 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Adaptable Humanoid Control via Adaptive Motion Tracking
Oct 16, 2025Humanoid robots are envisioned to adapt demonstrated motions to diverse real-world conditions while accurately preserving motion patterns. Existing motion prior approaches enable well adaptability with a few motions but often sacrifice imitation accuracy, whereas motion-tracking methods achieve accurate imitation yet require many training motions and a test-time target motion to adapt. To combine their strengths, we introduce AdaMimic, a novel motion tracking algorithm that enables adaptable humanoid control from a single reference motion. To reduce data dependence while ensuring adaptability, our method first creates an augmented dataset by sparsifying the single reference motion into keyframes and applying light editing with minimal physical assumptions. A policy is then initialized by tracking these sparse keyframes to generate dense intermediate motions, and adapters are subsequently trained to adjust tracking speed and refine low-level actions based on the adjustment, enabling flexible time warping that further improves imitation accuracy and adaptability. We validate these significant improvements in our approach in both simulation and the real-world Unitree G1 humanoid robot in multiple tasks across a wide range of adaptation conditions. Videos and code are available at https://taohuang13.github.io/adamimic.github.io/.
Demonstrating Berkeley Humanoid Lite: An Open-source, Accessible, and Customizable 3D-printed Humanoid Robot
Apr 24, 2025Despite significant interest and advancements in humanoid robotics, most existing commercially available hardware remains high-cost, closed-source, and non-transparent within the robotics community. This lack of accessibility and customization hinders the growth of the field and the broader development of humanoid technologies. To address these challenges and promote democratization in humanoid robotics, we demonstrate Berkeley Humanoid Lite, an open-source humanoid robot designed to be accessible, customizable, and beneficial for the entire community. The core of this design is a modular 3D-printed gearbox for the actuators and robot body. All components can be sourced from widely available e-commerce platforms and fabricated using standard desktop 3D printers, keeping the total hardware cost under $5,000 (based on U.S. market prices). The design emphasizes modularity and ease of fabrication. To address the inherent limitations of 3D-printed gearboxes, such as reduced strength and durability compared to metal alternatives, we adopted a cycloidal gear design, which provides an optimal form factor in this context. Extensive testing was conducted on the 3D-printed actuators to validate their durability and alleviate concerns about the reliability of plastic components. To demonstrate the capabilities of Berkeley Humanoid Lite, we conducted a series of experiments, including the development of a locomotion controller using reinforcement learning. These experiments successfully showcased zero-shot policy transfer from simulation to hardware, highlighting the platform's suitability for research validation. By fully open-sourcing the hardware design, embedded code, and training and deployment frameworks, we aim for Berkeley Humanoid Lite to serve as a pivotal step toward democratizing the development of humanoid robotics. All resources are available at https://lite.berkeley-humanoid.org.
Learning Humanoid Locomotion with Perceptive Internal Model
Nov 21, 2024
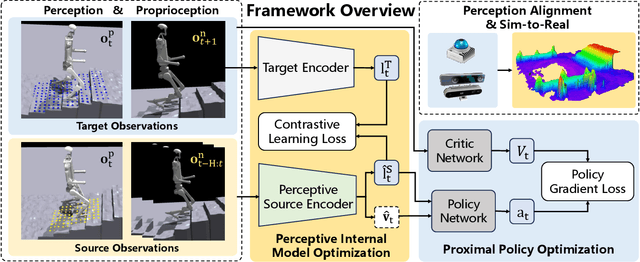
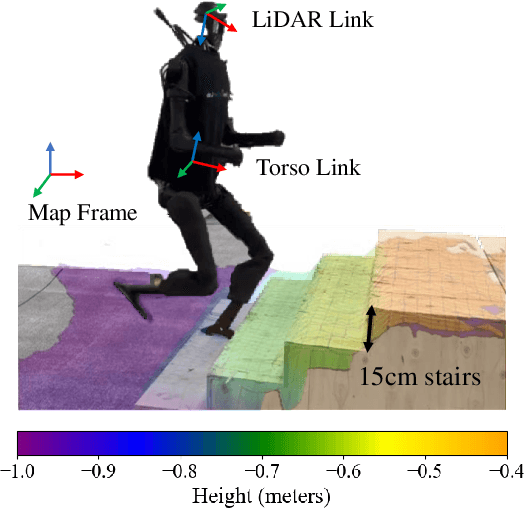

In contrast to quadruped robots that can navigate diverse terrains using a "blind" policy, humanoid robots require accurate perception for stable locomotion due to their high degrees of freedom and inherently unstable morphology. However, incorporating perceptual signals often introduces additional disturbances to the system, potentially reducing its robustness, generalizability, and efficiency. This paper presents the Perceptive Internal Model (PIM), which relies on onboard, continuously updated elevation maps centered around the robot to perceive its surroundings. We train the policy using ground-truth obstacle heights surrounding the robot in simulation, optimizing it based on the Hybrid Internal Model (HIM), and perform inference with heights sampled from the constructed elevation map. Unlike previous methods that directly encode depth maps or raw point clouds, our approach allows the robot to perceive the terrain beneath its feet clearly and is less affected by camera movement or noise. Furthermore, since depth map rendering is not required in simulation, our method introduces minimal additional computational costs and can train the policy in 3 hours on an RTX 4090 GPU. We verify the effectiveness of our method across various humanoid robots, various indoor and outdoor terrains, stairs, and various sensor configurations. Our method can enable a humanoid robot to continuously climb stairs and has the potential to serve as a foundational algorithm for the development of future humanoid control methods.
Dual-Channel Latent Factor Analysis Enhanced Graph Contrastive Learning for Recommendation
Aug 09, 2024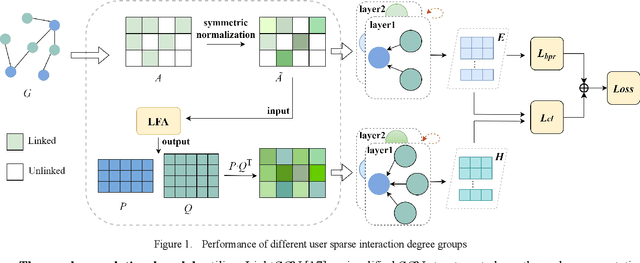
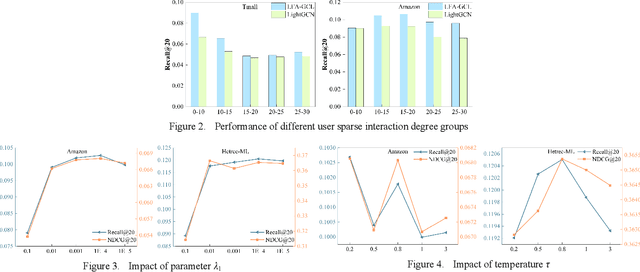
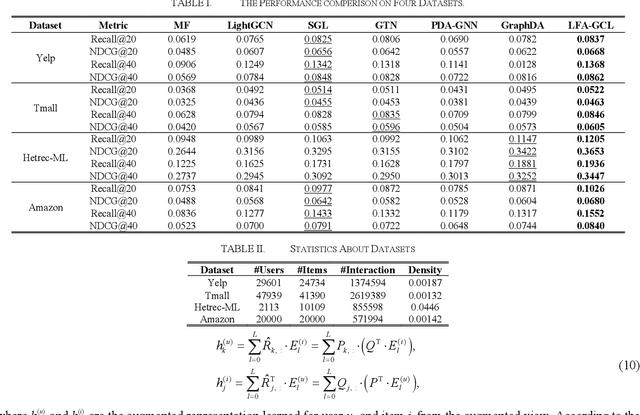
Graph Neural Networks (GNNs) are powerful learning methods for recommender systems owing to their robustness in handling complicated user-item interactions. Recently, the integration of contrastive learning with GNNs has demonstrated remarkable performance in recommender systems to handle the issue of highly sparse user-item interaction data. Yet, some available graph contrastive learning (GCL) techniques employ stochastic augmentation, i.e., nodes or edges are randomly perturbed on the user-item bipartite graph to construct contrastive views. Such a stochastic augmentation strategy not only brings noise perturbation but also cannot utilize global collaborative signals effectively. To address it, this study proposes a latent factor analysis (LFA) enhanced GCL approach, named LFA-GCL. Our model exclusively incorporates LFA to implement the unconstrained structural refinement, thereby obtaining an augmented global collaborative graph accurately without introducing noise signals. Experiments on four public datasets show that the proposed LFA-GCL outperforms the state-of-the-art models.
GRUtopia: Dream General Robots in a City at Scale
Jul 15, 2024Recent works have been exploring the scaling laws in the field of Embodied AI. Given the prohibitive costs of collecting real-world data, we believe the Simulation-to-Real (Sim2Real) paradigm is a crucial step for scaling the learning of embodied models. This paper introduces project GRUtopia, the first simulated interactive 3D society designed for various robots. It features several advancements: (a) The scene dataset, GRScenes, includes 100k interactive, finely annotated scenes, which can be freely combined into city-scale environments. In contrast to previous works mainly focusing on home, GRScenes covers 89 diverse scene categories, bridging the gap of service-oriented environments where general robots would be initially deployed. (b) GRResidents, a Large Language Model (LLM) driven Non-Player Character (NPC) system that is responsible for social interaction, task generation, and task assignment, thus simulating social scenarios for embodied AI applications. (c) The benchmark, GRBench, supports various robots but focuses on legged robots as primary agents and poses moderately challenging tasks involving Object Loco-Navigation, Social Loco-Navigation, and Loco-Manipulation. We hope that this work can alleviate the scarcity of high-quality data in this field and provide a more comprehensive assessment of Embodied AI research. The project is available at https://github.com/OpenRobotLab/GRUtopia.
Learning H-Infinity Locomotion Control
Apr 22, 2024Stable locomotion in precipitous environments is an essential capability of quadruped robots, demanding the ability to resist various external disturbances. However, recent learning-based policies only use basic domain randomization to improve the robustness of learned policies, which cannot guarantee that the robot has adequate disturbance resistance capabilities. In this paper, we propose to model the learning process as an adversarial interaction between the actor and a newly introduced disturber and ensure their optimization with $H_{\infty}$ constraint. In contrast to the actor that maximizes the discounted overall reward, the disturber is responsible for generating effective external forces and is optimized by maximizing the error between the task reward and its oracle, i.e., "cost" in each iteration. To keep joint optimization between the actor and the disturber stable, our $H_{\infty}$ constraint mandates the bound of ratio between the cost to the intensity of the external forces. Through reciprocal interaction throughout the training phase, the actor can acquire the capability to navigate increasingly complex physical disturbances. We verify the robustness of our approach on quadrupedal locomotion tasks with Unitree Aliengo robot, and also a more challenging task with Unitree A1 robot, where the quadruped is expected to perform locomotion merely on its hind legs as if it is a bipedal robot. The simulated quantitative results show improvement against baselines, demonstrating the effectiveness of the method and each design choice. On the other hand, real-robot experiments qualitatively exhibit how robust the policy is when interfering with various disturbances on various terrains, including stairs, high platforms, slopes, and slippery terrains. All code, checkpoints, and real-world deployment guidance will be made public.
Hybrid Internal Model: Learning Agile Legged Locomotion with Simulated Robot Response
Jan 02, 2024Robust locomotion control depends on accurate state estimations. However, the sensors of most legged robots can only provide partial and noisy observations, making the estimation particularly challenging, especially for external states like terrain frictions and elevation maps. Inspired by the classical Internal Model Control principle, we consider these external states as disturbances and introduce Hybrid Internal Model (HIM) to estimate them according to the response of the robot. The response, which we refer to as the hybrid internal embedding, contains the robot's explicit velocity and implicit stability representation, corresponding to two primary goals for locomotion tasks: explicitly tracking velocity and implicitly maintaining stability. We use contrastive learning to optimize the embedding to be close to the robot's successor state, in which the response is naturally embedded. HIM has several appealing benefits: It only needs the robot's proprioceptions, i.e., those from joint encoders and IMU as observations. It innovatively maintains consistent observations between simulation reference and reality that avoids information loss in mimicking learning. It exploits batch-level information that is more robust to noises and keeps better sample efficiency. It only requires 1 hour of training on an RTX 4090 to enable a quadruped robot to traverse any terrain under any disturbances. A wealth of real-world experiments demonstrates its agility, even in high-difficulty tasks and cases never occurred during the training process, revealing remarkable open-world generalizability.