 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFormal Theorem Proving by Rewarding LLMs to Decompose Proofs Hierarchically
Nov 04, 2024



Mathematical theorem proving is an important testbed for large language models' deep and abstract reasoning capability. This paper focuses on improving LLMs' ability to write proofs in formal languages that permit automated proof verification/evaluation. Most previous results provide human-written lemmas to the theorem prover, which is an arguably oversimplified setting that does not sufficiently test the provers' planning and decomposition capabilities. Instead, we work in a more natural setup where the lemmas that are directly relevant to the theorem are not given to the theorem prover at test time. We design an RL-based training algorithm that encourages the model to decompose a theorem into lemmas, prove the lemmas, and then prove the theorem by using the lemmas. Our reward mechanism is inspired by how mathematicians train themselves: even if a theorem is too challenging to be proved by the current model, a positive reward is still given to the model for any correct and novel lemmas that are proposed and proved in this process. During training, our model proposes and proves lemmas that are not in the training dataset. In fact, these newly-proposed correct lemmas consist of 37.7% of the training replay buffer when we train on the dataset extracted from Archive of Formal Proofs (AFP). The model trained by our RL algorithm outperforms that trained by supervised finetuning, improving the pass rate from 40.8% to 45.5% on AFP test set, and from 36.5% to 39.5% on an out-of-distribution test set.
Beyond NTK with Vanilla Gradient Descent: A Mean-Field Analysis of Neural Networks with Polynomial Width, Samples, and Time
Jun 28, 2023Despite recent theoretical progress on the non-convex optimization of two-layer neural networks, it is still an open question whether gradient descent on neural networks without unnatural modifications can achieve better sample complexity than kernel methods. This paper provides a clean mean-field analysis of projected gradient flow on polynomial-width two-layer neural networks. Different from prior works, our analysis does not require unnatural modifications of the optimization algorithm. We prove that with sample size $n = O(d^{3.1})$ where $d$ is the dimension of the inputs, the network converges in polynomially many iterations to a non-trivial error that is not achievable by kernel methods using $n \ll d^4$ samples, hence demonstrating a clear separation between unmodified gradient descent and NTK.
Toward $L_\infty$-recovery of Nonlinear Functions: A Polynomial Sample Complexity Bound for Gaussian Random Fields
Apr 29, 2023Many machine learning applications require learning a function with a small worst-case error over the entire input domain, that is, the $L_\infty$-error, whereas most existing theoretical works only guarantee recovery in average errors such as the $L_2$-error. $L_\infty$-recovery from polynomial samples is even impossible for seemingly simple function classes such as constant-norm infinite-width two-layer neural nets. This paper makes some initial steps beyond the impossibility results by leveraging the randomness in the ground-truth functions. We prove a polynomial sample complexity bound for random ground-truth functions drawn from Gaussian random fields. Our key technical novelty is to prove that the degree-$k$ spherical harmonics components of a function from Gaussian random field cannot be spiky in that their $L_\infty$/$L_2$ ratios are upperbounded by $O(d \sqrt{\ln k})$ with high probability. In contrast, the worst-case $L_\infty$/$L_2$ ratio for degree-$k$ spherical harmonics is on the order of $\Omega(\min\{d^{k/2},k^{d/2}\})$.
Model-based Offline Reinforcement Learning with Local Misspecification
Jan 26, 2023We present a model-based offline reinforcement learning policy performance lower bound that explicitly captures dynamics model misspecification and distribution mismatch and we propose an empirical algorithm for optimal offline policy selection. Theoretically, we prove a novel safe policy improvement theorem by establishing pessimism approximations to the value function. Our key insight is to jointly consider selecting over dynamics models and policies: as long as a dynamics model can accurately represent the dynamics of the state-action pairs visited by a given policy, it is possible to approximate the value of that particular policy. We analyze our lower bound in the LQR setting and also show competitive performance to previous lower bounds on policy selection across a set of D4RL tasks.
First Steps Toward Understanding the Extrapolation of Nonlinear Models to Unseen Domains
Dec 01, 2022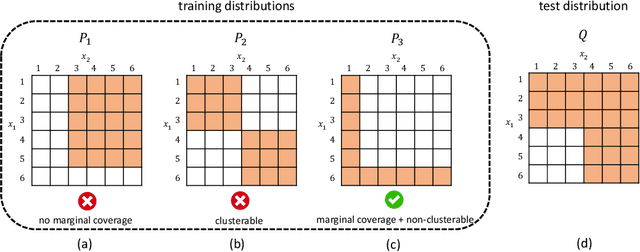
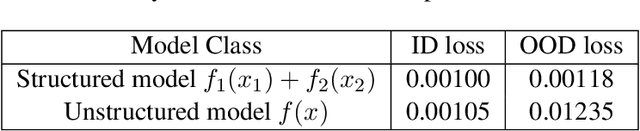


Real-world machine learning applications often involve deploying neural networks to domains that are not seen in the training time. Hence, we need to understand the extrapolation of nonlinear models -- under what conditions on the distributions and function class, models can be guaranteed to extrapolate to new test distributions. The question is very challenging because even two-layer neural networks cannot be guaranteed to extrapolate outside the support of the training distribution without further assumptions on the domain shift. This paper makes some initial steps toward analyzing the extrapolation of nonlinear models for structured domain shift. We primarily consider settings where the marginal distribution of each coordinate of the data (or subset of coordinates) does not shift significantly across the training and test distributions, but the joint distribution may have a much bigger shift. We prove that the family of nonlinear models of the form $f(x)=\sum f_i(x_i)$, where $f_i$ is an arbitrary function on the subset of features $x_i$, can extrapolate to unseen distributions, if the covariance of the features is well-conditioned. To the best of our knowledge, this is the first result that goes beyond linear models and the bounded density ratio assumption, even though the assumptions on the distribution shift and function class are stylized.
Asymptotic Instance-Optimal Algorithms for Interactive Decision Making
Jun 06, 2022Past research on interactive decision making problems (bandits, reinforcement learning, etc.) mostly focuses on the minimax regret that measures the algorithm's performance on the hardest instance. However, an ideal algorithm should adapt to the complexity of a particular problem instance and incur smaller regrets on easy instances than worst-case instances. In this paper, we design the first asymptotic instance-optimal algorithm for general interactive decision making problems with finite number of decisions under mild conditions. On \textit{every} instance $f$, our algorithm outperforms \emph{all} consistent algorithms (those achieving non-trivial regrets on all instances), and has asymptotic regret $\mathcal{C}(f) \ln n$, where $\mathcal{C}(f)$ is an exact characterization of the complexity of $f$. The key step of the algorithm involves hypothesis testing with active data collection. It computes the most economical decisions with which the algorithm collects observations to test whether an estimated instance is indeed correct; thus, the complexity $\mathcal{C}(f)$ is the minimum cost to test the instance $f$ against other instances. Our results, instantiated on concrete problems, recover the classical gap-dependent bounds for multi-armed bandits [Lai and Robbins, 1985] and prior works on linear bandits [Lattimore and Szepesvari, 2017], and improve upon the previous best instance-dependent upper bound [Xu et al., 2021] for reinforcement learning.
Design of Experiments for Stochastic Contextual Linear Bandits
Jul 22, 2021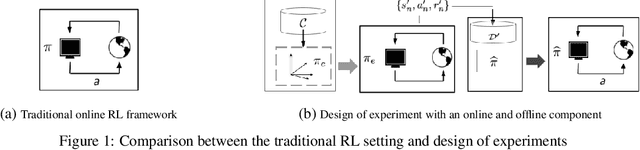
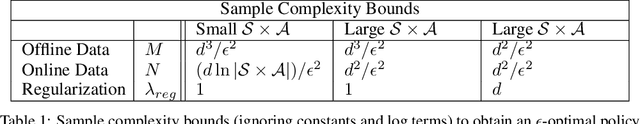
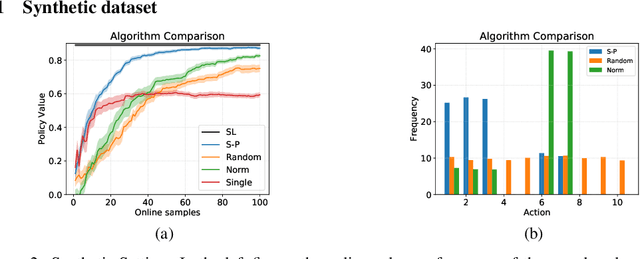
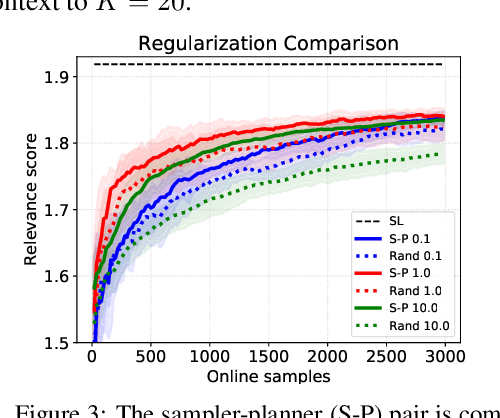
In the stochastic linear contextual bandit setting there exist several minimax procedures for exploration with policies that are reactive to the data being acquired. In practice, there can be a significant engineering overhead to deploy these algorithms, especially when the dataset is collected in a distributed fashion or when a human in the loop is needed to implement a different policy. Exploring with a single non-reactive policy is beneficial in such cases. Assuming some batch contexts are available, we design a single stochastic policy to collect a good dataset from which a near-optimal policy can be extracted. We present a theoretical analysis as well as numerical experiments on both synthetic and real-world datasets.
Provable Model-based Nonlinear Bandit and Reinforcement Learning: Shelve Optimism, Embrace Virtual Curvature
Feb 08, 2021
This paper studies model-based bandit and reinforcement learning (RL) with nonlinear function approximations. We propose to study convergence to approximate local maxima because we show that global convergence is statistically intractable even for one-layer neural net bandit with a deterministic reward. For both nonlinear bandit and RL, the paper presents a model-based algorithm, Virtual Ascent with Online Model Learner (ViOL), which provably converges to a local maximum with sample complexity that only depends on the sequential Rademacher complexity of the model class. Our results imply novel global or local regret bounds on several concrete settings such as linear bandit with finite or sparse model class, and two-layer neural net bandit. A key algorithmic insight is that optimism may lead to over-exploration even for two-layer neural net model class. On the other hand, for convergence to local maxima, it suffices to maximize the virtual return if the model can also reasonably predict the size of the gradient and Hessian of the real return.
Refined Analysis of FPL for Adversarial Markov Decision Processes
Aug 21, 2020
We consider the adversarial Markov Decision Process (MDP) problem, where the rewards for the MDP can be adversarially chosen, and the transition function can be either known or unknown. In both settings, Follow-the-PerturbedLeader (FPL) based algorithms have been proposed in previous literature. However, the established regret bounds for FPL based algorithms are worse than algorithms based on mirrordescent. We improve the analysis of FPL based algorithms in both settings, matching the current best regret bounds using faster and simpler algorithms.
Multinomial Logit Bandit with Low Switching Cost
Jul 09, 2020We study multinomial logit bandit with limited adaptivity, where the algorithms change their exploration actions as infrequently as possible when achieving almost optimal minimax regret. We propose two measures of adaptivity: the assortment switching cost and the more fine-grained item switching cost. We present an anytime algorithm (AT-DUCB) with $O(N \log T)$ assortment switches, almost matching the lower bound $\Omega(\frac{N \log T}{ \log \log T})$. In the fixed-horizon setting, our algorithm FH-DUCB incurs $O(N \log \log T)$ assortment switches, matching the asymptotic lower bound. We also present the ESUCB algorithm with item switching cost $O(N \log^2 T)$.