 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQDax: A Library for Quality-Diversity and Population-based Algorithms with Hardware Acceleration
Aug 07, 2023QDax is an open-source library with a streamlined and modular API for Quality-Diversity (QD) optimization algorithms in Jax. The library serves as a versatile tool for optimization purposes, ranging from black-box optimization to continuous control. QDax offers implementations of popular QD, Neuroevolution, and Reinforcement Learning (RL) algorithms, supported by various examples. All the implementations can be just-in-time compiled with Jax, facilitating efficient execution across multiple accelerators, including GPUs and TPUs. These implementations effectively demonstrate the framework's flexibility and user-friendliness, easing experimentation for research purposes. Furthermore, the library is thoroughly documented and tested with 95\% coverage.
PASTA: Pretrained Action-State Transformer Agents
Jul 20, 2023



Self-supervised learning has brought about a revolutionary paradigm shift in various computing domains, including NLP, vision, and biology. Recent approaches involve pre-training transformer models on vast amounts of unlabeled data, serving as a starting point for efficiently solving downstream tasks. In the realm of reinforcement learning, researchers have recently adapted these approaches by developing models pre-trained on expert trajectories, enabling them to address a wide range of tasks, from robotics to recommendation systems. However, existing methods mostly rely on intricate pre-training objectives tailored to specific downstream applications. This paper presents a comprehensive investigation of models we refer to as Pretrained Action-State Transformer Agents (PASTA). Our study uses a unified methodology and covers an extensive set of general downstream tasks including behavioral cloning, offline RL, sensor failure robustness, and dynamics change adaptation. Our goal is to systematically compare various design choices and provide valuable insights to practitioners for building robust models. Key highlights of our study include tokenization at the action and state component level, using fundamental pre-training objectives like next token prediction, training models across diverse domains simultaneously, and using parameter efficient fine-tuning (PEFT). The developed models in our study contain fewer than 10 million parameters and the application of PEFT enables fine-tuning of fewer than 10,000 parameters during downstream adaptation, allowing a broad community to use these models and reproduce our experiments. We hope that this study will encourage further research into the use of transformers with first-principles design choices to represent RL trajectories and contribute to robust policy learning.
Assessing Quality-Diversity Neuro-Evolution Algorithms Performance in Hard Exploration Problems
Nov 24, 2022A fascinating aspect of nature lies in its ability to produce a collection of organisms that are all high-performing in their niche. Quality-Diversity (QD) methods are evolutionary algorithms inspired by this observation, that obtained great results in many applications, from wing design to robot adaptation. Recently, several works demonstrated that these methods could be applied to perform neuro-evolution to solve control problems in large search spaces. In such problems, diversity can be a target in itself. Diversity can also be a way to enhance exploration in tasks exhibiting deceptive reward signals. While the first aspect has been studied in depth in the QD community, the latter remains scarcer in the literature. Exploration is at the heart of several domains trying to solve control problems such as Reinforcement Learning and QD methods are promising candidates to overcome the challenges associated. Therefore, we believe that standardized benchmarks exhibiting control problems in high dimension with exploration difficulties are of interest to the QD community. In this paper, we highlight three candidate benchmarks and explain why they appear relevant for systematic evaluation of QD algorithms. We also provide open-source implementations in Jax allowing practitioners to run fast and numerous experiments on few compute resources.
Neuroevolution is a Competitive Alternative to Reinforcement Learning for Skill Discovery
Oct 06, 2022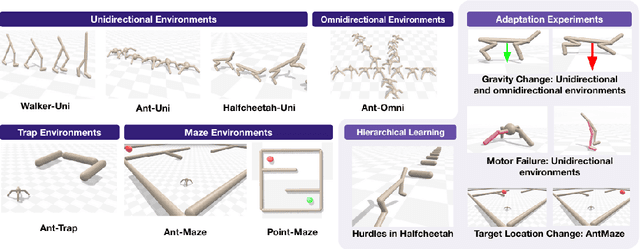
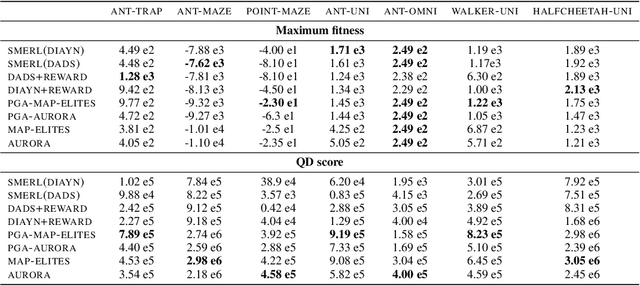
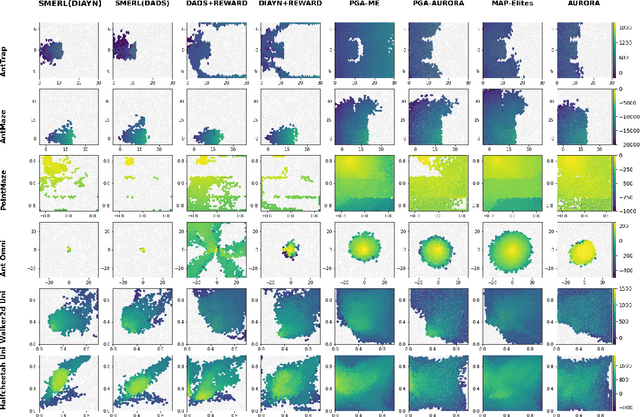
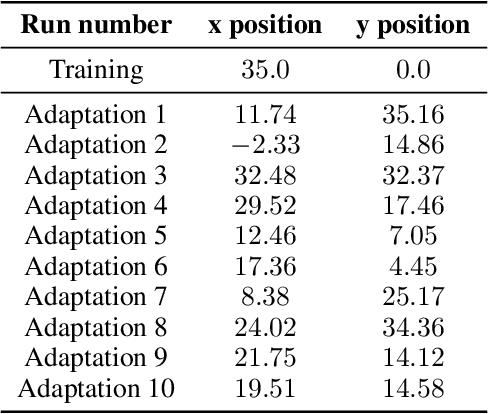
Deep Reinforcement Learning (RL) has emerged as a powerful paradigm for training neural policies to solve complex control tasks. However, these policies tend to be overfit to the exact specifications of the task and environment they were trained on, and thus do not perform well when conditions deviate slightly or when composed hierarchically to solve even more complex tasks. Recent work has shown that training a mixture of policies, as opposed to a single one, that are driven to explore different regions of the state-action space can address this shortcoming by generating a diverse set of behaviors, referred to as skills, that can be collectively used to great effect in adaptation tasks or for hierarchical planning. This is typically realized by including a diversity term - often derived from information theory - in the objective function optimized by RL. However these approaches often require careful hyperparameter tuning to be effective. In this work, we demonstrate that less widely-used neuroevolution methods, specifically Quality Diversity (QD), are a competitive alternative to information-theory-augmented RL for skill discovery. Through an extensive empirical evaluation comparing eight state-of-the-art methods on the basis of (i) metrics directly evaluating the skills' diversity, (ii) the skills' performance on adaptation tasks, and (iii) the skills' performance when used as primitives for hierarchical planning; QD methods are found to provide equal, and sometimes improved, performance whilst being less sensitive to hyperparameters and more scalable. As no single method is found to provide near-optimal performance across all environments, there is a rich scope for further research which we support by proposing future directions and providing optimized open-source implementations.
Fast Population-Based Reinforcement Learning on a Single Machine
Jun 17, 2022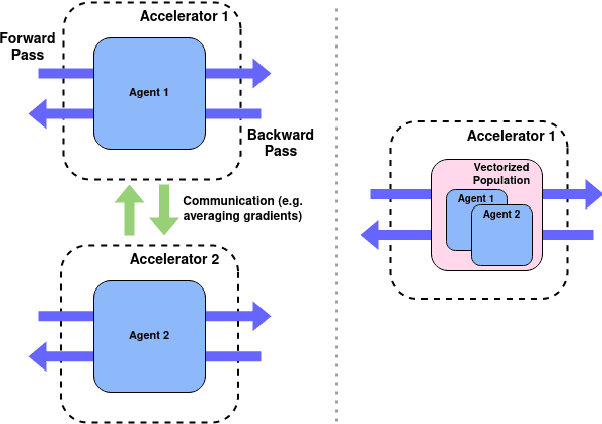

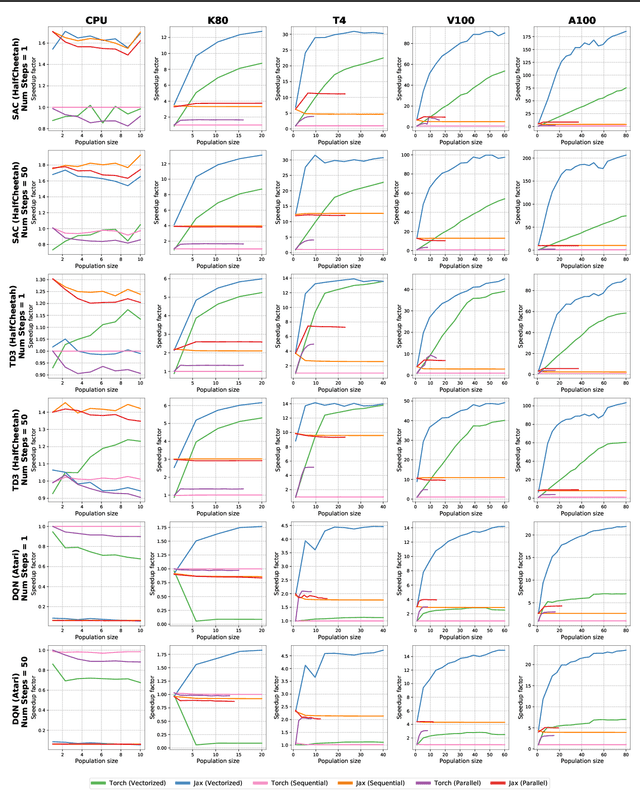

Training populations of agents has demonstrated great promise in Reinforcement Learning for stabilizing training, improving exploration and asymptotic performance, and generating a diverse set of solutions. However, population-based training is often not considered by practitioners as it is perceived to be either prohibitively slow (when implemented sequentially), or computationally expensive (if agents are trained in parallel on independent accelerators). In this work, we compare implementations and revisit previous studies to show that the judicious use of compilation and vectorization allows population-based training to be performed on a single machine with one accelerator with minimal overhead compared to training a single agent. We also show that, when provided with a few accelerators, our protocols extend to large population sizes for applications such as hyperparameter tuning. We hope that this work and the public release of our code will encourage practitioners to use population-based learning more frequently for their research and applications.
No-Regret Learnability for Piecewise Linear Losses
Sep 17, 2016In the convex optimization approach to online regret minimization, many methods have been developed to guarantee a $O(\sqrt{T})$ bound on regret for subdifferentiable convex loss functions with bounded subgradients, by using a reduction to linear loss functions. This suggests that linear loss functions tend to be the hardest ones to learn against, regardless of the underlying decision spaces. We investigate this question in a systematic fashion looking at the interplay between the set of possible moves for both the decision maker and the adversarial environment. This allows us to highlight sharp distinctive behaviors about the learnability of piecewise linear loss functions. On the one hand, when the decision set of the decision maker is a polyhedron, we establish $\Omega(\sqrt{T})$ lower bounds on regret for a large class of piecewise linear loss functions with important applications in online linear optimization, repeated zero-sum Stackelberg games, online prediction with side information, and online two-stage optimization. On the other hand, we exhibit $o(\sqrt{T})$ learning rates, achieved by the Follow-The-Leader algorithm, in online linear optimization when the boundary of the decision maker's decision set is curved and when $0$ does not lie in the convex hull of the environment's decision set. Hence, the curvature of the decision maker's decision set is a determining factor for the optimal learning rate. These results hold in a completely adversarial setting.