 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaximum Likelihood Reinforcement Learning
Feb 02, 2026Reinforcement learning is the method of choice to train models in sampling-based setups with binary outcome feedback, such as navigation, code generation, and mathematical problem solving. In such settings, models implicitly induce a likelihood over correct rollouts. However, we observe that reinforcement learning does not maximize this likelihood, and instead optimizes only a lower-order approximation. Inspired by this observation, we introduce Maximum Likelihood Reinforcement Learning (MaxRL), a sampling-based framework to approximate maximum likelihood using reinforcement learning techniques. MaxRL addresses the challenges of non-differentiable sampling by defining a compute-indexed family of sample-based objectives that interpolate between standard reinforcement learning and exact maximum likelihood as additional sampling compute is allocated. The resulting objectives admit a simple, unbiased policy-gradient estimator and converge to maximum likelihood optimization in the infinite-compute limit. Empirically, we show that MaxRL Pareto-dominates existing methods in all models and tasks we tested, achieving up to 20x test-time scaling efficiency gains compared to its GRPO-trained counterpart. We also observe MaxRL to scale better with additional data and compute. Our results suggest MaxRL is a promising framework for scaling RL training in correctness based settings.
Expanding the Capabilities of Reinforcement Learning via Text Feedback
Feb 02, 2026The success of RL for LLM post-training stems from an unreasonably uninformative source: a single bit of information per rollout as binary reward or preference label. At the other extreme, distillation offers dense supervision but requires demonstrations, which are costly and difficult to scale. We study text feedback as an intermediate signal: richer than scalar rewards, yet cheaper than complete demonstrations. Textual feedback is a natural mode of human interaction and is already abundant in many real-world settings, where users, annotators, and automated judges routinely critique LLM outputs. Towards leveraging text feedback at scale, we formalize a multi-turn RL setup, RL from Text Feedback (RLTF), where text feedback is available during training but not at inference. Therefore, models must learn to internalize the feedback in order to improve their test-time single-turn performance. To do this, we propose two methods: Self Distillation (RLTF-SD), which trains the single-turn policy to match its own feedback-conditioned second-turn generations; and Feedback Modeling (RLTF-FM), which predicts the feedback as an auxiliary objective. We provide theoretical analysis on both methods, and empirically evaluate on reasoning puzzles, competition math, and creative writing tasks. Our results show that both methods consistently outperform strong baselines across benchmarks, highlighting the potential of RL with an additional source of rich supervision at scale.
Shrinking the Variance: Shrinkage Baselines for Reinforcement Learning with Verifiable Rewards
Nov 05, 2025Reinforcement Learning with Verifiable Rewards (RLVR) has emerged as a powerful paradigm for post-training large reasoning models (LRMs) using policy-gradient methods such as GRPO. To stabilize training, these methods typically center trajectory rewards by subtracting the empirical mean for each prompt. Statistically, this centering acts as a control variate (or baseline), reducing the variance of the policy-gradient estimator. Typically, the mean reward is estimated using per-prompt empirical averages for each prompt in a batch. Drawing inspiration from Stein's paradox, we propose using shrinkage estimators that combine per-prompt and across-prompt means to improve the overall per-prompt mean estimation accuracy -- particularly in the low-generation regime typical of RLVR. Theoretically, we construct a shrinkage-based baseline that provably yields lower-variance policy-gradient estimators across algorithms. Our proposed baseline serves as a drop-in replacement for existing per-prompt mean baselines, requiring no additional hyper-parameters or computation. Empirically, shrinkage baselines consistently outperform standard empirical-mean baselines, leading to lower-variance gradient updates and improved training stability.
SPEED-RL: Faster Training of Reasoning Models via Online Curriculum Learning
Jun 10, 2025



Training large language models with reinforcement learning (RL) against verifiable rewards significantly enhances their reasoning abilities, yet remains computationally expensive due to inefficient uniform prompt sampling. We introduce Selective Prompting with Efficient Estimation of Difficulty (SPEED), an adaptive online RL curriculum that selectively chooses training examples of intermediate difficulty to maximize learning efficiency. Theoretically, we establish that intermediate-difficulty prompts improve the gradient estimator's signal-to-noise ratio, accelerating convergence. Empirically, our efficient implementation leads to 2x to 6x faster training without degrading accuracy, requires no manual tuning, and integrates seamlessly into standard RL algorithms.
Can Large Reasoning Models Self-Train?
May 27, 2025



Scaling the performance of large language models (LLMs) increasingly depends on methods that reduce reliance on human supervision. Reinforcement learning from automated verification offers an alternative, but it incurs scalability limitations due to dependency upon human-designed verifiers. Self-training, where the model's own judgment provides the supervisory signal, presents a compelling direction. We propose an online self-training reinforcement learning algorithm that leverages the model's self-consistency to infer correctness signals and train without any ground-truth supervision. We apply the algorithm to challenging mathematical reasoning tasks and show that it quickly reaches performance levels rivaling reinforcement-learning methods trained explicitly on gold-standard answers. Additionally, we analyze inherent limitations of the algorithm, highlighting how the self-generated proxy reward initially correlated with correctness can incentivize reward hacking, where confidently incorrect outputs are favored. Our results illustrate how self-supervised improvement can achieve significant performance gains without external labels, while also revealing its fundamental challenges.
Training Language Models to Reason Efficiently
Feb 06, 2025Scaling model size and training data has led to great advances in the performance of Large Language Models (LLMs). However, the diminishing returns of this approach necessitate alternative methods to improve model capabilities, particularly in tasks requiring advanced reasoning. Large reasoning models, which leverage long chain-of-thoughts, bring unprecedented breakthroughs in problem-solving capabilities but at a substantial deployment cost associated to longer generations. Reducing inference costs is crucial for the economic feasibility, user experience, and environmental sustainability of these models. In this work, we propose to train large reasoning models to reason efficiently. More precisely, we use reinforcement learning (RL) to train reasoning models to dynamically allocate inference-time compute based on task complexity. Our method incentivizes models to minimize unnecessary computational overhead while maintaining accuracy, thereby achieving substantial efficiency gains. It enables the derivation of a family of reasoning models with varying efficiency levels, controlled via a single hyperparameter. Experiments on two open-weight large reasoning models demonstrate significant reductions in inference cost while preserving most of the accuracy.
Fast Best-of-N Decoding via Speculative Rejection
Oct 26, 2024



The safe and effective deployment of Large Language Models (LLMs) involves a critical step called alignment, which ensures that the model's responses are in accordance with human preferences. Prevalent alignment techniques, such as DPO, PPO and their variants, align LLMs by changing the pre-trained model weights during a phase called post-training. While predominant, these post-training methods add substantial complexity before LLMs can be deployed. Inference-time alignment methods avoid the complex post-training step and instead bias the generation towards responses that are aligned with human preferences. The best-known inference-time alignment method, called Best-of-N, is as effective as the state-of-the-art post-training procedures. Unfortunately, Best-of-N requires vastly more resources at inference time than standard decoding strategies, which makes it computationally not viable. In this work, we introduce Speculative Rejection, a computationally-viable inference-time alignment algorithm. It generates high-scoring responses according to a given reward model, like Best-of-N does, while being between 16 to 32 times more computationally efficient.
ArCHer: Training Language Model Agents via Hierarchical Multi-Turn RL
Feb 29, 2024

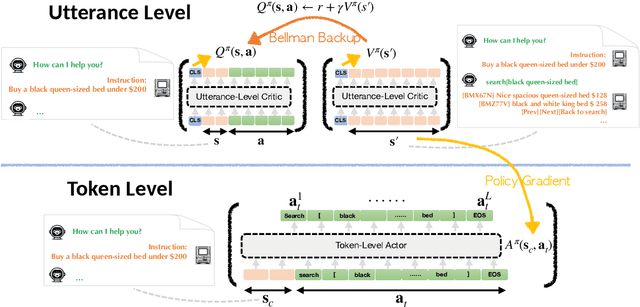
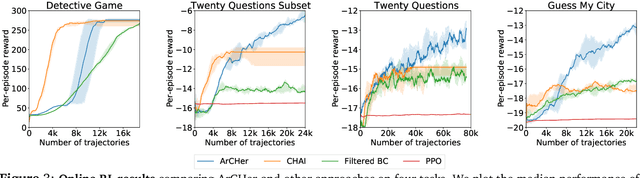
A broad use case of large language models (LLMs) is in goal-directed decision-making tasks (or "agent" tasks), where an LLM needs to not just generate completions for a given prompt, but rather make intelligent decisions over a multi-turn interaction to accomplish a task (e.g., when interacting with the web, using tools, or providing customer support). Reinforcement learning (RL) provides a general paradigm to address such agent tasks, but current RL methods for LLMs largely focus on optimizing single-turn rewards. By construction, most single-turn RL methods cannot endow LLMs with the ability to intelligently seek information over multiple turns, perform credit assignment, or reason about their past actions -- all of which are critical in agent tasks. This raises the question: how can we design effective and efficient multi-turn RL algorithms for LLMs? In this paper, we develop a framework for building multi-turn RL algorithms for fine-tuning LLMs, that preserves the flexibility of existing single-turn RL methods for LLMs (e.g., proximal policy optimization), while accommodating multiple turns, long horizons, and delayed rewards effectively. To do this, our framework adopts a hierarchical RL approach and runs two RL algorithms in parallel: a high-level off-policy value-based RL algorithm to aggregate reward over utterances, and a low-level RL algorithm that utilizes this high-level value function to train a token policy within each utterance or turn. Our hierarchical framework, Actor-Critic Framework with a Hierarchical Structure (ArCHer), can also give rise to other RL methods. Empirically, we find that ArCHer significantly improves efficiency and performance on agent tasks, attaining a sample efficiency of about 100x over existing methods, while also improving with larger model capacity (upto the 7 billion scale that we tested on).
Is Offline Decision Making Possible with Only Few Samples? Reliable Decisions in Data-Starved Bandits via Trust Region Enhancement
Feb 24, 2024



What can an agent learn in a stochastic Multi-Armed Bandit (MAB) problem from a dataset that contains just a single sample for each arm? Surprisingly, in this work, we demonstrate that even in such a data-starved setting it may still be possible to find a policy competitive with the optimal one. This paves the way to reliable decision-making in settings where critical decisions must be made by relying only on a handful of samples. Our analysis reveals that \emph{stochastic policies can be substantially better} than deterministic ones for offline decision-making. Focusing on offline multi-armed bandits, we design an algorithm called Trust Region of Uncertainty for Stochastic policy enhancemenT (TRUST) which is quite different from the predominant value-based lower confidence bound approach. Its design is enabled by localization laws, critical radii, and relative pessimism. We prove that its sample complexity is comparable to that of LCB on minimax problems while being substantially lower on problems with very few samples. Finally, we consider an application to offline reinforcement learning in the special case where the logging policies are known.
Policy Finetuning in Reinforcement Learning via Design of Experiments using Offline Data
Jul 10, 2023In some applications of reinforcement learning, a dataset of pre-collected experience is already available but it is also possible to acquire some additional online data to help improve the quality of the policy. However, it may be preferable to gather additional data with a single, non-reactive exploration policy and avoid the engineering costs associated with switching policies. In this paper we propose an algorithm with provable guarantees that can leverage an offline dataset to design a single non-reactive policy for exploration. We theoretically analyze the algorithm and measure the quality of the final policy as a function of the local coverage of the original dataset and the amount of additional data collected.