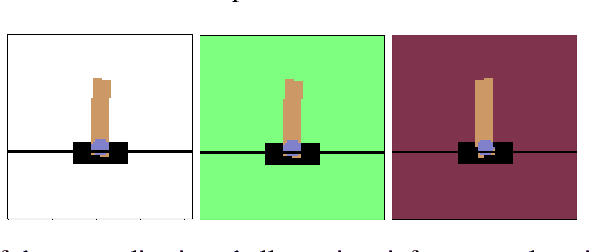

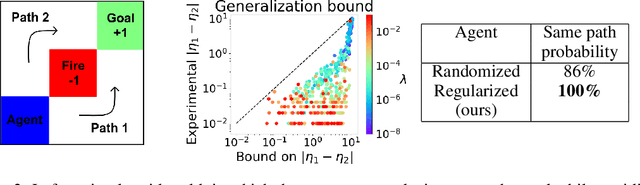
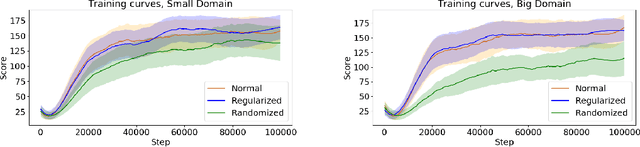
Producing agents that can generalize to a wide range of environments is a significant challenge in reinforcement learning. One method for overcoming this issue is domain randomization, whereby at the start of each training episode some parameters of the environment are randomized so that the agent is exposed to many possible variations. However, domain randomization is highly inefficient and may lead to policies with high variance across domains. In this work, we formalize the domain randomization problem, and show that minimizing the policy's Lipschitz constant with respect to the randomization parameters leads to low variance in the learned policies. We propose a method where the agent only needs to be trained on one variation of the environment, and its learned state representations are regularized during training to minimize this constant. We conduct experiments that demonstrate that our technique leads to more efficient and robust learning than standard domain randomization, while achieving equal generalization scores.
Exploratory Combinatorial Optimization with Reinforcement Learning
Sep 09, 2019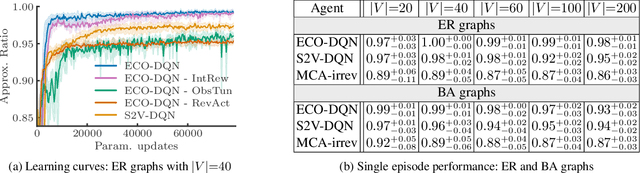
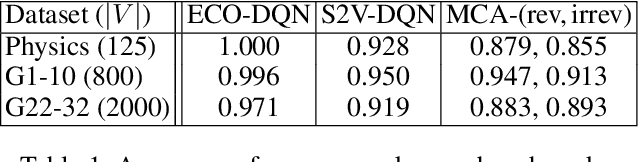
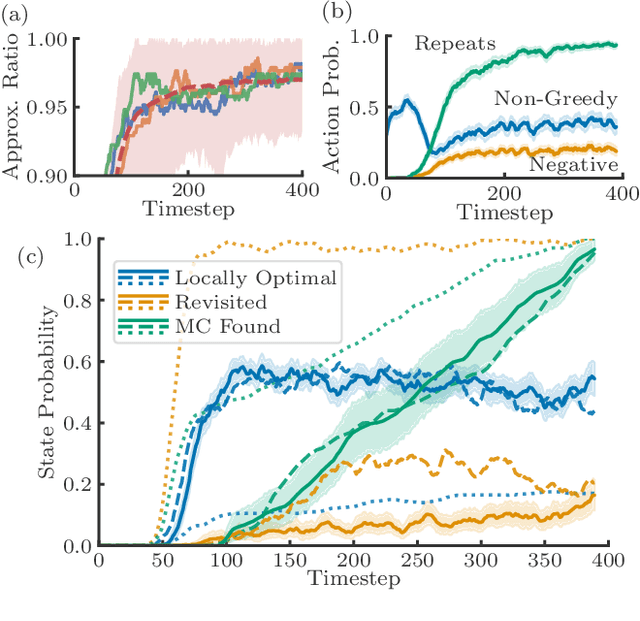

Many real-world problems can be reduced to combinatorial optimization on a graph, where the subset or ordering of vertices that maximize some objective function must be found. With such tasks often NP-hard and analytically intractable, reinforcement learning (RL) has shown promise as a framework with which efficient heuristic methods to tackle these problems can be learned. Previous works construct the solution subset incrementally, adding one element at a time, however, the irreversible nature of this approach prevents the agent from revising its earlier decisions, which may be necessary given the complexity of the optimization task. We instead propose that the agent should seek to continuously improve the solution by learning to explore at test time. Our approach of exploratory combinatorial optimization (ECO-DQN) is, in principle, applicable to any combinatorial problem that can be defined on a graph. Experimentally, we show our method to produce state-of-the-art RL performance on the Maximum Cut problem. Moreover, because ECO-DQN can start from any arbitrary configuration, it can be combined with other search methods to further improve performance, which we demonstrate using a simple random search.
Estimating Risk and Uncertainty in Deep Reinforcement Learning
Jun 07, 2019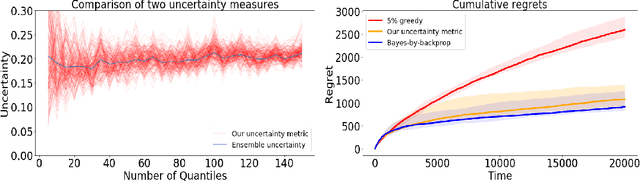
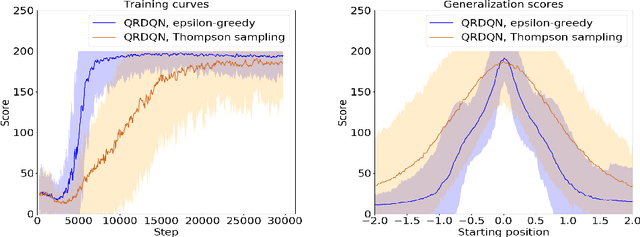
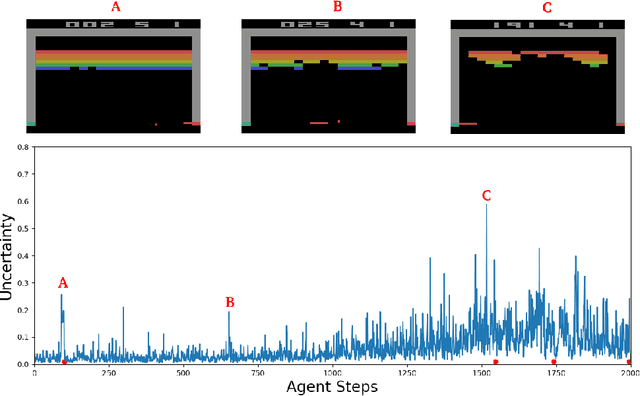
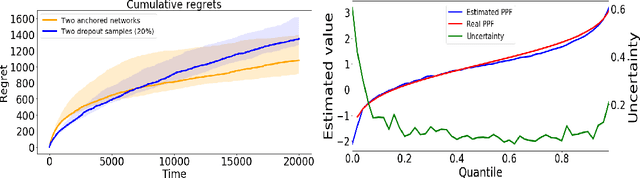
This paper demonstrates a novel method for separately estimating aleatoric risk and epistemic uncertainty in deep reinforcement learning. Aleatoric risk, which arises from inherently stochastic environments or agents, must be accounted for in the design of risk-sensitive algorithms. Epistemic uncertainty, which stems from limited data, is important both for risk-sensitivity and to efficiently explore an environment. We first present a Bayesian framework for learning the return distribution in reinforcement learning, which provides theoretical foundations for quantifying both types of uncertainty. Based on this framework, we show that the disagreement between only two neural networks is sufficient to produce a low-variance estimate of the epistemic uncertainty on the return distribution, thus providing a simple and computationally cheap uncertainty metric. We demonstrate experiments that illustrate our method and some applications.