 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShiQ: Bringing back Bellman to LLMs
May 16, 2025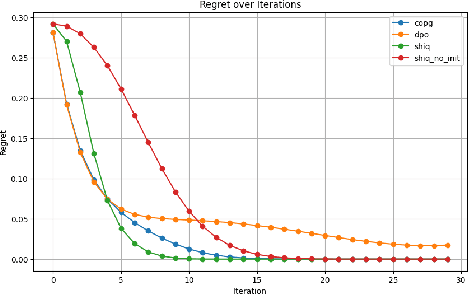
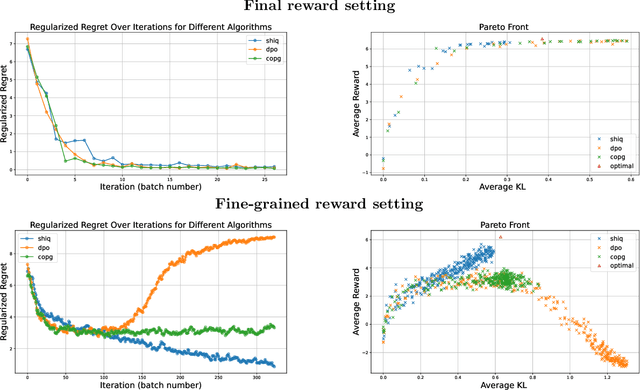

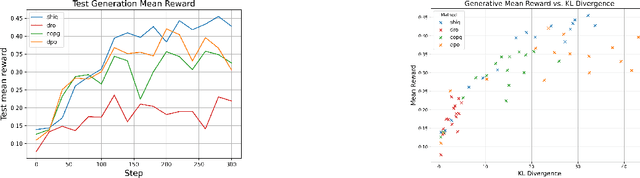
The fine-tuning of pre-trained large language models (LLMs) using reinforcement learning (RL) is generally formulated as direct policy optimization. This approach was naturally favored as it efficiently improves a pretrained LLM, seen as an initial policy. Another RL paradigm, Q-learning methods, has received far less attention in the LLM community while demonstrating major success in various non-LLM RL tasks. In particular, Q-learning effectiveness comes from its sample efficiency and ability to learn offline, which is particularly valuable given the high computational cost of sampling with LLMs. However, naively applying a Q-learning-style update to the model's logits is ineffective due to the specificity of LLMs. Our core contribution is to derive theoretically grounded loss functions from Bellman equations to adapt Q-learning methods to LLMs. To do so, we carefully adapt insights from the RL literature to account for LLM-specific characteristics, ensuring that the logits become reliable Q-value estimates. We then use this loss to build a practical algorithm, ShiQ for Shifted-Q, that supports off-policy, token-wise learning while remaining simple to implement. Finally, we evaluate ShiQ on both synthetic data and real-world benchmarks, e.g., UltraFeedback and BFCL-V3, demonstrating its effectiveness in both single-turn and multi-turn LLM settings
Command A: An Enterprise-Ready Large Language Model
Apr 01, 2025



In this report we describe the development of Command A, a powerful large language model purpose-built to excel at real-world enterprise use cases. Command A is an agent-optimised and multilingual-capable model, with support for 23 languages of global business, and a novel hybrid architecture balancing efficiency with top of the range performance. It offers best-in-class Retrieval Augmented Generation (RAG) capabilities with grounding and tool use to automate sophisticated business processes. These abilities are achieved through a decentralised training approach, including self-refinement algorithms and model merging techniques. We also include results for Command R7B which shares capability and architectural similarities to Command A. Weights for both models have been released for research purposes. This technical report details our original training pipeline and presents an extensive evaluation of our models across a suite of enterprise-relevant tasks and public benchmarks, demonstrating excellent performance and efficiency.
Aya Expanse: Combining Research Breakthroughs for a New Multilingual Frontier
Dec 05, 2024



We introduce the Aya Expanse model family, a new generation of 8B and 32B parameter multilingual language models, aiming to address the critical challenge of developing highly performant multilingual models that match or surpass the capabilities of monolingual models. By leveraging several years of research at Cohere For AI and Cohere, including advancements in data arbitrage, multilingual preference training, and model merging, Aya Expanse sets a new state-of-the-art in multilingual performance. Our evaluations on the Arena-Hard-Auto dataset, translated into 23 languages, demonstrate that Aya Expanse 8B and 32B outperform leading open-weight models in their respective parameter classes, including Gemma 2, Qwen 2.5, and Llama 3.1, achieving up to a 76.6% win-rate. Notably, Aya Expanse 32B outperforms Llama 3.1 70B, a model with twice as many parameters, achieving a 54.0% win-rate. In this short technical report, we present extended evaluation results for the Aya Expanse model family and release their open-weights, together with a new multilingual evaluation dataset m-ArenaHard.
Contrastive Policy Gradient: Aligning LLMs on sequence-level scores in a supervised-friendly fashion
Jun 27, 2024Reinforcement Learning (RL) has been used to finetune Large Language Models (LLMs) using a reward model trained from preference data, to better align with human judgment. The recently introduced direct alignment methods, which are often simpler, more stable, and computationally lighter, can more directly achieve this. However, these approaches cannot optimize arbitrary rewards, and the preference-based ones are not the only rewards of interest for LLMs (eg., unit tests for code generation or textual entailment for summarization, among others). RL-finetuning is usually done with a variation of policy gradient, which calls for on-policy or near-on-policy samples, requiring costly generations. We introduce Contrastive Policy Gradient, or CoPG, a simple and mathematically principled new RL algorithm that can estimate the optimal policy even from off-policy data. It can be seen as an off-policy policy gradient approach that does not rely on important sampling techniques and highlights the importance of using (the right) state baseline. We show this approach to generalize the direct alignment method IPO (identity preference optimization) and classic policy gradient. We experiment with the proposed CoPG on a toy bandit problem to illustrate its properties, as well as for finetuning LLMs on a summarization task, using a learned reward function considered as ground truth for the purpose of the experiments.
Averaging log-likelihoods in direct alignment
Jun 27, 2024



To better align Large Language Models (LLMs) with human judgment, Reinforcement Learning from Human Feedback (RLHF) learns a reward model and then optimizes it using regularized RL. Recently, direct alignment methods were introduced to learn such a fine-tuned model directly from a preference dataset without computing a proxy reward function. These methods are built upon contrastive losses involving the log-likelihood of (dis)preferred completions according to the trained model. However, completions have various lengths, and the log-likelihood is not length-invariant. On the other side, the cross-entropy loss used in supervised training is length-invariant, as batches are typically averaged token-wise. To reconcile these approaches, we introduce a principled approach for making direct alignment length-invariant. Formally, we introduce a new averaging operator, to be composed with the optimality operator giving the best policy for the underlying RL problem. It translates into averaging the log-likelihood within the loss. We empirically study the effect of such averaging, observing a trade-off between the length of generations and their scores.
OPERA: Automatic Offline Policy Evaluation with Re-weighted Aggregates of Multiple Estimators
May 27, 2024



Offline policy evaluation (OPE) allows us to evaluate and estimate a new sequential decision-making policy's performance by leveraging historical interaction data collected from other policies. Evaluating a new policy online without a confident estimate of its performance can lead to costly, unsafe, or hazardous outcomes, especially in education and healthcare. Several OPE estimators have been proposed in the last decade, many of which have hyperparameters and require training. Unfortunately, choosing the best OPE algorithm for each task and domain is still unclear. In this paper, we propose a new algorithm that adaptively blends a set of OPE estimators given a dataset without relying on an explicit selection using a statistical procedure. We prove that our estimator is consistent and satisfies several desirable properties for policy evaluation. Additionally, we demonstrate that when compared to alternative approaches, our estimator can be used to select higher-performing policies in healthcare and robotics. Our work contributes to improving ease of use for a general-purpose, estimator-agnostic, off-policy evaluation framework for offline RL.
PASTA: Pretrained Action-State Transformer Agents
Jul 20, 2023



Self-supervised learning has brought about a revolutionary paradigm shift in various computing domains, including NLP, vision, and biology. Recent approaches involve pre-training transformer models on vast amounts of unlabeled data, serving as a starting point for efficiently solving downstream tasks. In the realm of reinforcement learning, researchers have recently adapted these approaches by developing models pre-trained on expert trajectories, enabling them to address a wide range of tasks, from robotics to recommendation systems. However, existing methods mostly rely on intricate pre-training objectives tailored to specific downstream applications. This paper presents a comprehensive investigation of models we refer to as Pretrained Action-State Transformer Agents (PASTA). Our study uses a unified methodology and covers an extensive set of general downstream tasks including behavioral cloning, offline RL, sensor failure robustness, and dynamics change adaptation. Our goal is to systematically compare various design choices and provide valuable insights to practitioners for building robust models. Key highlights of our study include tokenization at the action and state component level, using fundamental pre-training objectives like next token prediction, training models across diverse domains simultaneously, and using parameter efficient fine-tuning (PEFT). The developed models in our study contain fewer than 10 million parameters and the application of PEFT enables fine-tuning of fewer than 10,000 parameters during downstream adaptation, allowing a broad community to use these models and reproduce our experiments. We hope that this study will encourage further research into the use of transformers with first-principles design choices to represent RL trajectories and contribute to robust policy learning.
Waypoint Transformer: Reinforcement Learning via Supervised Learning with Intermediate Targets
Jun 24, 2023



Despite the recent advancements in offline reinforcement learning via supervised learning (RvS) and the success of the decision transformer (DT) architecture in various domains, DTs have fallen short in several challenging benchmarks. The root cause of this underperformance lies in their inability to seamlessly connect segments of suboptimal trajectories. To overcome this limitation, we present a novel approach to enhance RvS methods by integrating intermediate targets. We introduce the Waypoint Transformer (WT), using an architecture that builds upon the DT framework and conditioned on automatically-generated waypoints. The results show a significant increase in the final return compared to existing RvS methods, with performance on par or greater than existing state-of-the-art temporal difference learning-based methods. Additionally, the performance and stability improvements are largest in the most challenging environments and data configurations, including AntMaze Large Play/Diverse and Kitchen Mixed/Partial.
Model-based Offline Reinforcement Learning with Local Misspecification
Jan 26, 2023We present a model-based offline reinforcement learning policy performance lower bound that explicitly captures dynamics model misspecification and distribution mismatch and we propose an empirical algorithm for optimal offline policy selection. Theoretically, we prove a novel safe policy improvement theorem by establishing pessimism approximations to the value function. Our key insight is to jointly consider selecting over dynamics models and policies: as long as a dynamics model can accurately represent the dynamics of the state-action pairs visited by a given policy, it is possible to approximate the value of that particular policy. We analyze our lower bound in the LQR setting and also show competitive performance to previous lower bounds on policy selection across a set of D4RL tasks.
Data-Efficient Pipeline for Offline Reinforcement Learning with Limited Data
Oct 16, 2022
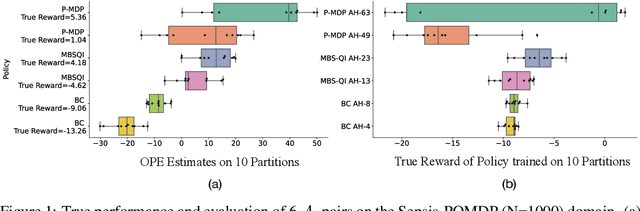

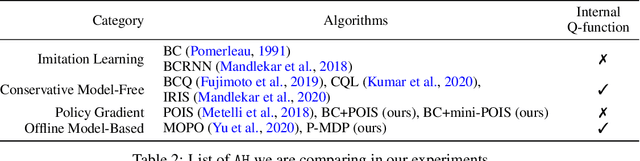
Offline reinforcement learning (RL) can be used to improve future performance by leveraging historical data. There exist many different algorithms for offline RL, and it is well recognized that these algorithms, and their hyperparameter settings, can lead to decision policies with substantially differing performance. This prompts the need for pipelines that allow practitioners to systematically perform algorithm-hyperparameter selection for their setting. Critically, in most real-world settings, this pipeline must only involve the use of historical data. Inspired by statistical model selection methods for supervised learning, we introduce a task- and method-agnostic pipeline for automatically training, comparing, selecting, and deploying the best policy when the provided dataset is limited in size. In particular, our work highlights the importance of performing multiple data splits to produce more reliable algorithm-hyperparameter selection. While this is a common approach in supervised learning, to our knowledge, this has not been discussed in detail in the offline RL setting. We show it can have substantial impacts when the dataset is small. Compared to alternate approaches, our proposed pipeline outputs higher-performing deployed policies from a broad range of offline policy learning algorithms and across various simulation domains in healthcare, education, and robotics. This work contributes toward the development of a general-purpose meta-algorithm for automatic algorithm-hyperparameter selection for offline RL.