 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOverconfident Oracles: Limitations of In Silico Sequence Design Benchmarking
Feb 24, 2025Machine learning methods can automate the in silico design of biological sequences, aiming to reduce costs and accelerate medical research. Given the limited access to wet labs, in silico design methods commonly use an oracle model to evaluate de novo generated sequences. However, the use of different oracle models across methods makes it challenging to compare them reliably, motivating the question: are in silico sequence design benchmarks reliable? In this work, we examine 12 sequence design methods that utilise ML oracles common in the literature and find that there are significant challenges with their cross-consistency and reproducibility. Indeed, oracles differing by architecture, or even just training seed, are shown to yield conflicting relative performance with our analysis suggesting poor out-of-distribution generalisation as a key issue. To address these challenges, we propose supplementing the evaluation with a suite of biophysical measures to assess the viability of generated sequences and limit out-of-distribution sequences the oracle is required to score, thereby improving the robustness of the design procedure. Our work aims to highlight potential pitfalls in the current evaluation process and contribute to the development of robust benchmarks, ultimately driving the improvement of in silico design methods.
Metalic: Meta-Learning In-Context with Protein Language Models
Oct 10, 2024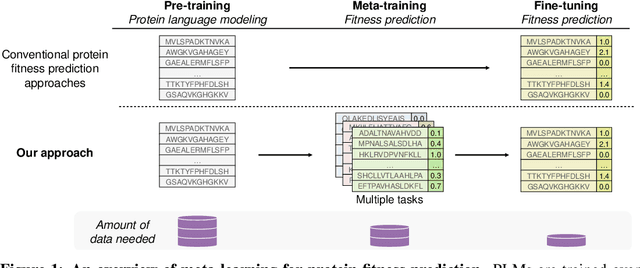
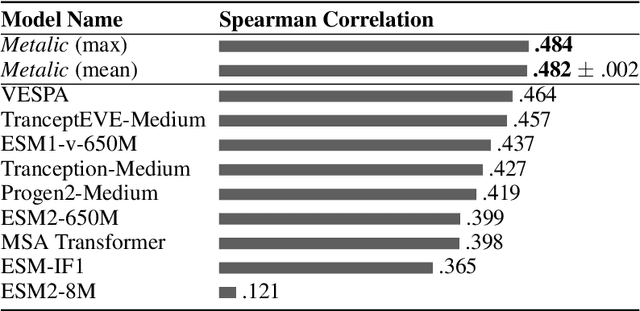
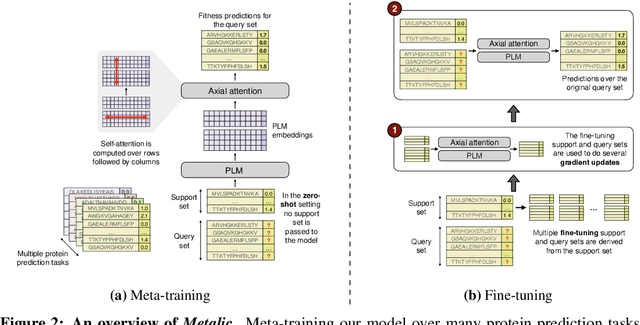

Predicting the biophysical and functional properties of proteins is essential for in silico protein design. Machine learning has emerged as a promising technique for such prediction tasks. However, the relative scarcity of in vitro annotations means that these models often have little, or no, specific data on the desired fitness prediction task. As a result of limited data, protein language models (PLMs) are typically trained on general protein sequence modeling tasks, and then fine-tuned, or applied zero-shot, to protein fitness prediction. When no task data is available, the models make strong assumptions about the correlation between the protein sequence likelihood and fitness scores. In contrast, we propose meta-learning over a distribution of standard fitness prediction tasks, and demonstrate positive transfer to unseen fitness prediction tasks. Our method, called Metalic (Meta-Learning In-Context), uses in-context learning and fine-tuning, when data is available, to adapt to new tasks. Crucially, fine-tuning enables considerable generalization, even though it is not accounted for during meta-training. Our fine-tuned models achieve strong results with 18 times fewer parameters than state-of-the-art models. Moreover, our method sets a new state-of-the-art in low-data settings on ProteinGym, an established fitness-prediction benchmark. Due to data scarcity, we believe meta-learning will play a pivotal role in advancing protein engineering.
Multi-Objective Quality-Diversity for Crystal Structure Prediction
Mar 25, 2024Crystal structures are indispensable across various domains, from batteries to solar cells, and extensive research has been dedicated to predicting their properties based on their atomic configurations. However, prevailing Crystal Structure Prediction methods focus on identifying the most stable solutions that lie at the global minimum of the energy function. This approach overlooks other potentially interesting materials that lie in neighbouring local minima and have different material properties such as conductivity or resistance to deformation. By contrast, Quality-Diversity algorithms provide a promising avenue for Crystal Structure Prediction as they aim to find a collection of high-performing solutions that have diverse characteristics. However, it may also be valuable to optimise for the stability of crystal structures alongside other objectives such as magnetism or thermoelectric efficiency. Therefore, in this work, we harness the power of Multi-Objective Quality-Diversity algorithms in order to find crystal structures which have diverse features and achieve different trade-offs of objectives. We analyse our approach on 5 crystal systems and demonstrate that it is not only able to re-discover known real-life structures, but also find promising new ones. Moreover, we propose a method for illuminating the objective space to gain an understanding of what trade-offs can be achieved.
Combinatorial Optimization with Policy Adaptation using Latent Space Search
Nov 13, 2023Combinatorial Optimization underpins many real-world applications and yet, designing performant algorithms to solve these complex, typically NP-hard, problems remains a significant research challenge. Reinforcement Learning (RL) provides a versatile framework for designing heuristics across a broad spectrum of problem domains. However, despite notable progress, RL has not yet supplanted industrial solvers as the go-to solution. Current approaches emphasize pre-training heuristics that construct solutions but often rely on search procedures with limited variance, such as stochastically sampling numerous solutions from a single policy or employing computationally expensive fine-tuning of the policy on individual problem instances. Building on the intuition that performant search at inference time should be anticipated during pre-training, we propose COMPASS, a novel RL approach that parameterizes a distribution of diverse and specialized policies conditioned on a continuous latent space. We evaluate COMPASS across three canonical problems - Travelling Salesman, Capacitated Vehicle Routing, and Job-Shop Scheduling - and demonstrate that our search strategy (i) outperforms state-of-the-art approaches on 11 standard benchmarking tasks and (ii) generalizes better, surpassing all other approaches on a set of 18 procedurally transformed instance distributions.
Jumanji: a Diverse Suite of Scalable Reinforcement Learning Environments in JAX
Jun 16, 2023Open-source reinforcement learning (RL) environments have played a crucial role in driving progress in the development of AI algorithms. In modern RL research, there is a need for simulated environments that are performant, scalable, and modular to enable their utilization in a wider range of potential real-world applications. Therefore, we present Jumanji, a suite of diverse RL environments specifically designed to be fast, flexible, and scalable. Jumanji provides a suite of environments focusing on combinatorial problems frequently encountered in industry, as well as challenging general decision-making tasks. By leveraging the efficiency of JAX and hardware accelerators like GPUs and TPUs, Jumanji enables rapid iteration of research ideas and large-scale experimentation, ultimately empowering more capable agents. Unlike existing RL environment suites, Jumanji is highly customizable, allowing users to tailor the initial state distribution and problem complexity to their needs. Furthermore, we provide actor-critic baselines for each environment, accompanied by preliminary findings on scaling and generalization scenarios. Jumanji aims to set a new standard for speed, adaptability, and scalability of RL environments.
Efficient Learning of Locomotion Skills through the Discovery of Diverse Environmental Trajectory Generator Priors
Oct 10, 2022

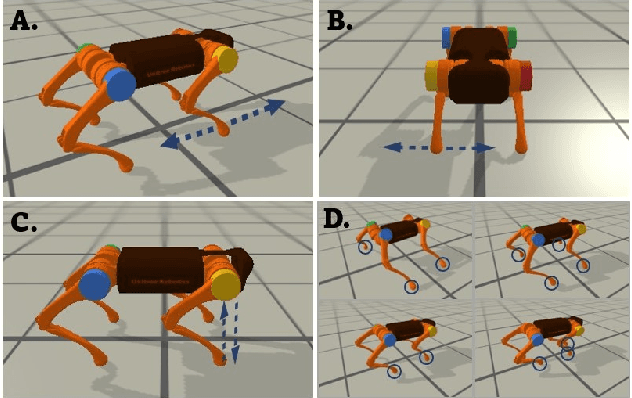
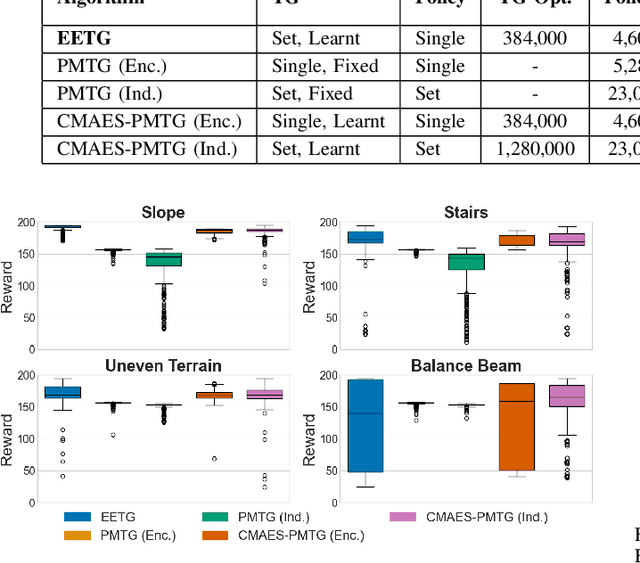
Data-driven learning based methods have recently been particularly successful at learning robust locomotion controllers for a variety of unstructured terrains. Prior work has shown that incorporating good locomotion priors in the form of trajectory generators (TGs) is effective at efficiently learning complex locomotion skills. However, defining a good, single TG as tasks/environments become increasingly more complex remains a challenging problem as it requires extensive tuning and risks reducing the effectiveness of the prior. In this paper, we present Evolved Environmental Trajectory Generators (EETG), a method that learns a diverse set of specialised locomotion priors using Quality-Diversity algorithms while maintaining a single policy within the Policies Modulating TG (PMTG) architecture. The results demonstrate that EETG enables a quadruped robot to successfully traverse a wide range of environments, such as slopes, stairs, rough terrain, and balance beams. Our experiments show that learning a diverse set of specialized TG priors is significantly (5 times) more efficient than using a single, fixed prior when dealing with a wide range of environments.