 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHelix-mRNA: A Hybrid Foundation Model For Full Sequence mRNA Therapeutics
Feb 19, 2025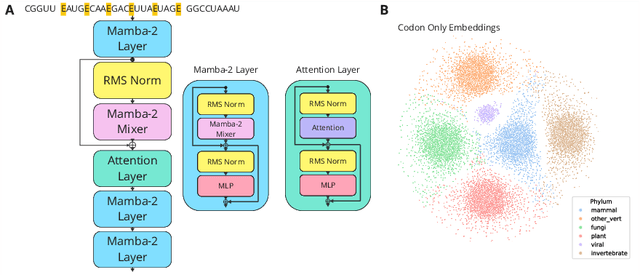


mRNA-based vaccines have become a major focus in the pharmaceutical industry. The coding sequence as well as the Untranslated Regions (UTRs) of an mRNA can strongly influence translation efficiency, stability, degradation, and other factors that collectively determine a vaccine's effectiveness. However, optimizing mRNA sequences for those properties remains a complex challenge. Existing deep learning models often focus solely on coding region optimization, overlooking the UTRs. We present Helix-mRNA, a structured state-space-based and attention hybrid model to address these challenges. In addition to a first pre-training, a second pre-training stage allows us to specialise the model with high-quality data. We employ single nucleotide tokenization of mRNA sequences with codon separation, ensuring prior biological and structural information from the original mRNA sequence is not lost. Our model, Helix-mRNA, outperforms existing methods in analysing both UTRs and coding region properties. It can process sequences 6x longer than current approaches while using only 10% of the parameters of existing foundation models. Its predictive capabilities extend to all mRNA regions. We open-source the model (https://github.com/helicalAI/helical) and model weights (https://huggingface.co/helical-ai/helix-mRNA).
QDax: A Library for Quality-Diversity and Population-based Algorithms with Hardware Acceleration
Aug 07, 2023QDax is an open-source library with a streamlined and modular API for Quality-Diversity (QD) optimization algorithms in Jax. The library serves as a versatile tool for optimization purposes, ranging from black-box optimization to continuous control. QDax offers implementations of popular QD, Neuroevolution, and Reinforcement Learning (RL) algorithms, supported by various examples. All the implementations can be just-in-time compiled with Jax, facilitating efficient execution across multiple accelerators, including GPUs and TPUs. These implementations effectively demonstrate the framework's flexibility and user-friendliness, easing experimentation for research purposes. Furthermore, the library is thoroughly documented and tested with 95\% coverage.
Benchmarking Quality-Diversity Algorithms on Neuroevolution for Reinforcement Learning
Nov 04, 2022


We present a Quality-Diversity benchmark suite for Deep Neuroevolution in Reinforcement Learning domains for robot control. The suite includes the definition of tasks, environments, behavioral descriptors, and fitness. We specify different benchmarks based on the complexity of both the task and the agent controlled by a deep neural network. The benchmark uses standard Quality-Diversity metrics, including coverage, QD-score, maximum fitness, and an archive profile metric to quantify the relation between coverage and fitness. We also present how to quantify the robustness of the solutions with respect to environmental stochasticity by introducing corrected versions of the same metrics. We believe that our benchmark is a valuable tool for the community to compare and improve their findings. The source code is available online: https://github.com/adaptive-intelligent-robotics/QDax
Online Damage Recovery for Physical Robots with Hierarchical Quality-Diversity
Oct 18, 2022


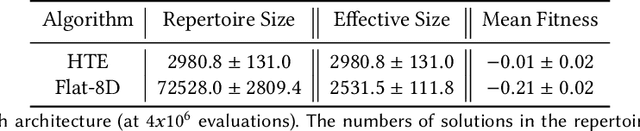
In real-world environments, robots need to be resilient to damages and robust to unforeseen scenarios. Quality-Diversity (QD) algorithms have been successfully used to make robots adapt to damages in seconds by leveraging a diverse set of learned skills. A high diversity of skills increases the chances of a robot to succeed at overcoming new situations since there are more potential alternatives to solve a new task.However, finding and storing a large behavioural diversity of multiple skills often leads to an increase in computational complexity. Furthermore, robot planning in a large skill space is an additional challenge that arises with an increased number of skills. Hierarchical structures can help reducing this search and storage complexity by breaking down skills into primitive skills. In this paper, we introduce the Hierarchical Trial and Error algorithm, which uses a hierarchical behavioural repertoire to learn diverse skills and leverages them to make the robot adapt quickly in the physical world. We show that the hierarchical decomposition of skills enables the robot to learn more complex behaviours while keeping the learning of the repertoire tractable. Experiments with a hexapod robot show that our method solves a maze navigation tasks with 20% less actions in simulation, and 43% less actions in the physical world, for the most challenging scenarios than the best baselines while having 78% less complete failures.
Neuroevolution is a Competitive Alternative to Reinforcement Learning for Skill Discovery
Oct 06, 2022
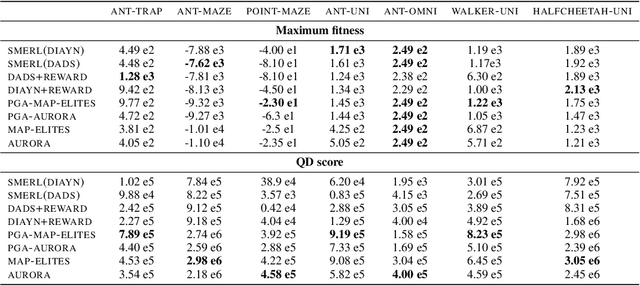
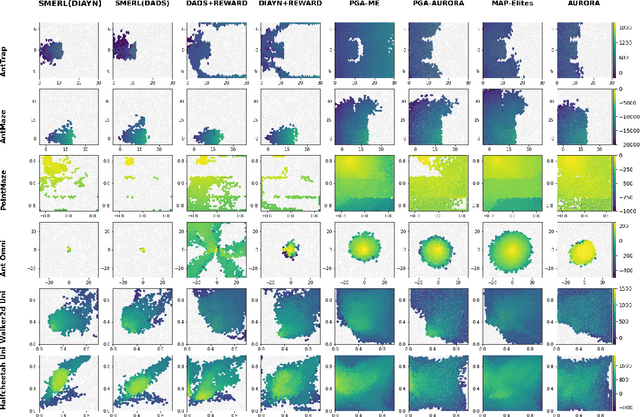
Deep Reinforcement Learning (RL) has emerged as a powerful paradigm for training neural policies to solve complex control tasks. However, these policies tend to be overfit to the exact specifications of the task and environment they were trained on, and thus do not perform well when conditions deviate slightly or when composed hierarchically to solve even more complex tasks. Recent work has shown that training a mixture of policies, as opposed to a single one, that are driven to explore different regions of the state-action space can address this shortcoming by generating a diverse set of behaviors, referred to as skills, that can be collectively used to great effect in adaptation tasks or for hierarchical planning. This is typically realized by including a diversity term - often derived from information theory - in the objective function optimized by RL. However these approaches often require careful hyperparameter tuning to be effective. In this work, we demonstrate that less widely-used neuroevolution methods, specifically Quality Diversity (QD), are a competitive alternative to information-theory-augmented RL for skill discovery. Through an extensive empirical evaluation comparing eight state-of-the-art methods on the basis of (i) metrics directly evaluating the skills' diversity, (ii) the skills' performance on adaptation tasks, and (iii) the skills' performance when used as primitives for hierarchical planning; QD methods are found to provide equal, and sometimes improved, performance whilst being less sensitive to hyperparameters and more scalable. As no single method is found to provide near-optimal performance across all environments, there is a rich scope for further research which we support by proposing future directions and providing optimized open-source implementations.
Hierarchical Quality-Diversity for Online Damage Recovery
Apr 12, 2022
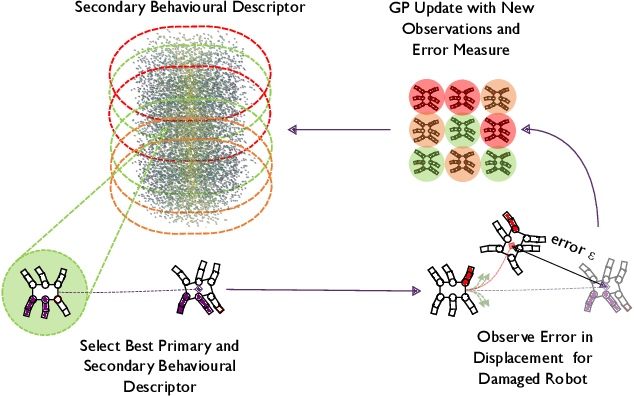
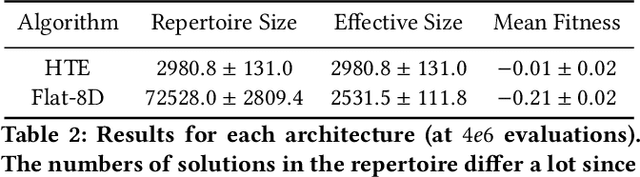

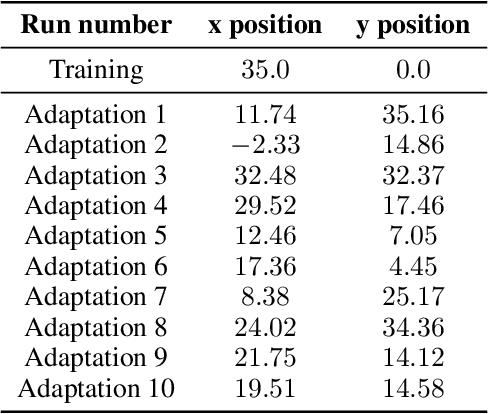
Adaptation capabilities, like damage recovery, are crucial for the deployment of robots in complex environments. Several works have demonstrated that using repertoires of pre-trained skills can enable robots to adapt to unforeseen mechanical damages in a few minutes. These adaptation capabilities are directly linked to the behavioural diversity in the repertoire. The more alternatives the robot has to execute a skill, the better are the chances that it can adapt to a new situation. However, solving complex tasks, like maze navigation, usually requires multiple different skills. Finding a large behavioural diversity for these multiple skills often leads to an intractable exponential growth of the number of required solutions. In this paper, we introduce the Hierarchical Trial and Error algorithm, which uses a hierarchical behavioural repertoire to learn diverse skills and leverages them to make the robot more adaptive to different situations. We show that the hierarchical decomposition of skills enables the robot to learn more complex behaviours while keeping the learning of the repertoire tractable. The experiments with a hexapod robot show that our method solves maze navigation tasks with 20% less actions in the most challenging scenarios than the best baseline while having 57% less complete failures.
Accelerated Quality-Diversity for Robotics through Massive Parallelism
Feb 02, 2022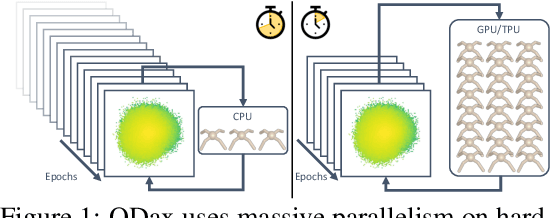
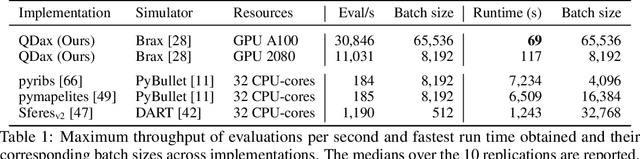
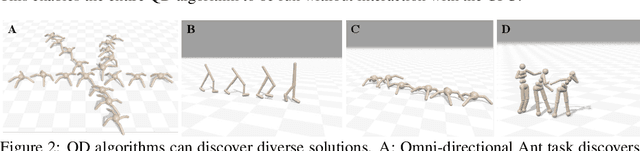
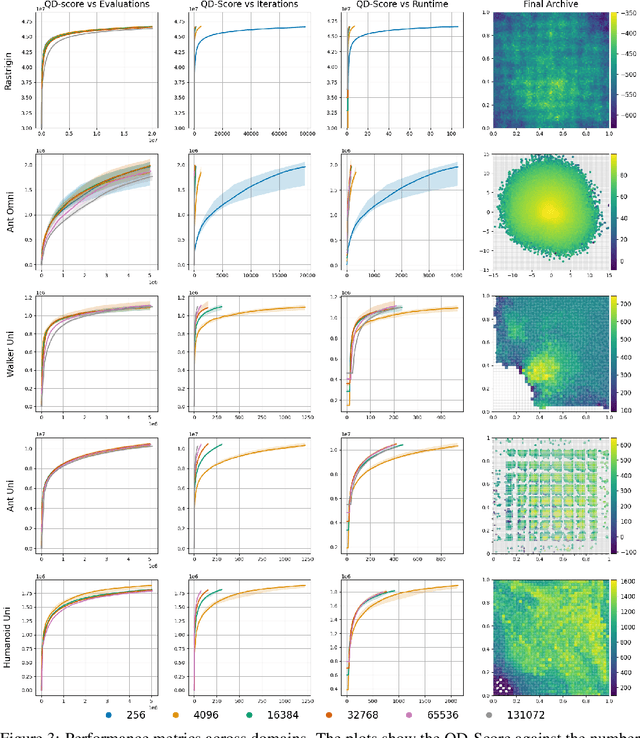
Quality-Diversity (QD) algorithms are a well-known approach to generate large collections of diverse and high-quality policies. However, QD algorithms are also known to be data-inefficient, requiring large amounts of computational resources and are slow when used in practice for robotics tasks. Policy evaluations are already commonly performed in parallel to speed up QD algorithms but have limited capabilities on a single machine as most physics simulators run on CPUs. With recent advances in simulators that run on accelerators, thousands of evaluations can performed in parallel on single GPU/TPU. In this paper, we present QDax, an implementation of MAP-Elites which leverages massive parallelism on accelerators to make QD algorithms more accessible. We first demonstrate the improvements on the number of evaluations per second that parallelism using accelerated simulators can offer. More importantly, we show that QD algorithms are ideal candidates and can scale with massive parallelism to be run at interactive timescales. The increase in parallelism does not significantly affect the performance of QD algorithms, while reducing experiment runtimes by two factors of magnitudes, turning days of computation into minutes. These results show that QD can now benefit from hardware acceleration, which contributed significantly to the bloom of deep learning.