 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArCHer: Training Language Model Agents via Hierarchical Multi-Turn RL
Paper and Code


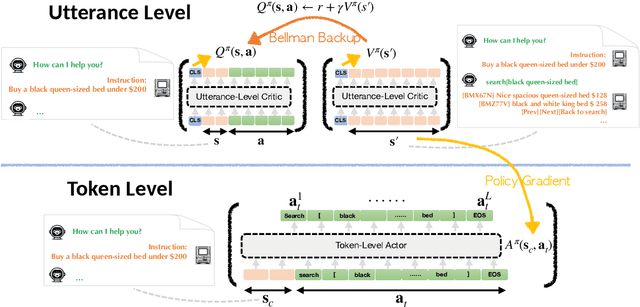
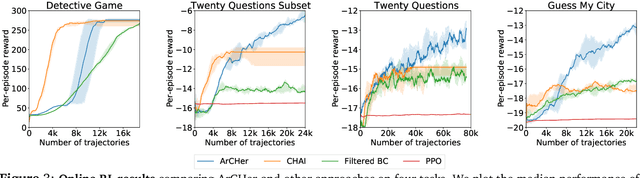
A broad use case of large language models (LLMs) is in goal-directed decision-making tasks (or "agent" tasks), where an LLM needs to not just generate completions for a given prompt, but rather make intelligent decisions over a multi-turn interaction to accomplish a task (e.g., when interacting with the web, using tools, or providing customer support). Reinforcement learning (RL) provides a general paradigm to address such agent tasks, but current RL methods for LLMs largely focus on optimizing single-turn rewards. By construction, most single-turn RL methods cannot endow LLMs with the ability to intelligently seek information over multiple turns, perform credit assignment, or reason about their past actions -- all of which are critical in agent tasks. This raises the question: how can we design effective and efficient multi-turn RL algorithms for LLMs? In this paper, we develop a framework for building multi-turn RL algorithms for fine-tuning LLMs, that preserves the flexibility of existing single-turn RL methods for LLMs (e.g., proximal policy optimization), while accommodating multiple turns, long horizons, and delayed rewards effectively. To do this, our framework adopts a hierarchical RL approach and runs two RL algorithms in parallel: a high-level off-policy value-based RL algorithm to aggregate reward over utterances, and a low-level RL algorithm that utilizes this high-level value function to train a token policy within each utterance or turn. Our hierarchical framework, Actor-Critic Framework with a Hierarchical Structure (ArCHer), can also give rise to other RL methods. Empirically, we find that ArCHer significantly improves efficiency and performance on agent tasks, attaining a sample efficiency of about 100x over existing methods, while also improving with larger model capacity (upto the 7 billion scale that we tested on).