 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$π^{*}_{0.6}$: a VLA That Learns From Experience
Nov 19, 2025We study how vision-language-action (VLA) models can improve through real-world deployments via reinforcement learning (RL). We present a general-purpose method, RL with Experience and Corrections via Advantage-conditioned Policies (RECAP), that provides for RL training of VLAs via advantage conditioning. Our method incorporates heterogeneous data into the self-improvement process, including demonstrations, data from on-policy collection, and expert teleoperated interventions provided during autonomous execution. RECAP starts by pre-training a generalist VLA with offline RL, which we call $π^{*}_{0.6}$, that can then be specialized to attain high performance on downstream tasks through on-robot data collection. We show that the $π^{*}_{0.6}$ model trained with the full RECAP method can fold laundry in real homes, reliably assemble boxes, and make espresso drinks using a professional espresso machine. On some of the hardest tasks, RECAP more than doubles task throughput and roughly halves the task failure rate.
$π_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Apr 22, 2025



In order for robots to be useful, they must perform practically relevant tasks in the real world, outside of the lab. While vision-language-action (VLA) models have demonstrated impressive results for end-to-end robot control, it remains an open question how far such models can generalize in the wild. We describe $\pi_{0.5}$, a new model based on $\pi_{0}$ that uses co-training on heterogeneous tasks to enable broad generalization. $\pi_{0.5}$\ uses data from multiple robots, high-level semantic prediction, web data, and other sources to enable broadly generalizable real-world robotic manipulation. Our system uses a combination of co-training and hybrid multi-modal examples that combine image observations, language commands, object detections, semantic subtask prediction, and low-level actions. Our experiments show that this kind of knowledge transfer is essential for effective generalization, and we demonstrate for the first time that an end-to-end learning-enabled robotic system can perform long-horizon and dexterous manipulation skills, such as cleaning a kitchen or bedroom, in entirely new homes.
STEER: Flexible Robotic Manipulation via Dense Language Grounding
Nov 05, 2024



The complexity of the real world demands robotic systems that can intelligently adapt to unseen situations. We present STEER, a robot learning framework that bridges high-level, commonsense reasoning with precise, flexible low-level control. Our approach translates complex situational awareness into actionable low-level behavior through training language-grounded policies with dense annotation. By structuring policy training around fundamental, modular manipulation skills expressed in natural language, STEER exposes an expressive interface for humans or Vision-Language Models (VLMs) to intelligently orchestrate the robot's behavior by reasoning about the task and context. Our experiments demonstrate the skills learned via STEER can be combined to synthesize novel behaviors to adapt to new situations or perform completely new tasks without additional data collection or training.
RT-Affordance: Affordances are Versatile Intermediate Representations for Robot Manipulation
Nov 05, 2024We explore how intermediate policy representations can facilitate generalization by providing guidance on how to perform manipulation tasks. Existing representations such as language, goal images, and trajectory sketches have been shown to be helpful, but these representations either do not provide enough context or provide over-specified context that yields less robust policies. We propose conditioning policies on affordances, which capture the pose of the robot at key stages of the task. Affordances offer expressive yet lightweight abstractions, are easy for users to specify, and facilitate efficient learning by transferring knowledge from large internet datasets. Our method, RT-Affordance, is a hierarchical model that first proposes an affordance plan given the task language, and then conditions the policy on this affordance plan to perform manipulation. Our model can flexibly bridge heterogeneous sources of supervision including large web datasets and robot trajectories. We additionally train our model on cheap-to-collect in-domain affordance images, allowing us to learn new tasks without collecting any additional costly robot trajectories. We show on a diverse set of novel tasks how RT-Affordance exceeds the performance of existing methods by over 50%, and we empirically demonstrate that affordances are robust to novel settings. Videos available at https://snasiriany.me/rt-affordance
Traversability-Aware Legged Navigation by Learning from Real-World Visual Data
Oct 14, 2024The enhanced mobility brought by legged locomotion empowers quadrupedal robots to navigate through complex and unstructured environments. However, optimizing agile locomotion while accounting for the varying energy costs of traversing different terrains remains an open challenge. Most previous work focuses on planning trajectories with traversability cost estimation based on human-labeled environmental features. However, this human-centric approach is insufficient because it does not account for the varying capabilities of the robot locomotion controllers over challenging terrains. To address this, we develop a novel traversability estimator in a robot-centric manner, based on the value function of the robot's locomotion controller. This estimator is integrated into a new learning-based RGBD navigation framework. The framework develops a planner that guides the robot in avoiding obstacles and hard-to-traverse terrains while reaching its goals. The training of the navigation planner is directly performed in the real world using a sample efficient reinforcement learning method. Through extensive benchmarking, we demonstrate that the proposed framework achieves the best performance in accurate traversability cost estimation and efficient learning from multi-modal data (the robot's color and depth vision, and proprioceptive feedback) for real-world training. Using the proposed method, a quadrupedal robot learns to perform traversability-aware navigation through trial and error in various real-world environments with challenging terrains that are difficult to classify using depth vision alone.
D5RL: Diverse Datasets for Data-Driven Deep Reinforcement Learning
Aug 15, 2024
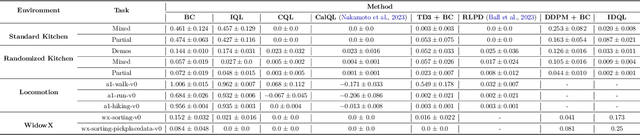

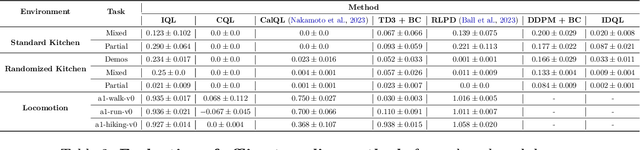
Offline reinforcement learning algorithms hold the promise of enabling data-driven RL methods that do not require costly or dangerous real-world exploration and benefit from large pre-collected datasets. This in turn can facilitate real-world applications, as well as a more standardized approach to RL research. Furthermore, offline RL methods can provide effective initializations for online finetuning to overcome challenges with exploration. However, evaluating progress on offline RL algorithms requires effective and challenging benchmarks that capture properties of real-world tasks, provide a range of task difficulties, and cover a range of challenges both in terms of the parameters of the domain (e.g., length of the horizon, sparsity of rewards) and the parameters of the data (e.g., narrow demonstration data or broad exploratory data). While considerable progress in offline RL in recent years has been enabled by simpler benchmark tasks, the most widely used datasets are increasingly saturating in performance and may fail to reflect properties of realistic tasks. We propose a new benchmark for offline RL that focuses on realistic simulations of robotic manipulation and locomotion environments, based on models of real-world robotic systems, and comprising a variety of data sources, including scripted data, play-style data collected by human teleoperators, and other data sources. Our proposed benchmark covers state-based and image-based domains, and supports both offline RL and online fine-tuning evaluation, with some of the tasks specifically designed to require both pre-training and fine-tuning. We hope that our proposed benchmark will facilitate further progress on both offline RL and fine-tuning algorithms. Website with code, examples, tasks, and data is available at \url{https://sites.google.com/view/d5rl/}
HiLMa-Res: A General Hierarchical Framework via Residual RL for Combining Quadrupedal Locomotion and Manipulation
Jul 09, 2024
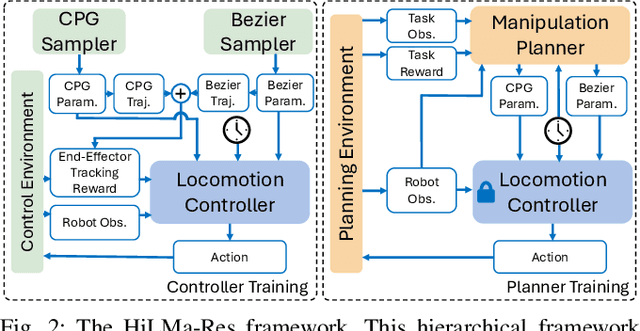
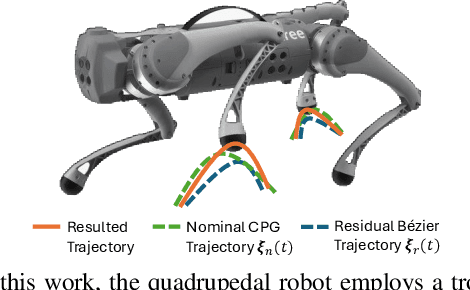

This work presents HiLMa-Res, a hierarchical framework leveraging reinforcement learning to tackle manipulation tasks while performing continuous locomotion using quadrupedal robots. Unlike most previous efforts that focus on solving a specific task, HiLMa-Res is designed to be general for various loco-manipulation tasks that require quadrupedal robots to maintain sustained mobility. The novel design of this framework tackles the challenges of integrating continuous locomotion control and manipulation using legs. It develops an operational space locomotion controller that can track arbitrary robot end-effector (toe) trajectories while walking at different velocities. This controller is designed to be general to different downstream tasks, and therefore, can be utilized in high-level manipulation planning policy to address specific tasks. To demonstrate the versatility of this framework, we utilize HiLMa-Res to tackle several challenging loco-manipulation tasks using a quadrupedal robot in the real world. These tasks span from leveraging state-based policy to vision-based policy, from training purely from the simulation data to learning from real-world data. In these tasks, HiLMa-Res shows better performance than other methods.
Commonsense Reasoning for Legged Robot Adaptation with Vision-Language Models
Jul 02, 2024Legged robots are physically capable of navigating a diverse variety of environments and overcoming a wide range of obstructions. For example, in a search and rescue mission, a legged robot could climb over debris, crawl through gaps, and navigate out of dead ends. However, the robot's controller needs to respond intelligently to such varied obstacles, and this requires handling unexpected and unusual scenarios successfully. This presents an open challenge to current learning methods, which often struggle with generalization to the long tail of unexpected situations without heavy human supervision. To address this issue, we investigate how to leverage the broad knowledge about the structure of the world and commonsense reasoning capabilities of vision-language models (VLMs) to aid legged robots in handling difficult, ambiguous situations. We propose a system, VLM-Predictive Control (VLM-PC), combining two key components that we find to be crucial for eliciting on-the-fly, adaptive behavior selection with VLMs: (1) in-context adaptation over previous robot interactions and (2) planning multiple skills into the future and replanning. We evaluate VLM-PC on several challenging real-world obstacle courses, involving dead ends and climbing and crawling, on a Go1 quadruped robot. Our experiments show that by reasoning over the history of interactions and future plans, VLMs enable the robot to autonomously perceive, navigate, and act in a wide range of complex scenarios that would otherwise require environment-specific engineering or human guidance.
Language Guided Skill Discovery
Jun 07, 2024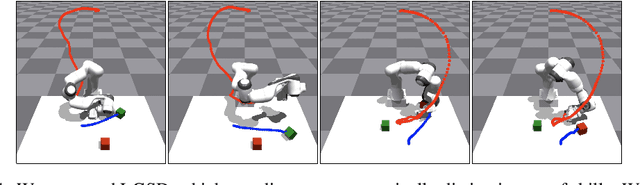

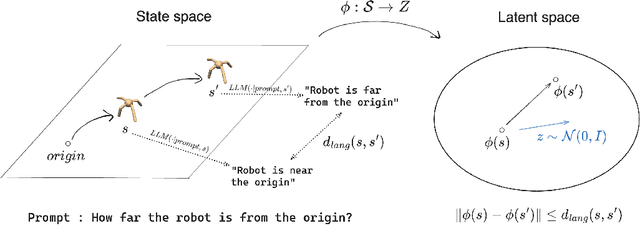
Skill discovery methods enable agents to learn diverse emergent behaviors without explicit rewards. To make learned skills useful for unknown downstream tasks, obtaining a semantically diverse repertoire of skills is essential. While some approaches introduce a discriminator to distinguish skills and others aim to increase state coverage, no existing work directly addresses the "semantic diversity" of skills. We hypothesize that leveraging the semantic knowledge of large language models (LLMs) can lead us to improve semantic diversity of resulting behaviors. In this sense, we introduce Language Guided Skill Discovery (LGSD), a skill discovery framework that aims to directly maximize the semantic diversity between skills. LGSD takes user prompts as input and outputs a set of semantically distinctive skills. The prompts serve as a means to constrain the search space into a semantically desired subspace, and the generated LLM outputs guide the agent to visit semantically diverse states within the subspace. We demonstrate that LGSD enables legged robots to visit different user-intended areas on a plane by simply changing the prompt. Furthermore, we show that language guidance aids in discovering more diverse skills compared to five existing skill discovery methods in robot-arm manipulation environments. Lastly, LGSD provides a simple way of utilizing learned skills via natural language.
Adapt On-the-Go: Behavior Modulation for Single-Life Robot Deployment
Nov 02, 2023To succeed in the real world, robots must cope with situations that differ from those seen during training. We study the problem of adapting on-the-fly to such novel scenarios during deployment, by drawing upon a diverse repertoire of previously learned behaviors. Our approach, RObust Autonomous Modulation (ROAM), introduces a mechanism based on the perceived value of pre-trained behaviors to select and adapt pre-trained behaviors to the situation at hand. Crucially, this adaptation process all happens within a single episode at test time, without any human supervision. We provide theoretical analysis of our selection mechanism and demonstrate that ROAM enables a robot to adapt rapidly to changes in dynamics both in simulation and on a real Go1 quadruped, even successfully moving forward with roller skates on its feet. Our approach adapts over 2x as efficiently compared to existing methods when facing a variety of out-of-distribution situations during deployment by effectively choosing and adapting relevant behaviors on-the-fly.