 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQDax: A Library for Quality-Diversity and Population-based Algorithms with Hardware Acceleration
Aug 07, 2023QDax is an open-source library with a streamlined and modular API for Quality-Diversity (QD) optimization algorithms in Jax. The library serves as a versatile tool for optimization purposes, ranging from black-box optimization to continuous control. QDax offers implementations of popular QD, Neuroevolution, and Reinforcement Learning (RL) algorithms, supported by various examples. All the implementations can be just-in-time compiled with Jax, facilitating efficient execution across multiple accelerators, including GPUs and TPUs. These implementations effectively demonstrate the framework's flexibility and user-friendliness, easing experimentation for research purposes. Furthermore, the library is thoroughly documented and tested with 95\% coverage.
PASTA: Pretrained Action-State Transformer Agents
Jul 20, 2023



Self-supervised learning has brought about a revolutionary paradigm shift in various computing domains, including NLP, vision, and biology. Recent approaches involve pre-training transformer models on vast amounts of unlabeled data, serving as a starting point for efficiently solving downstream tasks. In the realm of reinforcement learning, researchers have recently adapted these approaches by developing models pre-trained on expert trajectories, enabling them to address a wide range of tasks, from robotics to recommendation systems. However, existing methods mostly rely on intricate pre-training objectives tailored to specific downstream applications. This paper presents a comprehensive investigation of models we refer to as Pretrained Action-State Transformer Agents (PASTA). Our study uses a unified methodology and covers an extensive set of general downstream tasks including behavioral cloning, offline RL, sensor failure robustness, and dynamics change adaptation. Our goal is to systematically compare various design choices and provide valuable insights to practitioners for building robust models. Key highlights of our study include tokenization at the action and state component level, using fundamental pre-training objectives like next token prediction, training models across diverse domains simultaneously, and using parameter efficient fine-tuning (PEFT). The developed models in our study contain fewer than 10 million parameters and the application of PEFT enables fine-tuning of fewer than 10,000 parameters during downstream adaptation, allowing a broad community to use these models and reproduce our experiments. We hope that this study will encourage further research into the use of transformers with first-principles design choices to represent RL trajectories and contribute to robust policy learning.
Jumanji: a Diverse Suite of Scalable Reinforcement Learning Environments in JAX
Jun 16, 2023Open-source reinforcement learning (RL) environments have played a crucial role in driving progress in the development of AI algorithms. In modern RL research, there is a need for simulated environments that are performant, scalable, and modular to enable their utilization in a wider range of potential real-world applications. Therefore, we present Jumanji, a suite of diverse RL environments specifically designed to be fast, flexible, and scalable. Jumanji provides a suite of environments focusing on combinatorial problems frequently encountered in industry, as well as challenging general decision-making tasks. By leveraging the efficiency of JAX and hardware accelerators like GPUs and TPUs, Jumanji enables rapid iteration of research ideas and large-scale experimentation, ultimately empowering more capable agents. Unlike existing RL environment suites, Jumanji is highly customizable, allowing users to tailor the initial state distribution and problem complexity to their needs. Furthermore, we provide actor-critic baselines for each environment, accompanied by preliminary findings on scaling and generalization scenarios. Jumanji aims to set a new standard for speed, adaptability, and scalability of RL environments.
Gradient-Informed Quality Diversity for the Illumination of Discrete Spaces
Jun 08, 2023Quality Diversity (QD) algorithms have been proposed to search for a large collection of both diverse and high-performing solutions instead of a single set of local optima. While early QD algorithms view the objective and descriptor functions as black-box functions, novel tools have been introduced to use gradient information to accelerate the search and improve overall performance of those algorithms over continuous input spaces. However a broad range of applications involve discrete spaces, such as drug discovery or image generation. Exploring those spaces is challenging as they are combinatorially large and gradients cannot be used in the same manner as in continuous spaces. We introduce map-elites with a Gradient-Informed Discrete Emitter (ME-GIDE), which extends QD optimisation with differentiable functions over discrete search spaces. ME-GIDE leverages the gradient information of the objective and descriptor functions with respect to its discrete inputs to propose gradient-informed updates that guide the search towards a diverse set of high quality solutions. We evaluate our method on challenging benchmarks including protein design and discrete latent space illumination and find that our method outperforms state-of-the-art QD algorithms in all benchmarks.
Neuroevolution is a Competitive Alternative to Reinforcement Learning for Skill Discovery
Oct 06, 2022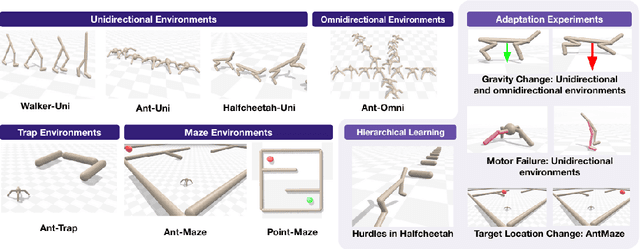
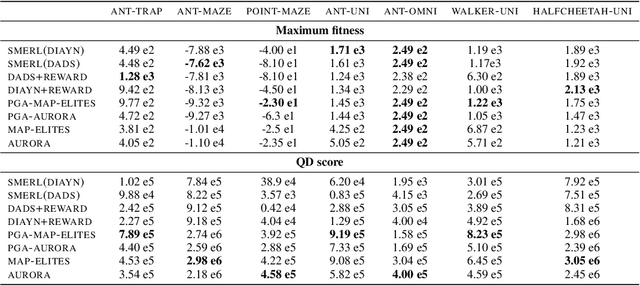
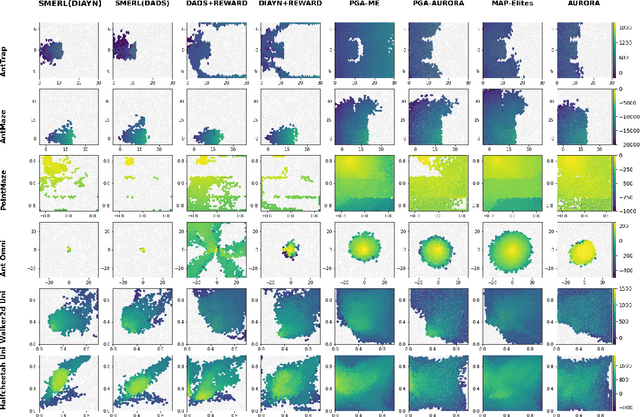
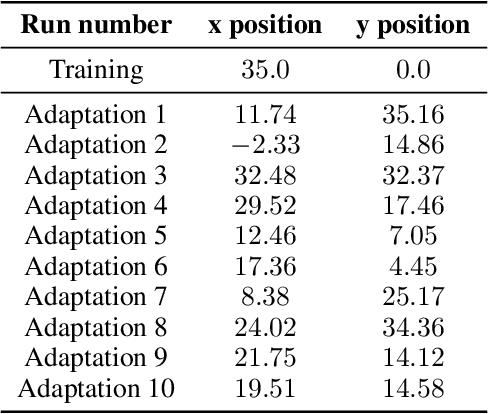
Deep Reinforcement Learning (RL) has emerged as a powerful paradigm for training neural policies to solve complex control tasks. However, these policies tend to be overfit to the exact specifications of the task and environment they were trained on, and thus do not perform well when conditions deviate slightly or when composed hierarchically to solve even more complex tasks. Recent work has shown that training a mixture of policies, as opposed to a single one, that are driven to explore different regions of the state-action space can address this shortcoming by generating a diverse set of behaviors, referred to as skills, that can be collectively used to great effect in adaptation tasks or for hierarchical planning. This is typically realized by including a diversity term - often derived from information theory - in the objective function optimized by RL. However these approaches often require careful hyperparameter tuning to be effective. In this work, we demonstrate that less widely-used neuroevolution methods, specifically Quality Diversity (QD), are a competitive alternative to information-theory-augmented RL for skill discovery. Through an extensive empirical evaluation comparing eight state-of-the-art methods on the basis of (i) metrics directly evaluating the skills' diversity, (ii) the skills' performance on adaptation tasks, and (iii) the skills' performance when used as primitives for hierarchical planning; QD methods are found to provide equal, and sometimes improved, performance whilst being less sensitive to hyperparameters and more scalable. As no single method is found to provide near-optimal performance across all environments, there is a rich scope for further research which we support by proposing future directions and providing optimized open-source implementations.