 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models as In-context AI Generators for Quality-Diversity
Apr 24, 2024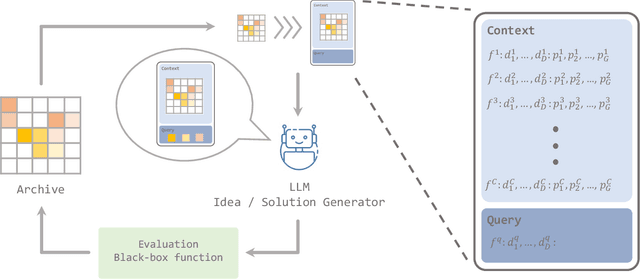
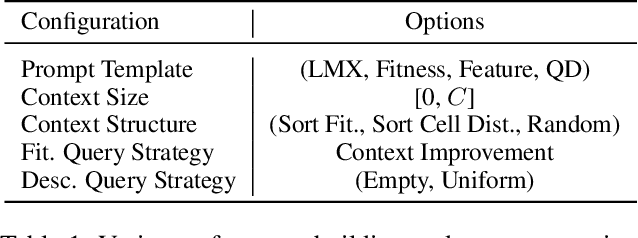
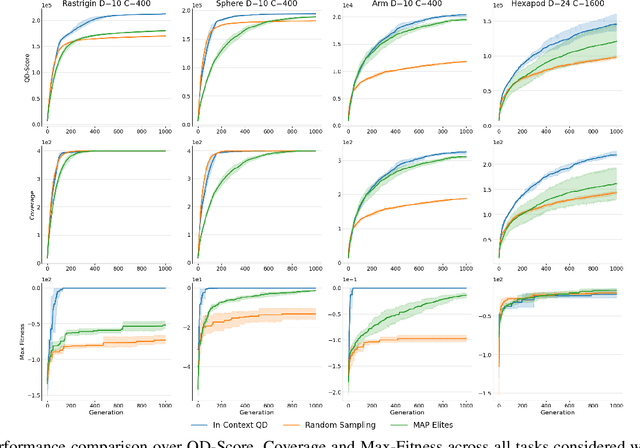

Quality-Diversity (QD) approaches are a promising direction to develop open-ended processes as they can discover archives of high-quality solutions across diverse niches. While already successful in many applications, QD approaches usually rely on combining only one or two solutions to generate new candidate solutions. As observed in open-ended processes such as technological evolution, wisely combining large diversity of these solutions could lead to more innovative solutions and potentially boost the productivity of QD search. In this work, we propose to exploit the pattern-matching capabilities of generative models to enable such efficient solution combinations. We introduce In-context QD, a framework of techniques that aim to elicit the in-context capabilities of pre-trained Large Language Models (LLMs) to generate interesting solutions using the QD archive as context. Applied to a series of common QD domains, In-context QD displays promising results compared to both QD baselines and similar strategies developed for single-objective optimization. Additionally, this result holds across multiple values of parameter sizes and archive population sizes, as well as across domains with distinct characteristics from BBO functions to policy search. Finally, we perform an extensive ablation that highlights the key prompt design considerations that encourage the generation of promising solutions for QD.
Beyond Expected Return: Accounting for Policy Reproducibility when Evaluating Reinforcement Learning Algorithms
Dec 12, 2023Many applications in Reinforcement Learning (RL) usually have noise or stochasticity present in the environment. Beyond their impact on learning, these uncertainties lead the exact same policy to perform differently, i.e. yield different return, from one roll-out to another. Common evaluation procedures in RL summarise the consequent return distributions using solely the expected return, which does not account for the spread of the distribution. Our work defines this spread as the policy reproducibility: the ability of a policy to obtain similar performance when rolled out many times, a crucial property in some real-world applications. We highlight that existing procedures that only use the expected return are limited on two fronts: first an infinite number of return distributions with a wide range of performance-reproducibility trade-offs can have the same expected return, limiting its effectiveness when used for comparing policies; second, the expected return metric does not leave any room for practitioners to choose the best trade-off value for considered applications. In this work, we address these limitations by recommending the use of Lower Confidence Bound, a metric taken from Bayesian optimisation that provides the user with a preference parameter to choose a desired performance-reproducibility trade-off. We also formalise and quantify policy reproducibility, and demonstrate the benefit of our metrics using extensive experiments of popular RL algorithms on common uncertain RL tasks.
Mix-ME: Quality-Diversity for Multi-Agent Learning
Nov 03, 2023In many real-world systems, such as adaptive robotics, achieving a single, optimised solution may be insufficient. Instead, a diverse set of high-performing solutions is often required to adapt to varying contexts and requirements. This is the realm of Quality-Diversity (QD), which aims to discover a collection of high-performing solutions, each with their own unique characteristics. QD methods have recently seen success in many domains, including robotics, where they have been used to discover damage-adaptive locomotion controllers. However, most existing work has focused on single-agent settings, despite many tasks of interest being multi-agent. To this end, we introduce Mix-ME, a novel multi-agent variant of the popular MAP-Elites algorithm that forms new solutions using a crossover-like operator by mixing together agents from different teams. We evaluate the proposed methods on a variety of partially observable continuous control tasks. Our evaluation shows that these multi-agent variants obtained by Mix-ME not only compete with single-agent baselines but also often outperform them in multi-agent settings under partial observability.
QDax: A Library for Quality-Diversity and Population-based Algorithms with Hardware Acceleration
Aug 07, 2023QDax is an open-source library with a streamlined and modular API for Quality-Diversity (QD) optimization algorithms in Jax. The library serves as a versatile tool for optimization purposes, ranging from black-box optimization to continuous control. QDax offers implementations of popular QD, Neuroevolution, and Reinforcement Learning (RL) algorithms, supported by various examples. All the implementations can be just-in-time compiled with Jax, facilitating efficient execution across multiple accelerators, including GPUs and TPUs. These implementations effectively demonstrate the framework's flexibility and user-friendliness, easing experimentation for research purposes. Furthermore, the library is thoroughly documented and tested with 95\% coverage.
Quality-Diversity Optimisation on a Physical Robot Through Dynamics-Aware and Reset-Free Learning
Apr 24, 2023
Learning algorithms, like Quality-Diversity (QD), can be used to acquire repertoires of diverse robotics skills. This learning is commonly done via computer simulation due to the large number of evaluations required. However, training in a virtual environment generates a gap between simulation and reality. Here, we build upon the Reset-Free QD (RF-QD) algorithm to learn controllers directly on a physical robot. This method uses a dynamics model, learned from interactions between the robot and the environment, to predict the robot's behaviour and improve sample efficiency. A behaviour selection policy filters out uninteresting or unsafe policies predicted by the model. RF-QD also includes a recovery policy that returns the robot to a safe zone when it has walked outside of it, allowing continuous learning. We demonstrate that our method enables a physical quadruped robot to learn a repertoire of behaviours in two hours without human supervision. We successfully test the solution repertoire using a maze navigation task. Finally, we compare our approach to the MAP-Elites algorithm. We show that dynamics awareness and a recovery policy are required for training on a physical robot for optimal archive generation. Video available at https://youtu.be/BgGNvIsRh7Q
Don't Bet on Luck Alone: Enhancing Behavioral Reproducibility of Quality-Diversity Solutions in Uncertain Domains
Apr 07, 2023

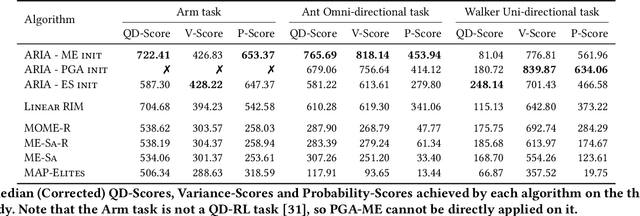
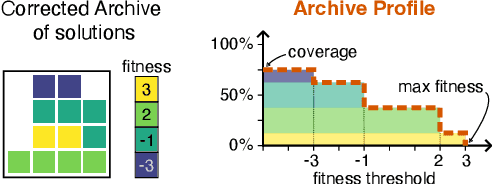
Quality-Diversity (QD) algorithms are designed to generate collections of high-performing solutions while maximizing their diversity in a given descriptor space. However, in the presence of unpredictable noise, the fitness and descriptor of the same solution can differ significantly from one evaluation to another, leading to uncertainty in the estimation of such values. Given the elitist nature of QD algorithms, they commonly end up with many degenerate solutions in such noisy settings. In this work, we introduce Archive Reproducibility Improvement Algorithm (ARIA); a plug-and-play approach that improves the reproducibility of the solutions present in an archive. We propose it as a separate optimization module, relying on natural evolution strategies, that can be executed on top of any QD algorithm. Our module mutates solutions to (1) optimize their probability of belonging to their niche, and (2) maximize their fitness. The performance of our method is evaluated on various tasks, including a classical optimization problem and two high-dimensional control tasks in simulated robotic environments. We show that our algorithm enhances the quality and descriptor space coverage of any given archive by at least 50%.
Understanding the Synergies between Quality-Diversity and Deep Reinforcement Learning
Mar 10, 2023



The synergies between Quality-Diversity (QD) and Deep Reinforcement Learning (RL) have led to powerful hybrid QD-RL algorithms that have shown tremendous potential, and brings the best of both fields. However, only a single deep RL algorithm (TD3) has been used in prior hybrid methods despite notable progress made by other RL algorithms. Additionally, there are fundamental differences in the optimization procedures between QD and RL which would benefit from a more principled approach. We propose Generalized Actor-Critic QD-RL, a unified modular framework for actor-critic deep RL methods in the QD-RL setting. This framework provides a path to study insights from Deep RL in the QD-RL setting, which is an important and efficient way to make progress in QD-RL. We introduce two new algorithms, PGA-ME (SAC) and PGA-ME (DroQ) which apply recent advancements in Deep RL to the QD-RL setting, and solves the humanoid environment which was not possible using existing QD-RL algorithms. However, we also find that not all insights from Deep RL can be effectively translated to QD-RL. Critically, this work also demonstrates that the actor-critic models in QD-RL are generally insufficiently trained and performance gains can be achieved without any additional environment evaluations.
Multiple Hands Make Light Work: Enhancing Quality and Diversity using MAP-Elites with Multiple Parallel Evolution Strategies
Mar 10, 2023



With the development of hardware accelerators and their corresponding tools, evaluations have become more affordable through fast and massively parallel evaluations in some applications. This advancement has drastically sped up the runtime of evolution-inspired algorithms such as Quality-Diversity optimization, creating tremendous potential for algorithmic innovation through scale. In this work, we propose MAP-Elites-Multi-ES (MEMES), a novel QD algorithm based on Evolution Strategies (ES) designed for fast parallel evaluations. ME-Multi-ES builds on top of the existing MAP-Elites-ES algorithm, scaling it by maintaining multiple independent ES threads with massive parallelization. We also introduce a new dynamic reset procedure for the lifespan of the independent ES to autonomously maximize the improvement of the QD population. We show experimentally that MEMES outperforms existing gradient-based and objective-agnostic QD algorithms when compared in terms of generations. We perform this comparison on both black-box optimization and QD-Reinforcement Learning tasks, demonstrating the benefit of our approach across different problems and domains. Finally, we also find that our approach intrinsically enables optimization of fitness locally around a niche, a phenomenon not observed in other QD algorithms.
Efficient Exploration using Model-Based Quality-Diversity with Gradients
Nov 22, 2022Exploration is a key challenge in Reinforcement Learning, especially in long-horizon, deceptive and sparse-reward environments. For such applications, population-based approaches have proven effective. Methods such as Quality-Diversity deals with this by encouraging novel solutions and producing a diversity of behaviours. However, these methods are driven by either undirected sampling (i.e. mutations) or use approximated gradients (i.e. Evolution Strategies) in the parameter space, which makes them highly sample-inefficient. In this paper, we propose a model-based Quality-Diversity approach. It extends existing QD methods to use gradients for efficient exploitation and leverage perturbations in imagination for efficient exploration. Our approach optimizes all members of a population simultaneously to maintain both performance and diversity efficiently by leveraging the effectiveness of QD algorithms as good data generators to train deep models. We demonstrate that it maintains the divergent search capabilities of population-based approaches on tasks with deceptive rewards while significantly improving their sample efficiency and quality of solutions.
Benchmarking Quality-Diversity Algorithms on Neuroevolution for Reinforcement Learning
Nov 04, 2022We present a Quality-Diversity benchmark suite for Deep Neuroevolution in Reinforcement Learning domains for robot control. The suite includes the definition of tasks, environments, behavioral descriptors, and fitness. We specify different benchmarks based on the complexity of both the task and the agent controlled by a deep neural network. The benchmark uses standard Quality-Diversity metrics, including coverage, QD-score, maximum fitness, and an archive profile metric to quantify the relation between coverage and fitness. We also present how to quantify the robustness of the solutions with respect to environmental stochasticity by introducing corrected versions of the same metrics. We believe that our benchmark is a valuable tool for the community to compare and improve their findings. The source code is available online: https://github.com/adaptive-intelligent-robotics/QDax