 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscrete Gene Crossover Accelerates Solution Discovery in Quality-Diversity Algorithms
Feb 14, 2026Quality-Diversity (QD) algorithms aim to discover diverse, high-performing solutions across behavioral niches. However, QD search often stagnates as incremental variation operators struggle to propagate building blocks across large populations. Existing mutation operators rely on gradual variation to solutions, limiting their ability to efficiently explore regions of the search space distant from parent solutions or to spread beneficial genetic material through the population. We propose a mutation operator which augments variation-based operators with discrete, gene-level crossover, enabling rapid recombination of elite genetic material. This crossover mechanism mirrors the biological principle of meiosis and facilitates both the direct transfer of genetic material and the exploration of novel genotype configurations beyond the existing elite hypervolume. We evaluate operators on three locomotion environments, demonstrating improvements in QD score, coverage, and max fitness, with particularly strong performance in later stages of optimization once building blocks have been established in the archive. These results show that the addition of a discrete crossover mutation provides a complementary exploration mechanism that sustains quality-diversity growth beyond the performance demonstrated by existing operators.
Efficient and Diverse Generative Robot Designs using Evolution and Intrinsic Motivation
Dec 03, 2024Methods for generative design of robot physical configurations can automatically find optimal and innovative solutions for challenging tasks in complex environments. The vast search-space includes the physical design-space and the controller parameter-space, making it a challenging problem in machine learning and optimisation in general. Evolutionary algorithms (EAs) have shown promising results in generating robot designs via gradient-free optimisation. Morpho-evolution with learning (MEL) uses EAs to concurrently generate robot designs and learn the optimal parameters of the controllers. Two main issues prevent MEL from scaling to higher complexity tasks: computational cost and premature convergence to sub-optimal designs. To address these issues, we propose combining morpho-evolution with intrinsic motivations. Intrinsically motivated behaviour arises from embodiment and simple learning rules without external guidance. We use a homeokinetic controller that generates exploratory behaviour in a few seconds with reduced knowledge of the robot's design. Homeokinesis replaces costly learning phases, reducing computational time and favouring diversity, preventing premature convergence. We compare our approach with current MEL methods in several downstream tasks. The generated designs score higher in all the tasks, are more diverse, and are quickly generated compared to morpho-evolution with static parameters.
Quality-Diversity Optimisation on a Physical Robot Through Dynamics-Aware and Reset-Free Learning
Apr 24, 2023
Learning algorithms, like Quality-Diversity (QD), can be used to acquire repertoires of diverse robotics skills. This learning is commonly done via computer simulation due to the large number of evaluations required. However, training in a virtual environment generates a gap between simulation and reality. Here, we build upon the Reset-Free QD (RF-QD) algorithm to learn controllers directly on a physical robot. This method uses a dynamics model, learned from interactions between the robot and the environment, to predict the robot's behaviour and improve sample efficiency. A behaviour selection policy filters out uninteresting or unsafe policies predicted by the model. RF-QD also includes a recovery policy that returns the robot to a safe zone when it has walked outside of it, allowing continuous learning. We demonstrate that our method enables a physical quadruped robot to learn a repertoire of behaviours in two hours without human supervision. We successfully test the solution repertoire using a maze navigation task. Finally, we compare our approach to the MAP-Elites algorithm. We show that dynamics awareness and a recovery policy are required for training on a physical robot for optimal archive generation. Video available at https://youtu.be/BgGNvIsRh7Q
Benchmarking Quality-Diversity Algorithms on Neuroevolution for Reinforcement Learning
Nov 04, 2022


We present a Quality-Diversity benchmark suite for Deep Neuroevolution in Reinforcement Learning domains for robot control. The suite includes the definition of tasks, environments, behavioral descriptors, and fitness. We specify different benchmarks based on the complexity of both the task and the agent controlled by a deep neural network. The benchmark uses standard Quality-Diversity metrics, including coverage, QD-score, maximum fitness, and an archive profile metric to quantify the relation between coverage and fitness. We also present how to quantify the robustness of the solutions with respect to environmental stochasticity by introducing corrected versions of the same metrics. We believe that our benchmark is a valuable tool for the community to compare and improve their findings. The source code is available online: https://github.com/adaptive-intelligent-robotics/QDax
Online Damage Recovery for Physical Robots with Hierarchical Quality-Diversity
Oct 18, 2022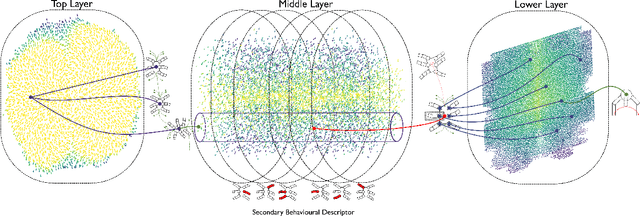


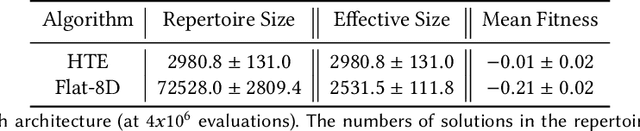
In real-world environments, robots need to be resilient to damages and robust to unforeseen scenarios. Quality-Diversity (QD) algorithms have been successfully used to make robots adapt to damages in seconds by leveraging a diverse set of learned skills. A high diversity of skills increases the chances of a robot to succeed at overcoming new situations since there are more potential alternatives to solve a new task.However, finding and storing a large behavioural diversity of multiple skills often leads to an increase in computational complexity. Furthermore, robot planning in a large skill space is an additional challenge that arises with an increased number of skills. Hierarchical structures can help reducing this search and storage complexity by breaking down skills into primitive skills. In this paper, we introduce the Hierarchical Trial and Error algorithm, which uses a hierarchical behavioural repertoire to learn diverse skills and leverages them to make the robot adapt quickly in the physical world. We show that the hierarchical decomposition of skills enables the robot to learn more complex behaviours while keeping the learning of the repertoire tractable. Experiments with a hexapod robot show that our method solves a maze navigation tasks with 20% less actions in simulation, and 43% less actions in the physical world, for the most challenging scenarios than the best baselines while having 78% less complete failures.
Hierarchical Quality-Diversity for Online Damage Recovery
Apr 12, 2022
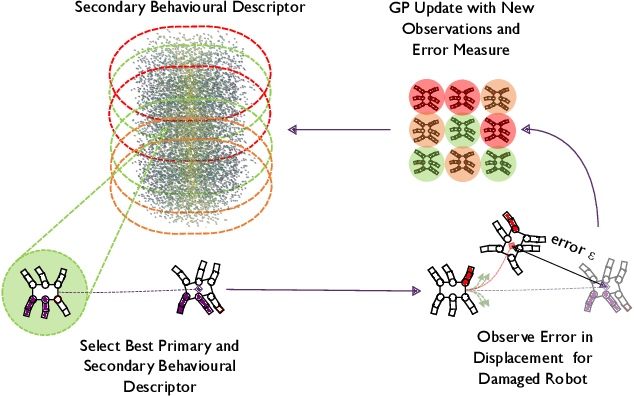
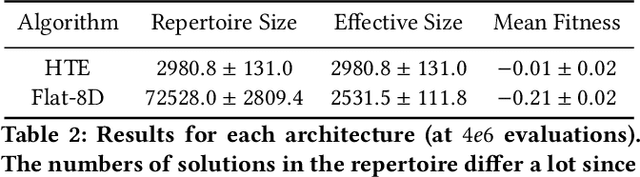

Adaptation capabilities, like damage recovery, are crucial for the deployment of robots in complex environments. Several works have demonstrated that using repertoires of pre-trained skills can enable robots to adapt to unforeseen mechanical damages in a few minutes. These adaptation capabilities are directly linked to the behavioural diversity in the repertoire. The more alternatives the robot has to execute a skill, the better are the chances that it can adapt to a new situation. However, solving complex tasks, like maze navigation, usually requires multiple different skills. Finding a large behavioural diversity for these multiple skills often leads to an intractable exponential growth of the number of required solutions. In this paper, we introduce the Hierarchical Trial and Error algorithm, which uses a hierarchical behavioural repertoire to learn diverse skills and leverages them to make the robot more adaptive to different situations. We show that the hierarchical decomposition of skills enables the robot to learn more complex behaviours while keeping the learning of the repertoire tractable. The experiments with a hexapod robot show that our method solves maze navigation tasks with 20% less actions in the most challenging scenarios than the best baseline while having 57% less complete failures.
Attainment Regions in Feature-Parameter Space for High-Level Debugging in Autonomous Robots
Aug 06, 2021
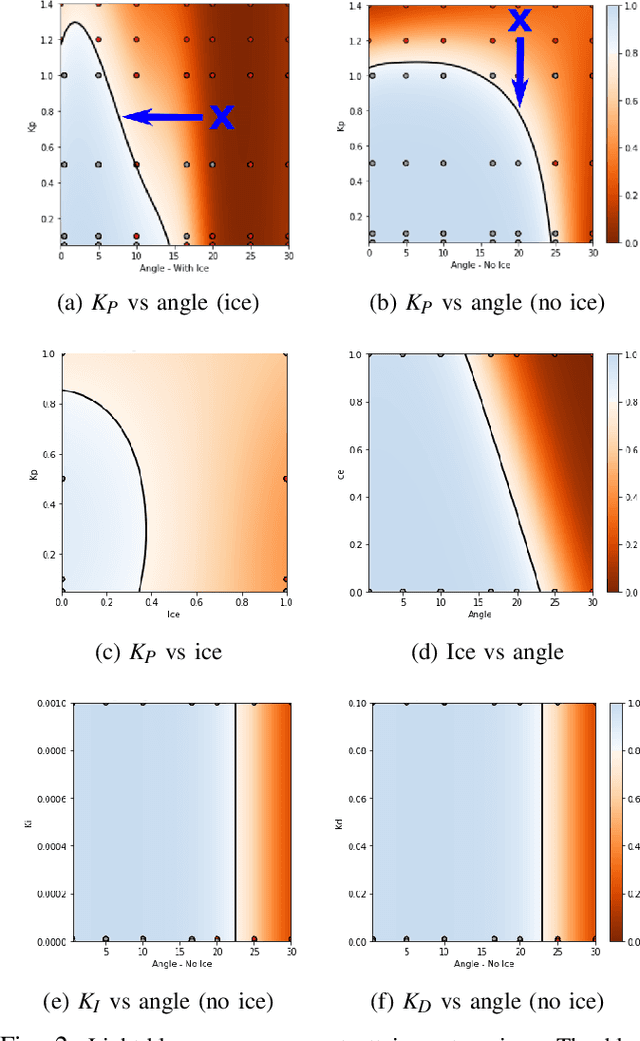

Understanding a controller's performance in different scenarios is crucial for robots that are going to be deployed in safety-critical tasks. If we do not have a model of the dynamics of the world, which is often the case in complex domains, we may need to approximate a performance function of the robot based on its interaction with the environment. Such a performance function gives us insights into the behaviour of the robot, allowing us to fine-tune the controller with manual interventions. In high-dimensionality systems, where the actionstate space is large, fine-tuning a controller is non-trivial. To overcome this problem, we propose a performance function whose domain is defined by external features and parameters of the controller. Attainment regions are defined over such a domain defined by feature-parameter pairs, and serve the purpose of enabling prediction of successful execution of the task. The use of the feature-parameter space -in contrast to the action-state space- allows us to adapt, explain and finetune the controller over a simpler (i.e., lower dimensional space). When the robot successfully executes the task, we use the attainment regions to gain insights into the limits of the controller, and its robustness. When the robot fails to execute the task, we use the regions to debug the controller and find adaptive and counterfactual changes to the solutions. Another advantage of this approach is that we can generalise through the use of Gaussian processes regression of the performance function in the high-dimensional space. To test our approach, we demonstrate learning an approximation to the performance function in simulation, with a mobile robot traversing different terrain conditions. Then, with a sample-efficient method, we propagate the attainment regions to a physical robot in a similar environment.
Counterfactual Explanation and Causal Inference in Service of Robustness in Robot Control
Sep 22, 2020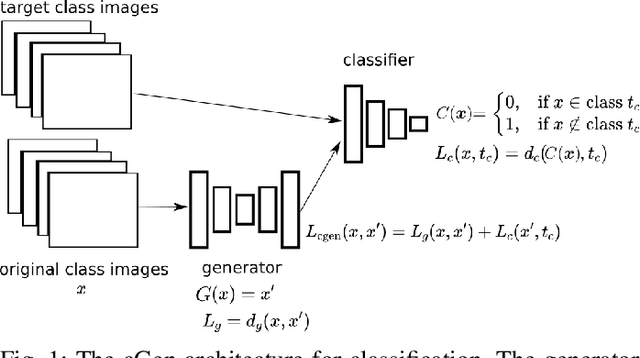



We propose an architecture for training generative models of counterfactual conditionals of the form, 'can we modify event A to cause B instead of C?', motivated by applications in robot control. Using an 'adversarial training' paradigm, an image-based deep neural network model is trained to produce small and realistic modifications to an original image in order to cause user-defined effects. These modifications can be used in the design process of image-based robust control - to determine the ability of the controller to return to a working regime by modifications in the input space, rather than by adaptation. In contrast to conventional control design approaches, where robustness is quantified in terms of the ability to reject noise, we explore the space of counterfactuals that might cause a certain requirement to be violated, thus proposing an alternative model that might be more expressive in certain robotics applications. So, we propose the generation of counterfactuals as an approach to explanation of black-box models and the envisioning of potential movement paths in autonomous robotic control. Firstly, we demonstrate this approach in a set of classification tasks, using the well known MNIST and CelebFaces Attributes datasets. Then, addressing multi-dimensional regression, we demonstrate our approach in a reaching task with a physical robot, and in a navigation task with a robot in a digital twin simulation.
Semi-supervised Learning From Demonstration Through Program Synthesis: An Inspection Robot Case Study
Jul 23, 2020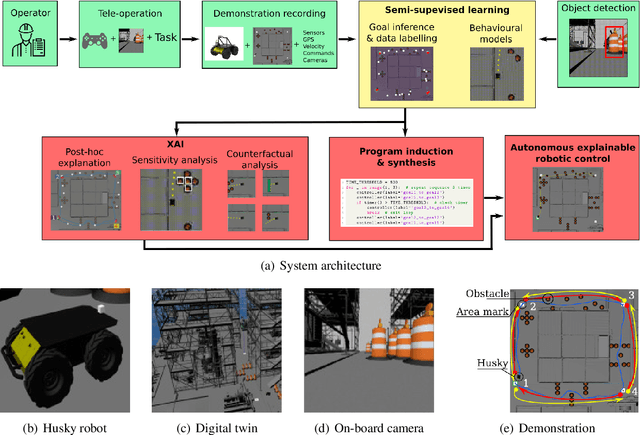
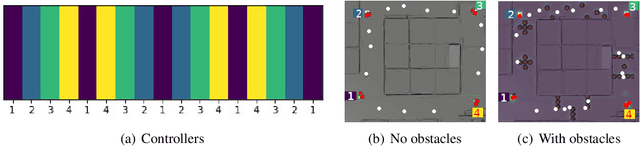
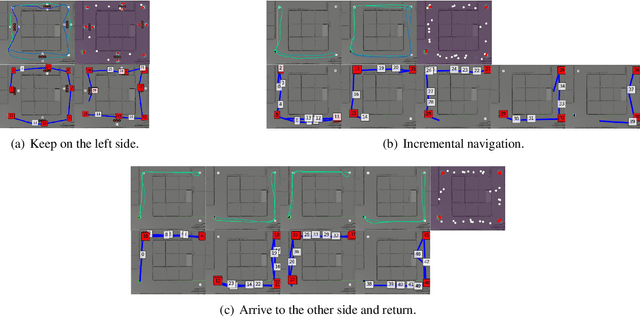
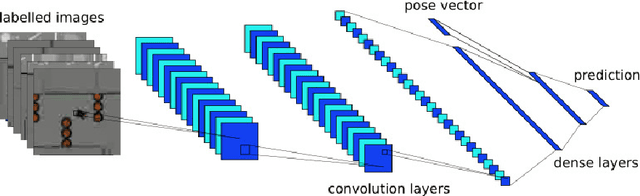
Semi-supervised learning improves the performance of supervised machine learning by leveraging methods from unsupervised learning to extract information not explicitly available in the labels. Through the design of a system that enables a robot to learn inspection strategies from a human operator, we present a hybrid semi-supervised system capable of learning interpretable and verifiable models from demonstrations. The system induces a controller program by learning from immersive demonstrations using sequential importance sampling. These visual servo controllers are parametrised by proportional gains and are visually verifiable through observation of the position of the robot in the environment. Clustering and effective particle size filtering allows the system to discover goals in the state space. These goals are used to label the original demonstration for end-to-end learning of behavioural models. The behavioural models are used for autonomous model predictive control and scrutinised for explanations. We implement causal sensitivity analysis to identify salient objects and generate counterfactual conditional explanations. These features enable decision making interpretation and post hoc discovery of the causes of a failure. The proposed system expands on previous approaches to program synthesis by incorporating repellers in the attribution prior of the sampling process. We successfully learn the hybrid system from an inspection scenario where an unmanned ground vehicle has to inspect, in a specific order, different areas of the environment. The system induces an interpretable computer program of the demonstration that can be synthesised to produce novel inspection behaviours. Importantly, the robot successfully runs the synthesised program on an unseen configuration of the environment while presenting explanations of its autonomous behaviour.
* In Proceedings AREA 2020, arXiv:2007.11260
Expanding the Active Inference Landscape: More Intrinsic Motivations in the Perception-Action Loop
Jun 21, 2018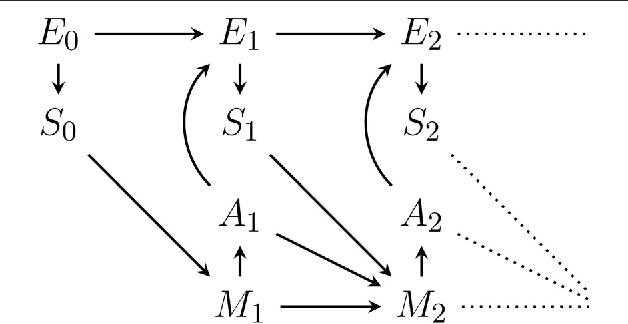
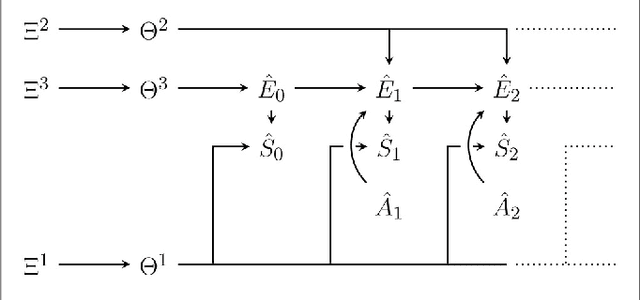
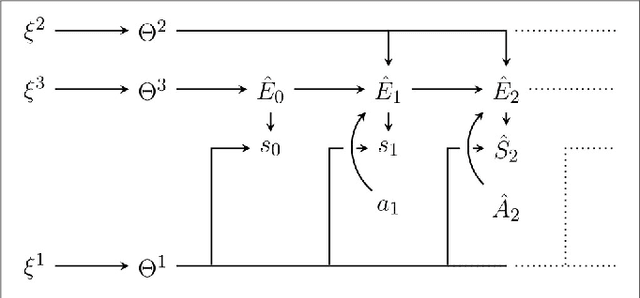
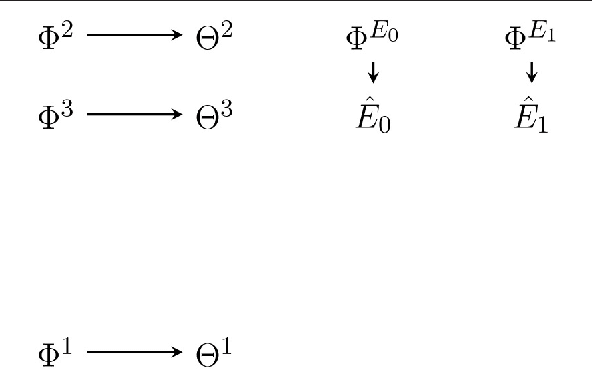
Active inference is an ambitious theory that treats perception, inference and action selection of autonomous agents under the heading of a single principle. It suggests biologically plausible explanations for many cognitive phenomena, including consciousness. In active inference, action selection is driven by an objective function that evaluates possible future actions with respect to current, inferred beliefs about the world. Active inference at its core is independent from extrinsic rewards, resulting in a high level of robustness across e.g.\ different environments or agent morphologies. In the literature, paradigms that share this independence have been summarised under the notion of intrinsic motivations. In general and in contrast to active inference, these models of motivation come without a commitment to particular inference and action selection mechanisms. In this article, we study if the inference and action selection machinery of active inference can also be used by alternatives to the originally included intrinsic motivation. The perception-action loop explicitly relates inference and action selection to the environment and agent memory, and is consequently used as foundation for our analysis. We reconstruct the active inference approach, locate the original formulation within, and show how alternative intrinsic motivations can be used while keeping many of the original features intact. Furthermore, we illustrate the connection to universal reinforcement learning by means of our formalism. Active inference research may profit from comparisons of the dynamics induced by alternative intrinsic motivations. Research on intrinsic motivations may profit from an additional way to implement intrinsically motivated agents that also share the biological plausibility of active inference.