 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerceptive Humanoid Parkour: Chaining Dynamic Human Skills via Motion Matching
Feb 17, 2026While recent advances in humanoid locomotion have achieved stable walking on varied terrains, capturing the agility and adaptivity of highly dynamic human motions remains an open challenge. In particular, agile parkour in complex environments demands not only low-level robustness, but also human-like motion expressiveness, long-horizon skill composition, and perception-driven decision-making. In this paper, we present Perceptive Humanoid Parkour (PHP), a modular framework that enables humanoid robots to autonomously perform long-horizon, vision-based parkour across challenging obstacle courses. Our approach first leverages motion matching, formulated as nearest-neighbor search in a feature space, to compose retargeted atomic human skills into long-horizon kinematic trajectories. This framework enables the flexible composition and smooth transition of complex skill chains while preserving the elegance and fluidity of dynamic human motions. Next, we train motion-tracking reinforcement learning (RL) expert policies for these composed motions, and distill them into a single depth-based, multi-skill student policy, using a combination of DAgger and RL. Crucially, the combination of perception and skill composition enables autonomous, context-aware decision-making: using only onboard depth sensing and a discrete 2D velocity command, the robot selects and executes whether to step over, climb onto, vault or roll off obstacles of varying geometries and heights. We validate our framework with extensive real-world experiments on a Unitree G1 humanoid robot, demonstrating highly dynamic parkour skills such as climbing tall obstacles up to 1.25m (96% robot height), as well as long-horizon multi-obstacle traversal with closed-loop adaptation to real-time obstacle perturbations.
Flow Policy Gradients for Robot Control
Feb 02, 2026Likelihood-based policy gradient methods are the dominant approach for training robot control policies from rewards. These methods rely on differentiable action likelihoods, which constrain policy outputs to simple distributions like Gaussians. In this work, we show how flow matching policy gradients -- a recent framework that bypasses likelihood computation -- can be made effective for training and fine-tuning more expressive policies in challenging robot control settings. We introduce an improved objective that enables success in legged locomotion, humanoid motion tracking, and manipulation tasks, as well as robust sim-to-real transfer on two humanoid robots. We then present ablations and analysis on training dynamics. Results show how policies can exploit the flow representation for exploration when training from scratch, as well as improved fine-tuning robustness over baselines.
From Black Box to Bijection: Interpreting Machine Learning to Build a Zeta Map Algorithm
Nov 16, 2025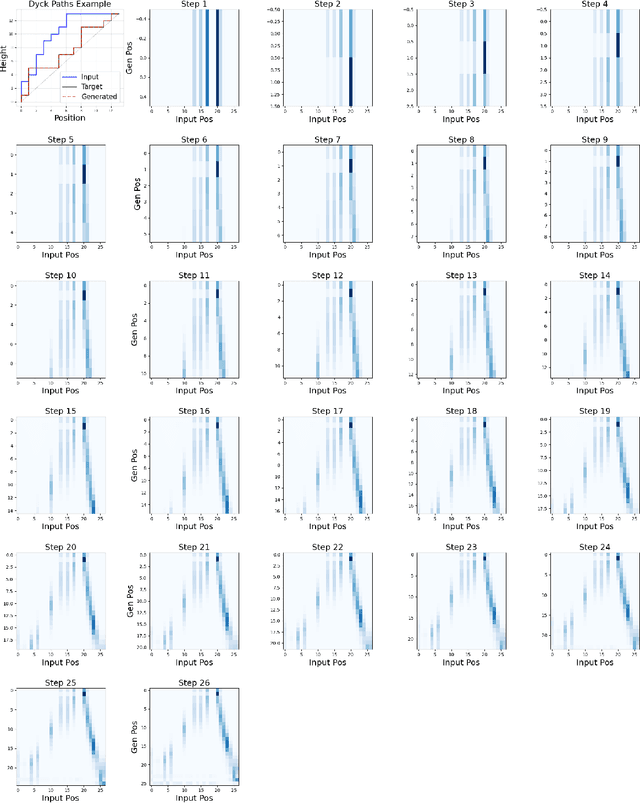
There is a large class of problems in algebraic combinatorics which can be distilled into the same challenge: construct an explicit combinatorial bijection. Traditionally, researchers have solved challenges like these by visually inspecting the data for patterns, formulating conjectures, and then proving them. But what is to be done if patterns fail to emerge until the data grows beyond human scale? In this paper, we propose a new workflow for discovering combinatorial bijections via machine learning. As a proof of concept, we train a transformer on paired Dyck paths and use its learned attention patterns to derive a new algorithmic description of the zeta map, which we call the \textit{Scaffolding Map}.
OmniRetarget: Interaction-Preserving Data Generation for Humanoid Whole-Body Loco-Manipulation and Scene Interaction
Sep 30, 2025A dominant paradigm for teaching humanoid robots complex skills is to retarget human motions as kinematic references to train reinforcement learning (RL) policies. However, existing retargeting pipelines often struggle with the significant embodiment gap between humans and robots, producing physically implausible artifacts like foot-skating and penetration. More importantly, common retargeting methods neglect the rich human-object and human-environment interactions essential for expressive locomotion and loco-manipulation. To address this, we introduce OmniRetarget, an interaction-preserving data generation engine based on an interaction mesh that explicitly models and preserves the crucial spatial and contact relationships between an agent, the terrain, and manipulated objects. By minimizing the Laplacian deformation between the human and robot meshes while enforcing kinematic constraints, OmniRetarget generates kinematically feasible trajectories. Moreover, preserving task-relevant interactions enables efficient data augmentation, from a single demonstration to different robot embodiments, terrains, and object configurations. We comprehensively evaluate OmniRetarget by retargeting motions from OMOMO, LAFAN1, and our in-house MoCap datasets, generating over 8-hour trajectories that achieve better kinematic constraint satisfaction and contact preservation than widely used baselines. Such high-quality data enables proprioceptive RL policies to successfully execute long-horizon (up to 30 seconds) parkour and loco-manipulation skills on a Unitree G1 humanoid, trained with only 5 reward terms and simple domain randomization shared by all tasks, without any learning curriculum.
BeyondMimic: From Motion Tracking to Versatile Humanoid Control via Guided Diffusion
Aug 13, 2025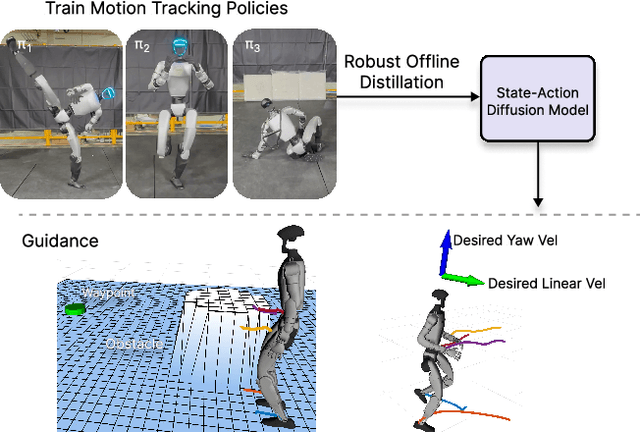



Learning skills from human motions offers a promising path toward generalizable policies for versatile humanoid whole-body control, yet two key cornerstones are missing: (1) a high-quality motion tracking framework that faithfully transforms large-scale kinematic references into robust and extremely dynamic motions on real hardware, and (2) a distillation approach that can effectively learn these motion primitives and compose them to solve downstream tasks. We address these gaps with BeyondMimic, a real-world framework to learn from human motions for versatile and naturalistic humanoid control via guided diffusion. Our framework provides a motion tracking pipeline capable of challenging skills such as jumping spins, sprinting, and cartwheels with state-of-the-art motion quality. Moving beyond simply mimicking existing motions, we further introduce a unified diffusion policy that enables zero-shot task-specific control at test time using simple cost functions. Deployed on hardware, BeyondMimic performs diverse tasks at test time, including waypoint navigation, joystick teleoperation, and obstacle avoidance, bridging sim-to-real motion tracking and flexible synthesis of human motion primitives for whole-body control. https://beyondmimic.github.io/.
LeVERB: Humanoid Whole-Body Control with Latent Vision-Language Instruction
Jun 16, 2025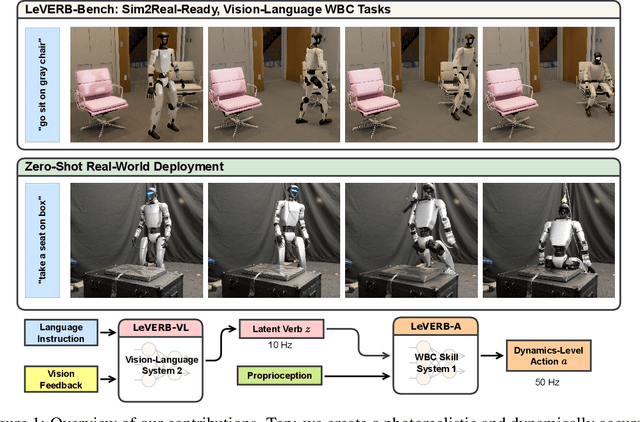
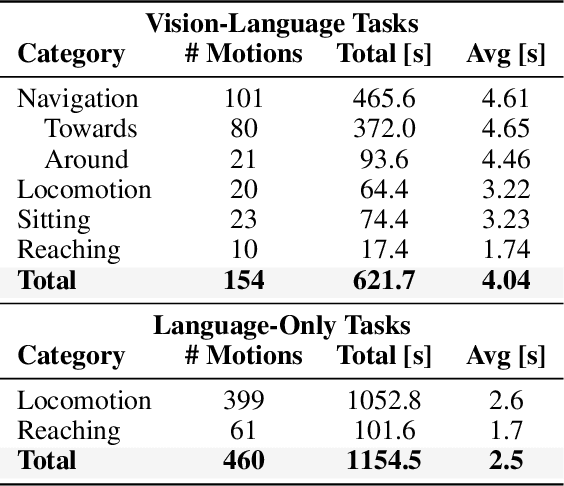
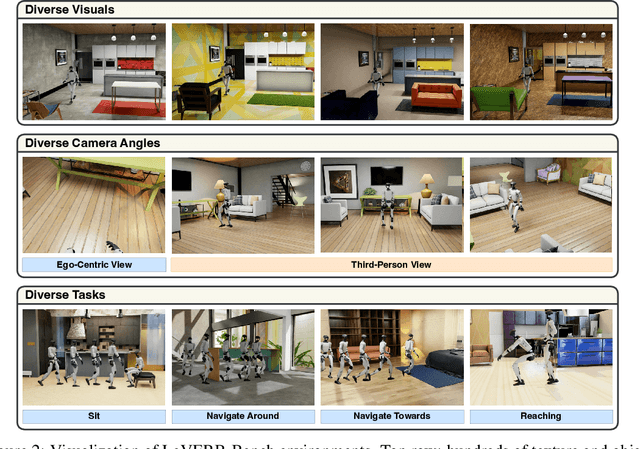
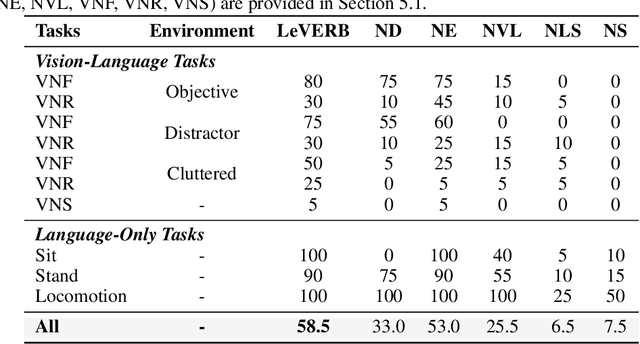
Vision-language-action (VLA) models have demonstrated strong semantic understanding and zero-shot generalization, yet most existing systems assume an accurate low-level controller with hand-crafted action "vocabulary" such as end-effector pose or root velocity. This assumption confines prior work to quasi-static tasks and precludes the agile, whole-body behaviors required by humanoid whole-body control (WBC) tasks. To capture this gap in the literature, we start by introducing the first sim-to-real-ready, vision-language, closed-loop benchmark for humanoid WBC, comprising over 150 tasks from 10 categories. We then propose LeVERB: Latent Vision-Language-Encoded Robot Behavior, a hierarchical latent instruction-following framework for humanoid vision-language WBC, the first of its kind. At the top level, a vision-language policy learns a latent action vocabulary from synthetically rendered kinematic demonstrations; at the low level, a reinforcement-learned WBC policy consumes these latent verbs to generate dynamics-level commands. In our benchmark, LeVERB can zero-shot attain a 80% success rate on simple visual navigation tasks, and 58.5% success rate overall, outperforming naive hierarchical whole-body VLA implementation by 7.8 times.
LangWBC: Language-directed Humanoid Whole-Body Control via End-to-end Learning
Apr 30, 2025General-purpose humanoid robots are expected to interact intuitively with humans, enabling seamless integration into daily life. Natural language provides the most accessible medium for this purpose. However, translating language into humanoid whole-body motion remains a significant challenge, primarily due to the gap between linguistic understanding and physical actions. In this work, we present an end-to-end, language-directed policy for real-world humanoid whole-body control. Our approach combines reinforcement learning with policy distillation, allowing a single neural network to interpret language commands and execute corresponding physical actions directly. To enhance motion diversity and compositionality, we incorporate a Conditional Variational Autoencoder (CVAE) structure. The resulting policy achieves agile and versatile whole-body behaviors conditioned on language inputs, with smooth transitions between various motions, enabling adaptation to linguistic variations and the emergence of novel motions. We validate the efficacy and generalizability of our method through extensive simulations and real-world experiments, demonstrating robust whole-body control. Please see our website at LangWBC.github.io for more information.
Demonstrating Berkeley Humanoid Lite: An Open-source, Accessible, and Customizable 3D-printed Humanoid Robot
Apr 24, 2025Despite significant interest and advancements in humanoid robotics, most existing commercially available hardware remains high-cost, closed-source, and non-transparent within the robotics community. This lack of accessibility and customization hinders the growth of the field and the broader development of humanoid technologies. To address these challenges and promote democratization in humanoid robotics, we demonstrate Berkeley Humanoid Lite, an open-source humanoid robot designed to be accessible, customizable, and beneficial for the entire community. The core of this design is a modular 3D-printed gearbox for the actuators and robot body. All components can be sourced from widely available e-commerce platforms and fabricated using standard desktop 3D printers, keeping the total hardware cost under $5,000 (based on U.S. market prices). The design emphasizes modularity and ease of fabrication. To address the inherent limitations of 3D-printed gearboxes, such as reduced strength and durability compared to metal alternatives, we adopted a cycloidal gear design, which provides an optimal form factor in this context. Extensive testing was conducted on the 3D-printed actuators to validate their durability and alleviate concerns about the reliability of plastic components. To demonstrate the capabilities of Berkeley Humanoid Lite, we conducted a series of experiments, including the development of a locomotion controller using reinforcement learning. These experiments successfully showcased zero-shot policy transfer from simulation to hardware, highlighting the platform's suitability for research validation. By fully open-sourcing the hardware design, embedded code, and training and deployment frameworks, we aim for Berkeley Humanoid Lite to serve as a pivotal step toward democratizing the development of humanoid robotics. All resources are available at https://lite.berkeley-humanoid.org.
Diffuse-CLoC: Guided Diffusion for Physics-based Character Look-ahead Control
Mar 14, 2025We present Diffuse-CLoC, a guided diffusion framework for physics-based look-ahead control that enables intuitive, steerable, and physically realistic motion generation. While existing kinematics motion generation with diffusion models offer intuitive steering capabilities with inference-time conditioning, they often fail to produce physically viable motions. In contrast, recent diffusion-based control policies have shown promise in generating physically realizable motion sequences, but the lack of kinematics prediction limits their steerability. Diffuse-CLoC addresses these challenges through a key insight: modeling the joint distribution of states and actions within a single diffusion model makes action generation steerable by conditioning it on the predicted states. This approach allows us to leverage established conditioning techniques from kinematic motion generation while producing physically realistic motions. As a result, we achieve planning capabilities without the need for a high-level planner. Our method handles a diverse set of unseen long-horizon downstream tasks through a single pre-trained model, including static and dynamic obstacle avoidance, motion in-betweening, and task-space control. Experimental results show that our method significantly outperforms the traditional hierarchical framework of high-level motion diffusion and low-level tracking.
3rd Workshop on Maritime Computer Vision (MaCVi) 2025: Challenge Results
Jan 17, 2025The 3rd Workshop on Maritime Computer Vision (MaCVi) 2025 addresses maritime computer vision for Unmanned Surface Vehicles (USV) and underwater. This report offers a comprehensive overview of the findings from the challenges. We provide both statistical and qualitative analyses, evaluating trends from over 700 submissions. All datasets, evaluation code, and the leaderboard are available to the public at https://macvi.org/workshop/macvi25.