 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFASTER: Value-Guided Sampling for Fast RL
Apr 21, 2026Some of the most performant reinforcement learning algorithms today can be prohibitively expensive as they use test-time scaling methods such as sampling multiple action candidates and selecting the best one. In this work, we propose FASTER, a method for getting the benefits of sampling-based test-time scaling of diffusion-based policies without the computational cost by tracing the performance gain of action samples back to earlier in the denoising process. Our key insight is that we can model the denoising of multiple action candidates and selecting the best one as a Markov Decision Process (MDP) where the goal is to progressively filter action candidates before denoising is complete. With this MDP, we can learn a policy and value function in the denoising space that predicts the downstream value of action candidates in the denoising process and filters them while maximizing returns. The result is a method that is lightweight and can be plugged into existing generative RL algorithms. Across challenging long-horizon manipulation tasks in online and batch-online RL, FASTER consistently improves the underlying policies and achieves the best overall performance among the compared methods. Applied to a pretrained VLA, FASTER achieves the same performance while substantially reducing training and inference compute requirements. Code is available at https://github.com/alexanderswerdlow/faster .
TQL: Scaling Q-Functions with Transformers by Preventing Attention Collapse
Feb 01, 2026Despite scale driving substantial recent advancements in machine learning, reinforcement learning (RL) methods still primarily use small value functions. Naively scaling value functions -- including with a transformer architecture, which is known to be highly scalable -- often results in learning instability and worse performance. In this work, we ask what prevents transformers from scaling effectively for value functions? Through empirical analysis, we identify the critical failure mode in this scaling: attention scores collapse as capacity increases. Our key insight is that we can effectively prevent this collapse and stabilize training by controlling the entropy of the attention scores, thereby enabling the use of larger models. To this end, we propose Transformer Q-Learning (TQL), a method that unlocks the scaling potential of transformers in learning value functions in RL. Our approach yields up to a 43% improvement in performance when scaling from the smallest to the largest network sizes, while prior methods suffer from performance degradation.
Posterior Behavioral Cloning: Pretraining BC Policies for Efficient RL Finetuning
Dec 18, 2025Standard practice across domains from robotics to language is to first pretrain a policy on a large-scale demonstration dataset, and then finetune this policy, typically with reinforcement learning (RL), in order to improve performance on deployment domains. This finetuning step has proved critical in achieving human or super-human performance, yet while much attention has been given to developing more effective finetuning algorithms, little attention has been given to ensuring the pretrained policy is an effective initialization for RL finetuning. In this work we seek to understand how the pretrained policy affects finetuning performance, and how to pretrain policies in order to ensure they are effective initializations for finetuning. We first show theoretically that standard behavioral cloning (BC) -- which trains a policy to directly match the actions played by the demonstrator -- can fail to ensure coverage over the demonstrator's actions, a minimal condition necessary for effective RL finetuning. We then show that if, instead of exactly fitting the observed demonstrations, we train a policy to model the posterior distribution of the demonstrator's behavior given the demonstration dataset, we do obtain a policy that ensures coverage over the demonstrator's actions, enabling more effective finetuning. Furthermore, this policy -- which we refer to as the posterior behavioral cloning (PostBC) policy -- achieves this while ensuring pretrained performance is no worse than that of the BC policy. We then show that PostBC is practically implementable with modern generative models in robotic control domains -- relying only on standard supervised learning -- and leads to significantly improved RL finetuning performance on both realistic robotic control benchmarks and real-world robotic manipulation tasks, as compared to standard behavioral cloning.
EXPO: Stable Reinforcement Learning with Expressive Policies
Jul 10, 2025We study the problem of training and fine-tuning expressive policies with online reinforcement learning (RL) given an offline dataset. Training expressive policy classes with online RL present a unique challenge of stable value maximization. Unlike simpler Gaussian policies commonly used in online RL, expressive policies like diffusion and flow-matching policies are parameterized by a long denoising chain, which hinders stable gradient propagation from actions to policy parameters when optimizing against some value function. Our key insight is that we can address stable value maximization by avoiding direct optimization over value with the expressive policy and instead construct an on-the-fly RL policy to maximize Q-value. We propose Expressive Policy Optimization (EXPO), a sample-efficient online RL algorithm that utilizes an on-the-fly policy to maximize value with two parameterized policies -- a larger expressive base policy trained with a stable imitation learning objective and a light-weight Gaussian edit policy that edits the actions sampled from the base policy toward a higher value distribution. The on-the-fly policy optimizes the actions from the base policy with the learned edit policy and chooses the value maximizing action from the base and edited actions for both sampling and temporal-difference (TD) backup. Our approach yields up to 2-3x improvement in sample efficiency on average over prior methods both in the setting of fine-tuning a pretrained policy given offline data and in leveraging offline data to train online.
Reinforcement Learning via Implicit Imitation Guidance
Jun 09, 2025We study the problem of sample efficient reinforcement learning, where prior data such as demonstrations are provided for initialization in lieu of a dense reward signal. A natural approach is to incorporate an imitation learning objective, either as regularization during training or to acquire a reference policy. However, imitation learning objectives can ultimately degrade long-term performance, as it does not directly align with reward maximization. In this work, we propose to use prior data solely for guiding exploration via noise added to the policy, sidestepping the need for explicit behavior cloning constraints. The key insight in our framework, Data-Guided Noise (DGN), is that demonstrations are most useful for identifying which actions should be explored, rather than forcing the policy to take certain actions. Our approach achieves up to 2-3x improvement over prior reinforcement learning from offline data methods across seven simulated continuous control tasks.
What Matters for Batch Online Reinforcement Learning in Robotics?
May 12, 2025The ability to learn from large batches of autonomously collected data for policy improvement -- a paradigm we refer to as batch online reinforcement learning -- holds the promise of enabling truly scalable robot learning by significantly reducing the need for human effort of data collection while getting benefits from self-improvement. Yet, despite the promise of this paradigm, it remains challenging to achieve due to algorithms not being able to learn effectively from the autonomous data. For example, prior works have applied imitation learning and filtered imitation learning methods to the batch online RL problem, but these algorithms often fail to efficiently improve from the autonomously collected data or converge quickly to a suboptimal point. This raises the question of what matters for effective batch online RL in robotics. Motivated by this question, we perform a systematic empirical study of three axes -- (i) algorithm class, (ii) policy extraction methods, and (iii) policy expressivity -- and analyze how these axes affect performance and scaling with the amount of autonomous data. Through our analysis, we make several observations. First, we observe that the use of Q-functions to guide batch online RL significantly improves performance over imitation-based methods. Building on this, we show that an implicit method of policy extraction -- via choosing the best action in the distribution of the policy -- is necessary over traditional policy extraction methods from offline RL. Next, we show that an expressive policy class is preferred over less expressive policy classes. Based on this analysis, we propose a general recipe for effective batch online RL. We then show a simple addition to the recipe of using temporally-correlated noise to obtain more diversity results in further performance gains. Our recipe obtains significantly better performance and scaling compared to prior methods.
Adaptively Learning to Select-Rank in Online Platforms
Jun 07, 2024



Ranking algorithms are fundamental to various online platforms across e-commerce sites to content streaming services. Our research addresses the challenge of adaptively ranking items from a candidate pool for heterogeneous users, a key component in personalizing user experience. We develop a user response model that considers diverse user preferences and the varying effects of item positions, aiming to optimize overall user satisfaction with the ranked list. We frame this problem within a contextual bandits framework, with each ranked list as an action. Our approach incorporates an upper confidence bound to adjust predicted user satisfaction scores and selects the ranking action that maximizes these adjusted scores, efficiently solved via maximum weight imperfect matching. We demonstrate that our algorithm achieves a cumulative regret bound of $O(d\sqrt{NKT})$ for ranking $K$ out of $N$ items in a $d$-dimensional context space over $T$ rounds, under the assumption that user responses follow a generalized linear model. This regret alleviates dependence on the ambient action space, whose cardinality grows exponentially with $N$ and $K$ (thus rendering direct application of existing adaptive learning algorithms -- such as UCB or Thompson sampling -- infeasible). Experiments conducted on both simulated and real-world datasets demonstrate our algorithm outperforms the baseline.
RLIF: Interactive Imitation Learning as Reinforcement Learning
Nov 21, 2023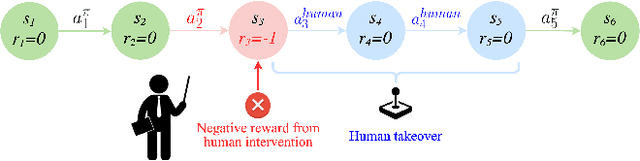
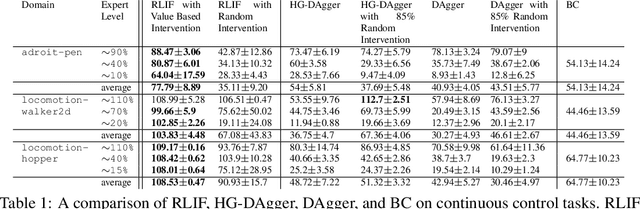
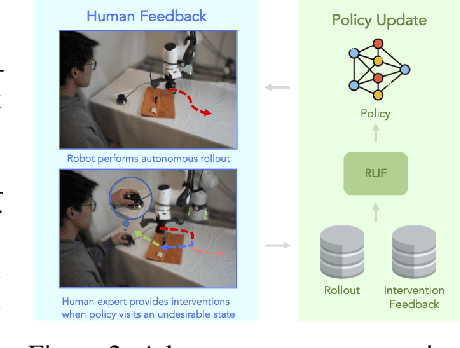

Although reinforcement learning methods offer a powerful framework for automatic skill acquisition, for practical learning-based control problems in domains such as robotics, imitation learning often provides a more convenient and accessible alternative. In particular, an interactive imitation learning method such as DAgger, which queries a near-optimal expert to intervene online to collect correction data for addressing the distributional shift challenges that afflict na\"ive behavioral cloning, can enjoy good performance both in theory and practice without requiring manually specified reward functions and other components of full reinforcement learning methods. In this paper, we explore how off-policy reinforcement learning can enable improved performance under assumptions that are similar but potentially even more practical than those of interactive imitation learning. Our proposed method uses reinforcement learning with user intervention signals themselves as rewards. This relaxes the assumption that intervening experts in interactive imitation learning should be near-optimal and enables the algorithm to learn behaviors that improve over the potential suboptimal human expert. We also provide a unified framework to analyze our RL method and DAgger; for which we present the asymptotic analysis of the suboptimal gap for both methods as well as the non-asymptotic sample complexity bound of our method. We then evaluate our method on challenging high-dimensional continuous control simulation benchmarks as well as real-world robotic vision-based manipulation tasks. The results show that it strongly outperforms DAgger-like approaches across the different tasks, especially when the intervening experts are suboptimal. Code and videos can be found on the project website: rlif-page.github.io
Action-Quantized Offline Reinforcement Learning for Robotic Skill Learning
Oct 18, 2023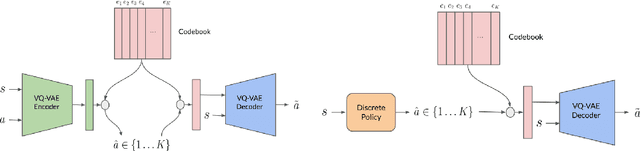

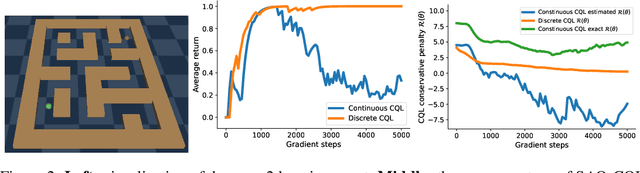
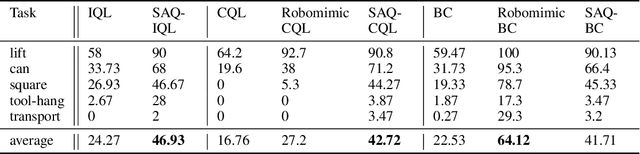
The offline reinforcement learning (RL) paradigm provides a general recipe to convert static behavior datasets into policies that can perform better than the policy that collected the data. While policy constraints, conservatism, and other methods for mitigating distributional shifts have made offline reinforcement learning more effective, the continuous action setting often necessitates various approximations for applying these techniques. Many of these challenges are greatly alleviated in discrete action settings, where offline RL constraints and regularizers can often be computed more precisely or even exactly. In this paper, we propose an adaptive scheme for action quantization. We use a VQ-VAE to learn state-conditioned action quantization, avoiding the exponential blowup that comes with na\"ive discretization of the action space. We show that several state-of-the-art offline RL methods such as IQL, CQL, and BRAC improve in performance on benchmarks when combined with our proposed discretization scheme. We further validate our approach on a set of challenging long-horizon complex robotic manipulation tasks in the Robomimic environment, where our discretized offline RL algorithms are able to improve upon their continuous counterparts by 2-3x. Our project page is at https://saqrl.github.io/
Near-Optimal High-Probability Convergence for Non-Convex Stochastic Optimization with Variance Reduction
Feb 13, 2023Traditional analyses for non-convex stochastic optimization problems characterize convergence bounds in expectation, which is inadequate as it does not supply a useful performance guarantee on a single run. Motivated by its importance, an emerging line of literature has recently studied the high-probability convergence behavior of several algorithms, including the classic stochastic gradient descent (SGD). However, no high-probability results are established for optimization algorithms with variance reduction, which is known to accelerate the convergence process and has been the de facto algorithmic technique for stochastic optimization at large. To close this important gap, we introduce a new variance-reduced algorithm for non-convex stochastic optimization, which we call Generalized SignSTORM. We show that with probability at least $1-\delta$, our algorithm converges at the rate of $O(\log(dT/\delta)/T^{1/3})$ after $T$ iterations where $d$ is the problem dimension. This convergence guarantee matches the existing lower bound up to a log factor, and to our best knowledge, is the first high-probability minimax (near-)optimal result. Finally, we demonstrate the effectiveness of our algorithm through numerical experiments.