 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing from Another Perspective: Evaluating Multi-View Understanding in MLLMs
Apr 21, 2025



Multi-view understanding, the ability to reconcile visual information across diverse viewpoints for effective navigation, manipulation, and 3D scene comprehension, is a fundamental challenge in Multi-Modal Large Language Models (MLLMs) to be used as embodied agents. While recent MLLMs have shown impressive advances in high-level reasoning and planning, they frequently fall short when confronted with multi-view geometric consistency and cross-view correspondence. To comprehensively evaluate the challenges of MLLMs in multi-view scene reasoning, we propose All-Angles Bench, a benchmark of over 2,100 human carefully annotated multi-view question-answer pairs across 90 diverse real-world scenes. Our six tasks (counting, attribute identification, relative distance, relative direction, object manipulation, and camera pose estimation) specifically test model's geometric correspondence and the capacity to align information consistently across views. Our extensive experiments, benchmark on 27 representative MLLMs including Gemini-2.0-Flash, Claude-3.7-Sonnet, and GPT-4o against human evaluators reveals a substantial performance gap, indicating that current MLLMs remain far from human-level proficiency. Through in-depth analysis, we show that MLLMs are particularly underperforming under two aspects: (1) cross-view correspondence for partially occluded views and (2) establishing the coarse camera poses. These findings highlight the necessity of domain-specific refinements or modules that embed stronger multi-view awareness. We believe that our All-Angles Bench offers valuable insights and contribute to bridging the gap between MLLMs and human-level multi-view understanding. The project and benchmark are publicly available at https://danielchyeh.github.io/All-Angles-Bench/.
SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training
Jan 28, 2025



Supervised fine-tuning (SFT) and reinforcement learning (RL) are widely used post-training techniques for foundation models. However, their roles in enhancing model generalization capabilities remain unclear. This paper studies the difference between SFT and RL on generalization and memorization, focusing on text-based rule variants and visual variants. We introduce GeneralPoints, an arithmetic reasoning card game, and adopt V-IRL, a real-world navigation environment, to assess how models trained with SFT and RL generalize to unseen variants in both textual and visual domains. We show that RL, especially when trained with an outcome-based reward, generalizes across both rule-based textual and visual variants. SFT, in contrast, tends to memorize training data and struggles to generalize out-of-distribution scenarios. Further analysis reveals that RL improves the model's underlying visual recognition capabilities, contributing to its enhanced generalization in the visual domain. Despite RL's superior generalization, we show that SFT remains essential for effective RL training; SFT stabilizes the model's output format, enabling subsequent RL to achieve its performance gains. These findings demonstrates the capability of RL for acquiring generalizable knowledge in complex, multi-modal tasks.
Fine-Tuning Large Vision-Language Models as Decision-Making Agents via Reinforcement Learning
May 17, 2024



Large vision-language models (VLMs) fine-tuned on specialized visual instruction-following data have exhibited impressive language reasoning capabilities across various scenarios. However, this fine-tuning paradigm may not be able to efficiently learn optimal decision-making agents in multi-step goal-directed tasks from interactive environments. To address this challenge, we propose an algorithmic framework that fine-tunes VLMs with reinforcement learning (RL). Specifically, our framework provides a task description and then prompts the VLM to generate chain-of-thought (CoT) reasoning, enabling the VLM to efficiently explore intermediate reasoning steps that lead to the final text-based action. Next, the open-ended text output is parsed into an executable action to interact with the environment to obtain goal-directed task rewards. Finally, our framework uses these task rewards to fine-tune the entire VLM with RL. Empirically, we demonstrate that our proposed framework enhances the decision-making capabilities of VLM agents across various tasks, enabling 7b models to outperform commercial models such as GPT4-V or Gemini. Furthermore, we find that CoT reasoning is a crucial component for performance improvement, as removing the CoT reasoning results in a significant decrease in the overall performance of our method.
Is Offline Decision Making Possible with Only Few Samples? Reliable Decisions in Data-Starved Bandits via Trust Region Enhancement
Feb 24, 2024



What can an agent learn in a stochastic Multi-Armed Bandit (MAB) problem from a dataset that contains just a single sample for each arm? Surprisingly, in this work, we demonstrate that even in such a data-starved setting it may still be possible to find a policy competitive with the optimal one. This paves the way to reliable decision-making in settings where critical decisions must be made by relying only on a handful of samples. Our analysis reveals that \emph{stochastic policies can be substantially better} than deterministic ones for offline decision-making. Focusing on offline multi-armed bandits, we design an algorithm called Trust Region of Uncertainty for Stochastic policy enhancemenT (TRUST) which is quite different from the predominant value-based lower confidence bound approach. Its design is enabled by localization laws, critical radii, and relative pessimism. We prove that its sample complexity is comparable to that of LCB on minimax problems while being substantially lower on problems with very few samples. Finally, we consider an application to offline reinforcement learning in the special case where the logging policies are known.
Eyes Wide Shut? Exploring the Visual Shortcomings of Multimodal LLMs
Jan 11, 2024



Is vision good enough for language? Recent advancements in multimodal models primarily stem from the powerful reasoning abilities of large language models (LLMs). However, the visual component typically depends only on the instance-level contrastive language-image pre-training (CLIP). Our research reveals that the visual capabilities in recent multimodal LLMs (MLLMs) still exhibit systematic shortcomings. To understand the roots of these errors, we explore the gap between the visual embedding space of CLIP and vision-only self-supervised learning. We identify ''CLIP-blind pairs'' - images that CLIP perceives as similar despite their clear visual differences. With these pairs, we construct the Multimodal Visual Patterns (MMVP) benchmark. MMVP exposes areas where state-of-the-art systems, including GPT-4V, struggle with straightforward questions across nine basic visual patterns, often providing incorrect answers and hallucinated explanations. We further evaluate various CLIP-based vision-and-language models and found a notable correlation between visual patterns that challenge CLIP models and those problematic for multimodal LLMs. As an initial effort to address these issues, we propose a Mixture of Features (MoF) approach, demonstrating that integrating vision self-supervised learning features with MLLMs can significantly enhance their visual grounding capabilities. Together, our research suggests visual representation learning remains an open challenge, and accurate visual grounding is crucial for future successful multimodal systems.
LMRL Gym: Benchmarks for Multi-Turn Reinforcement Learning with Language Models
Nov 30, 2023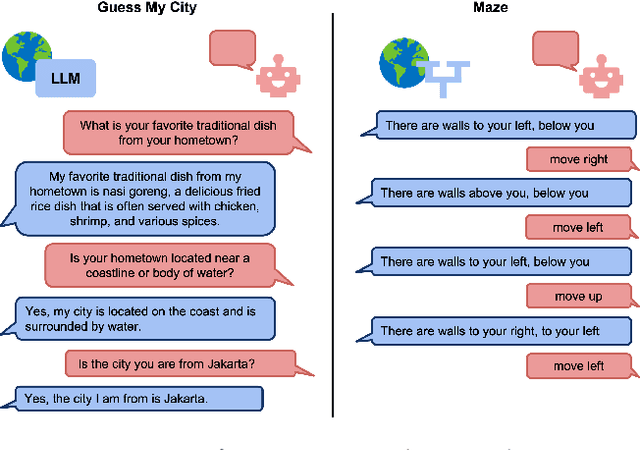
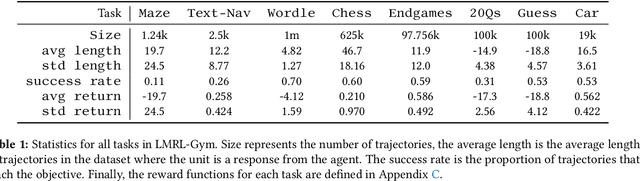
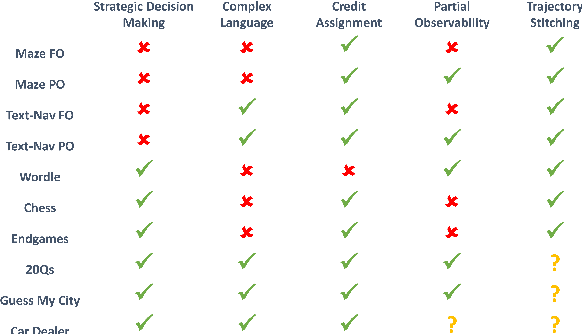
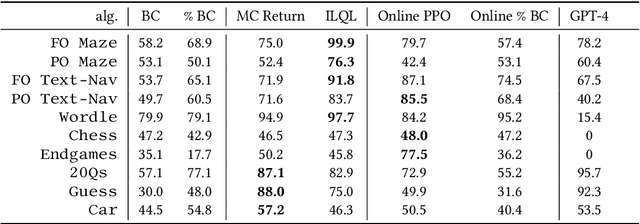
Large language models (LLMs) provide excellent text-generation capabilities, but standard prompting and generation methods generally do not lead to intentional or goal-directed agents and might necessitate considerable prompt tuning. This becomes particularly apparent in multi-turn conversations: even the best current LLMs rarely ask clarifying questions, engage in explicit information gathering, or take actions now that lead to better decisions after multiple turns. Reinforcement learning has the potential to leverage the powerful modeling capabilities of LLMs, as well as their internal representation of textual interactions, to create capable goal-directed language agents. This can enable intentional and temporally extended interactions, such as with humans, through coordinated persuasion and carefully crafted questions, or in goal-directed play through text games to bring about desired final outcomes. However, enabling this requires the community to develop stable and reliable reinforcement learning algorithms that can effectively train LLMs. Developing such algorithms requires tasks that can gauge progress on algorithm design, provide accessible and reproducible evaluations for multi-turn interactions, and cover a range of task properties and challenges in improving reinforcement learning algorithms. Our paper introduces the LMRL-Gym benchmark for evaluating multi-turn RL for LLMs, together with an open-source research framework containing a basic toolkit for getting started on multi-turn RL with offline value-based and policy-based RL methods. Our benchmark consists of 8 different language tasks, which require multiple rounds of language interaction and cover a range of tasks in open-ended dialogue and text games.
White-Box Transformers via Sparse Rate Reduction: Compression Is All There Is?
Nov 24, 2023



In this paper, we contend that a natural objective of representation learning is to compress and transform the distribution of the data, say sets of tokens, towards a low-dimensional Gaussian mixture supported on incoherent subspaces. The goodness of such a representation can be evaluated by a principled measure, called sparse rate reduction, that simultaneously maximizes the intrinsic information gain and extrinsic sparsity of the learned representation. From this perspective, popular deep network architectures, including transformers, can be viewed as realizing iterative schemes to optimize this measure. Particularly, we derive a transformer block from alternating optimization on parts of this objective: the multi-head self-attention operator compresses the representation by implementing an approximate gradient descent step on the coding rate of the features, and the subsequent multi-layer perceptron sparsifies the features. This leads to a family of white-box transformer-like deep network architectures, named CRATE, which are mathematically fully interpretable. We show, by way of a novel connection between denoising and compression, that the inverse to the aforementioned compressive encoding can be realized by the same class of CRATE architectures. Thus, the so-derived white-box architectures are universal to both encoders and decoders. Experiments show that these networks, despite their simplicity, indeed learn to compress and sparsify representations of large-scale real-world image and text datasets, and achieve performance very close to highly engineered transformer-based models: ViT, MAE, DINO, BERT, and GPT2. We believe the proposed computational framework demonstrates great potential in bridging the gap between theory and practice of deep learning, from a unified perspective of data compression. Code is available at: https://ma-lab-berkeley.github.io/CRATE .
RLIF: Interactive Imitation Learning as Reinforcement Learning
Nov 21, 2023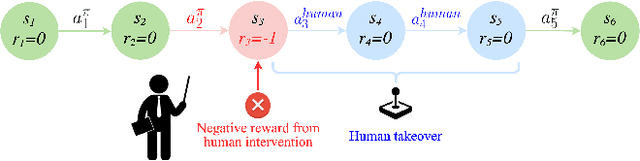
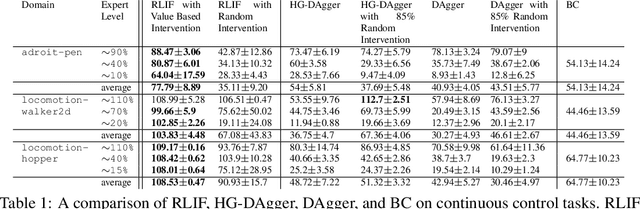
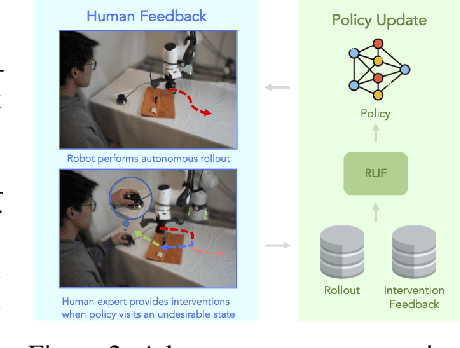

Although reinforcement learning methods offer a powerful framework for automatic skill acquisition, for practical learning-based control problems in domains such as robotics, imitation learning often provides a more convenient and accessible alternative. In particular, an interactive imitation learning method such as DAgger, which queries a near-optimal expert to intervene online to collect correction data for addressing the distributional shift challenges that afflict na\"ive behavioral cloning, can enjoy good performance both in theory and practice without requiring manually specified reward functions and other components of full reinforcement learning methods. In this paper, we explore how off-policy reinforcement learning can enable improved performance under assumptions that are similar but potentially even more practical than those of interactive imitation learning. Our proposed method uses reinforcement learning with user intervention signals themselves as rewards. This relaxes the assumption that intervening experts in interactive imitation learning should be near-optimal and enables the algorithm to learn behaviors that improve over the potential suboptimal human expert. We also provide a unified framework to analyze our RL method and DAgger; for which we present the asymptotic analysis of the suboptimal gap for both methods as well as the non-asymptotic sample complexity bound of our method. We then evaluate our method on challenging high-dimensional continuous control simulation benchmarks as well as real-world robotic vision-based manipulation tasks. The results show that it strongly outperforms DAgger-like approaches across the different tasks, especially when the intervening experts are suboptimal. Code and videos can be found on the project website: rlif-page.github.io
Investigating the Catastrophic Forgetting in Multimodal Large Language Models
Sep 26, 2023
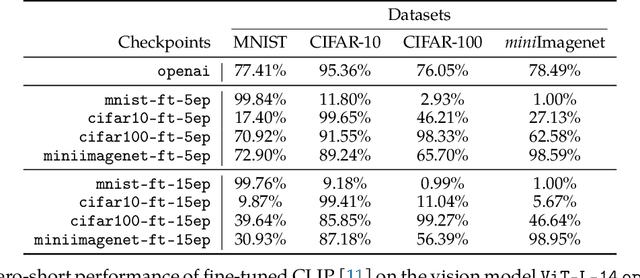
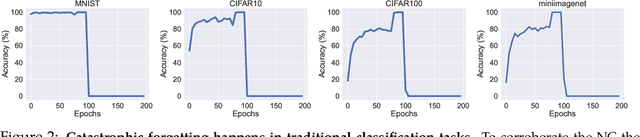
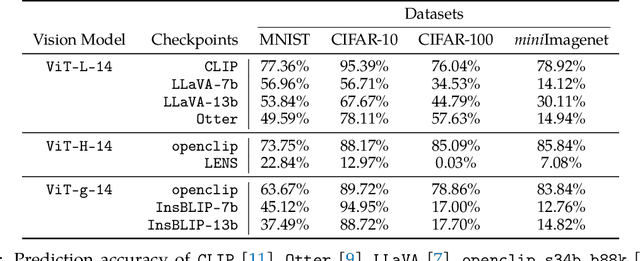
Following the success of GPT4, there has been a surge in interest in multimodal large language model (MLLM) research. This line of research focuses on developing general-purpose LLMs through fine-tuning pre-trained LLMs and vision models. However, catastrophic forgetting, a notorious phenomenon where the fine-tuned model fails to retain similar performance compared to the pre-trained model, still remains an inherent problem in multimodal LLMs (MLLM). In this paper, we introduce EMT: Evaluating MulTimodality for evaluating the catastrophic forgetting in MLLMs, by treating each MLLM as an image classifier. We first apply EMT to evaluate several open-source fine-tuned MLLMs and we discover that almost all evaluated MLLMs fail to retain the same performance levels as their vision encoders on standard image classification tasks. Moreover, we continue fine-tuning LLaVA, an MLLM and utilize EMT to assess performance throughout the fine-tuning. Interestingly, our results suggest that early-stage fine-tuning on an image dataset improves performance across other image datasets, by enhancing the alignment of text and visual features. However, as fine-tuning proceeds, the MLLMs begin to hallucinate, resulting in a significant loss of generalizability, even when the image encoder remains frozen. Our results suggest that MLLMs have yet to demonstrate performance on par with their vision models on standard image classification tasks and the current MLLM fine-tuning procedure still has room for improvement.
Cal-QL: Calibrated Offline RL Pre-Training for Efficient Online Fine-Tuning
Mar 09, 2023A compelling use case of offline reinforcement learning (RL) is to obtain a policy initialization from existing datasets, which allows efficient fine-tuning with limited amounts of active online interaction. However, several existing offline RL methods tend to exhibit poor online fine-tuning performance. On the other hand, online RL methods can learn effectively through online interaction, but struggle to incorporate offline data, which can make them very slow in settings where exploration is challenging or pre-training is necessary. In this paper, we devise an approach for learning an effective initialization from offline data that also enables fast online fine-tuning capabilities. Our approach, calibrated Q-learning (Cal-QL) accomplishes this by learning a conservative value function initialization that underestimates the value of the learned policy from offline data, while also being calibrated, in the sense that the learned Q-values are at a reasonable scale. We refer to this property as calibration, and define it formally as providing a lower bound on the true value function of the learned policy and an upper bound on the value of some other (suboptimal) reference policy, which may simply be the behavior policy. We show that offline RL algorithms that learn such calibrated value functions lead to effective online fine-tuning, enabling us to take the benefits of offline initializations in online fine-tuning. In practice, Cal-QL can be implemented on top of existing conservative methods for offline RL within a one-line code change. Empirically, Cal-QL outperforms state-of-the-art methods on 10/11 fine-tuning benchmark tasks that we study in this paper.