 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOverconfident Oracles: Limitations of In Silico Sequence Design Benchmarking
Feb 24, 2025Machine learning methods can automate the in silico design of biological sequences, aiming to reduce costs and accelerate medical research. Given the limited access to wet labs, in silico design methods commonly use an oracle model to evaluate de novo generated sequences. However, the use of different oracle models across methods makes it challenging to compare them reliably, motivating the question: are in silico sequence design benchmarks reliable? In this work, we examine 12 sequence design methods that utilise ML oracles common in the literature and find that there are significant challenges with their cross-consistency and reproducibility. Indeed, oracles differing by architecture, or even just training seed, are shown to yield conflicting relative performance with our analysis suggesting poor out-of-distribution generalisation as a key issue. To address these challenges, we propose supplementing the evaluation with a suite of biophysical measures to assess the viability of generated sequences and limit out-of-distribution sequences the oracle is required to score, thereby improving the robustness of the design procedure. Our work aims to highlight potential pitfalls in the current evaluation process and contribute to the development of robust benchmarks, ultimately driving the improvement of in silico design methods.
BoostMD: Accelerating molecular sampling by leveraging ML force field features from previous time-steps
Dec 21, 2024Simulating atomic-scale processes, such as protein dynamics and catalytic reactions, is crucial for advancements in biology, chemistry, and materials science. Machine learning force fields (MLFFs) have emerged as powerful tools that achieve near quantum mechanical accuracy, with promising generalization capabilities. However, their practical use is often limited by long inference times compared to classical force fields, especially when running extensive molecular dynamics (MD) simulations required for many biological applications. In this study, we introduce BoostMD, a surrogate model architecture designed to accelerate MD simulations. BoostMD leverages node features computed at previous time steps to predict energies and forces based on positional changes. This approach reduces the complexity of the learning task, allowing BoostMD to be both smaller and significantly faster than conventional MLFFs. During simulations, the computationally intensive reference MLFF is evaluated only every $N$ steps, while the lightweight BoostMD model handles the intermediate steps at a fraction of the computational cost. Our experiments demonstrate that BoostMD achieves an eight-fold speedup compared to the reference model and generalizes to unseen dipeptides. Furthermore, we find that BoostMD accurately samples the ground-truth Boltzmann distribution when running molecular dynamics. By combining efficient feature reuse with a streamlined architecture, BoostMD offers a robust solution for conducting large-scale, long-timescale molecular simulations, making high-accuracy ML-driven modeling more accessible and practical.
Metalic: Meta-Learning In-Context with Protein Language Models
Oct 10, 2024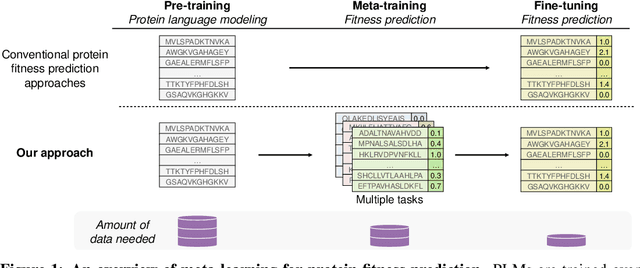
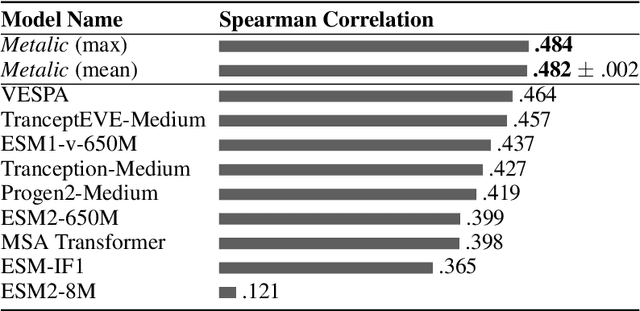
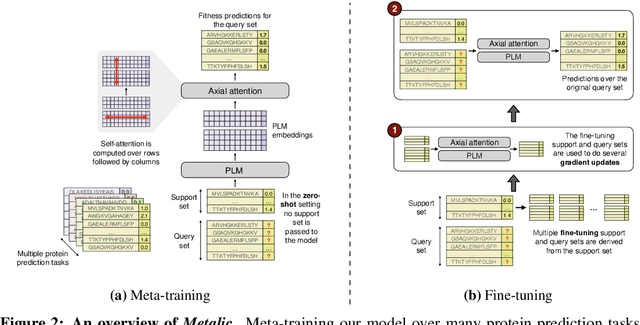

Predicting the biophysical and functional properties of proteins is essential for in silico protein design. Machine learning has emerged as a promising technique for such prediction tasks. However, the relative scarcity of in vitro annotations means that these models often have little, or no, specific data on the desired fitness prediction task. As a result of limited data, protein language models (PLMs) are typically trained on general protein sequence modeling tasks, and then fine-tuned, or applied zero-shot, to protein fitness prediction. When no task data is available, the models make strong assumptions about the correlation between the protein sequence likelihood and fitness scores. In contrast, we propose meta-learning over a distribution of standard fitness prediction tasks, and demonstrate positive transfer to unseen fitness prediction tasks. Our method, called Metalic (Meta-Learning In-Context), uses in-context learning and fine-tuning, when data is available, to adapt to new tasks. Crucially, fine-tuning enables considerable generalization, even though it is not accounted for during meta-training. Our fine-tuned models achieve strong results with 18 times fewer parameters than state-of-the-art models. Moreover, our method sets a new state-of-the-art in low-data settings on ProteinGym, an established fitness-prediction benchmark. Due to data scarcity, we believe meta-learning will play a pivotal role in advancing protein engineering.
Memory-Enhanced Neural Solvers for Efficient Adaptation in Combinatorial Optimization
Jun 24, 2024Combinatorial Optimization is crucial to numerous real-world applications, yet still presents challenges due to its (NP-)hard nature. Amongst existing approaches, heuristics often offer the best trade-off between quality and scalability, making them suitable for industrial use. While Reinforcement Learning (RL) offers a flexible framework for designing heuristics, its adoption over handcrafted heuristics remains incomplete within industrial solvers. Existing learned methods still lack the ability to adapt to specific instances and fully leverage the available computational budget. The current best methods either rely on a collection of pre-trained policies, or on data-inefficient fine-tuning; hence failing to fully utilize newly available information within the constraints of the budget. In response, we present MEMENTO, an RL approach that leverages memory to improve the adaptation of neural solvers at inference time. MEMENTO enables updating the action distribution dynamically based on the outcome of previous decisions. We validate its effectiveness on benchmark problems, in particular Traveling Salesman and Capacitated Vehicle Routing, demonstrating it can successfully be combined with standard methods to boost their performance under a given budget, both in and out-of-distribution, improving their performance on all 12 evaluated tasks.
Learning the Language of Protein Structure
May 24, 2024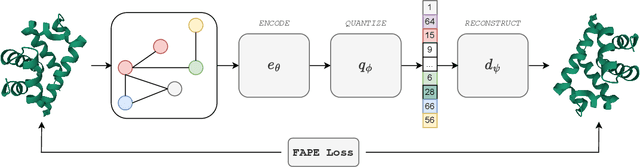
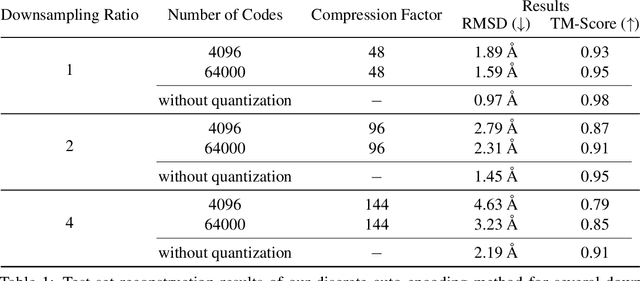

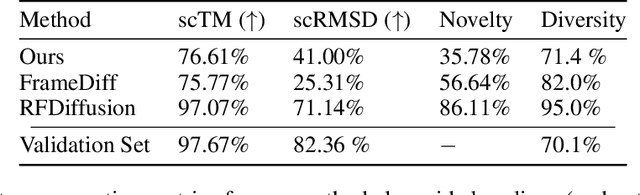
Representation learning and \emph{de novo} generation of proteins are pivotal computational biology tasks. Whilst natural language processing (NLP) techniques have proven highly effective for protein sequence modelling, structure modelling presents a complex challenge, primarily due to its continuous and three-dimensional nature. Motivated by this discrepancy, we introduce an approach using a vector-quantized autoencoder that effectively tokenizes protein structures into discrete representations. This method transforms the continuous, complex space of protein structures into a manageable, discrete format with a codebook ranging from 4096 to 64000 tokens, achieving high-fidelity reconstructions with backbone root mean square deviations (RMSD) of approximately 1-5 \AA. To demonstrate the efficacy of our learned representations, we show that a simple GPT model trained on our codebooks can generate novel, diverse, and designable protein structures. Our approach not only provides representations of protein structure, but also mitigates the challenges of disparate modal representations and sets a foundation for seamless, multi-modal integration, enhancing the capabilities of computational methods in protein design.
Are we going MAD? Benchmarking Multi-Agent Debate between Language Models for Medical Q&A
Nov 29, 2023Recent advancements in large language models (LLMs) underscore their potential for responding to medical inquiries. However, ensuring that generative agents provide accurate and reliable answers remains an ongoing challenge. In this context, multi-agent debate (MAD) has emerged as a prominent strategy for enhancing the truthfulness of LLMs. In this work, we provide a comprehensive benchmark of MAD strategies for medical Q&A, along with open-source implementations. This explores the effective utilization of various strategies including the trade-offs between cost, time, and accuracy. We build upon these insights to provide a novel debate-prompting strategy based on agent agreement that outperforms previously published strategies on medical Q&A tasks.
Combinatorial Optimization with Policy Adaptation using Latent Space Search
Nov 13, 2023Combinatorial Optimization underpins many real-world applications and yet, designing performant algorithms to solve these complex, typically NP-hard, problems remains a significant research challenge. Reinforcement Learning (RL) provides a versatile framework for designing heuristics across a broad spectrum of problem domains. However, despite notable progress, RL has not yet supplanted industrial solvers as the go-to solution. Current approaches emphasize pre-training heuristics that construct solutions but often rely on search procedures with limited variance, such as stochastically sampling numerous solutions from a single policy or employing computationally expensive fine-tuning of the policy on individual problem instances. Building on the intuition that performant search at inference time should be anticipated during pre-training, we propose COMPASS, a novel RL approach that parameterizes a distribution of diverse and specialized policies conditioned on a continuous latent space. We evaluate COMPASS across three canonical problems - Travelling Salesman, Capacitated Vehicle Routing, and Job-Shop Scheduling - and demonstrate that our search strategy (i) outperforms state-of-the-art approaches on 11 standard benchmarking tasks and (ii) generalizes better, surpassing all other approaches on a set of 18 procedurally transformed instance distributions.
Population-Based Reinforcement Learning for Combinatorial Optimization
Oct 07, 2022

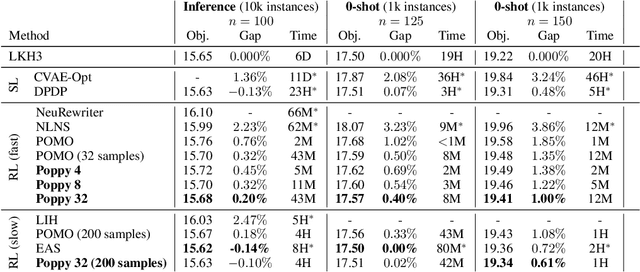
Applying reinforcement learning (RL) to combinatorial optimization problems is attractive as it removes the need for expert knowledge or pre-solved instances. However, it is unrealistic to expect an agent to solve these (often NP-)hard problems in a single shot at inference due to their inherent complexity. Thus, leading approaches often implement additional search strategies, from stochastic sampling and beam-search to explicit fine-tuning. In this paper, we argue for the benefits of learning a population of complementary policies, which can be simultaneously rolled out at inference. To this end, we introduce Poppy, a simple theoretically grounded training procedure for populations. Instead of relying on a predefined or hand-crafted notion of diversity, Poppy induces an unsupervised specialization targeted solely at maximizing the performance of the population. We show that Poppy produces a set of complementary policies, and obtains state-of-the-art RL results on three popular NP-hard problems: the traveling salesman (TSP), the capacitated vehicle routing (CVRP), and 0-1 knapsack (KP) problems. On TSP specifically, Poppy outperforms the previous state-of-the-art, dividing the optimality gap by 5 while reducing the inference time by more than an order of magnitude.
Universally Expressive Communication in Multi-Agent Reinforcement Learning
Jun 14, 2022
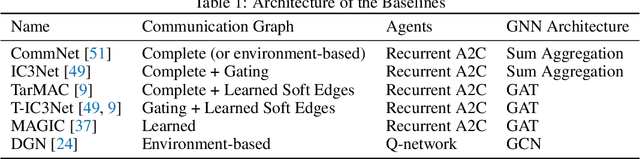

Allowing agents to share information through communication is crucial for solving complex tasks in multi-agent reinforcement learning. In this work, we consider the question of whether a given communication protocol can express an arbitrary policy. By observing that many existing protocols can be viewed as instances of graph neural networks (GNNs), we demonstrate the equivalence of joint action selection to node labelling. With standard GNN approaches provably limited in their expressive capacity, we draw from existing GNN literature and consider augmenting agent observations with: (1) unique agent IDs and (2) random noise. We provide a theoretical analysis as to how these approaches yield universally expressive communication, and also prove them capable of targeting arbitrary sets of actions for identical agents. Empirically, these augmentations are found to improve performance on tasks where expressive communication is required, whilst, in general, the optimal communication protocol is found to be task-dependent.
Reinforcement Learning for Branch-and-Bound Optimisation using Retrospective Trajectories
May 28, 2022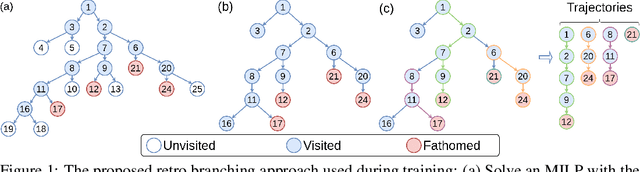
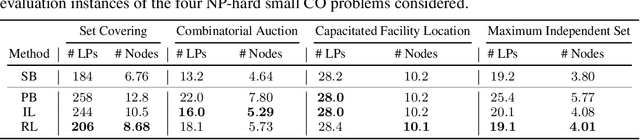
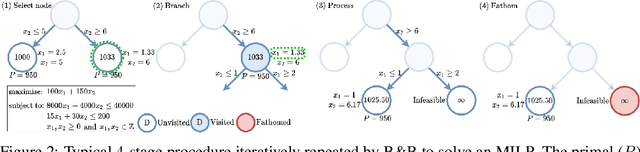
Combinatorial optimisation problems framed as mixed integer linear programmes (MILPs) are ubiquitous across a range of real-world applications. The canonical branch-and-bound (B&B) algorithm seeks to exactly solve MILPs by constructing a search tree of increasingly constrained sub-problems. In practice, its solving time performance is dependent on heuristics, such as the choice of the next variable to constrain ('branching'). Recently, machine learning (ML) has emerged as a promising paradigm for branching. However, prior works have struggled to apply reinforcement learning (RL), citing sparse rewards, difficult exploration, and partial observability as significant challenges. Instead, leading ML methodologies resort to approximating high quality handcrafted heuristics with imitation learning (IL), which precludes the discovery of novel policies and requires expensive data labelling. In this work, we propose retro branching; a simple yet effective approach to RL for branching. By retrospectively deconstructing the search tree into multiple paths each contained within a sub-tree, we enable the agent to learn from shorter trajectories with more predictable next states. In experiments on four combinatorial tasks, our approach enables learning-to-branch without any expert guidance or pre-training. We outperform the current state-of-the-art RL branching algorithm by 3-5x and come within 20% of the best IL method's performance on MILPs with 500 constraints and 1000 variables, with ablations verifying that our retrospectively constructed trajectories are essential to achieving these results.