 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning via Implicit Imitation Guidance
Jun 09, 2025We study the problem of sample efficient reinforcement learning, where prior data such as demonstrations are provided for initialization in lieu of a dense reward signal. A natural approach is to incorporate an imitation learning objective, either as regularization during training or to acquire a reference policy. However, imitation learning objectives can ultimately degrade long-term performance, as it does not directly align with reward maximization. In this work, we propose to use prior data solely for guiding exploration via noise added to the policy, sidestepping the need for explicit behavior cloning constraints. The key insight in our framework, Data-Guided Noise (DGN), is that demonstrations are most useful for identifying which actions should be explored, rather than forcing the policy to take certain actions. Our approach achieves up to 2-3x improvement over prior reinforcement learning from offline data methods across seven simulated continuous control tasks.
Curating Demonstrations using Online Experience
Mar 05, 2025


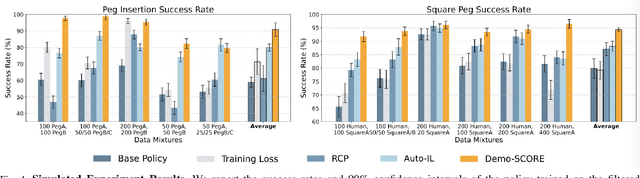
Many robot demonstration datasets contain heterogeneous demonstrations of varying quality. This heterogeneity may benefit policy pre-training, but can hinder robot performance when used with a final imitation learning objective. In particular, some strategies in the data may be less reliable than others or may be underrepresented in the data, leading to poor performance when such strategies are sampled at test time. Moreover, such unreliable or underrepresented strategies can be difficult even for people to discern, and sifting through demonstration datasets is time-consuming and costly. On the other hand, policy performance when trained on such demonstrations can reflect the reliability of different strategies. We thus propose for robots to self-curate based on online robot experience (Demo-SCORE). More specifically, we train and cross-validate a classifier to discern successful policy roll-outs from unsuccessful ones and use the classifier to filter heterogeneous demonstration datasets. Our experiments in simulation and the real world show that Demo-SCORE can effectively identify suboptimal demonstrations without manual curation. Notably, Demo-SCORE achieves over 15-35% higher absolute success rate in the resulting policy compared to the base policy trained with all original demonstrations.
Commonsense Reasoning for Legged Robot Adaptation with Vision-Language Models
Jul 02, 2024Legged robots are physically capable of navigating a diverse variety of environments and overcoming a wide range of obstructions. For example, in a search and rescue mission, a legged robot could climb over debris, crawl through gaps, and navigate out of dead ends. However, the robot's controller needs to respond intelligently to such varied obstacles, and this requires handling unexpected and unusual scenarios successfully. This presents an open challenge to current learning methods, which often struggle with generalization to the long tail of unexpected situations without heavy human supervision. To address this issue, we investigate how to leverage the broad knowledge about the structure of the world and commonsense reasoning capabilities of vision-language models (VLMs) to aid legged robots in handling difficult, ambiguous situations. We propose a system, VLM-Predictive Control (VLM-PC), combining two key components that we find to be crucial for eliciting on-the-fly, adaptive behavior selection with VLMs: (1) in-context adaptation over previous robot interactions and (2) planning multiple skills into the future and replanning. We evaluate VLM-PC on several challenging real-world obstacle courses, involving dead ends and climbing and crawling, on a Go1 quadruped robot. Our experiments show that by reasoning over the history of interactions and future plans, VLMs enable the robot to autonomously perceive, navigate, and act in a wide range of complex scenarios that would otherwise require environment-specific engineering or human guidance.