 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAstRL: Analog and Mixed-Signal Circuit Synthesis with Deep Reinforcement Learning
Feb 12, 2026Analog and mixed-signal (AMS) integrated circuits (ICs) lie at the core of modern computing and communications systems. However, despite the continued rise in design complexity, advances in AMS automation remain limited. This reflects the central challenge in developing a generalized optimization method applicable across diverse circuit design spaces, many of which are distinct, constrained, and non-differentiable. To address this, our work casts circuit design as a graph generation problem and introduces a novel method of AMS synthesis driven by deep reinforcement learning (AstRL). Based on a policy-gradient approach, AstRL generates circuits directly optimized for user-specified targets within a simulator-embedded environment that provides ground-truth feedback during training. Through behavioral-cloning and discriminator-based similarity rewards, our method demonstrates, for the first time, an expert-aligned paradigm for generalized circuit generation validated in simulation. Importantly, the proposed approach operates at the level of individual transistors, enabling highly expressive, fine-grained topology generation. Strong inductive biases encoded in the action space and environment further drive structurally consistent and valid generation. Experimental results for three realistic design tasks illustrate substantial improvements in conventional design metrics over state-of-the-art baselines, with 100% of generated designs being structurally correct and over 90% demonstrating required functionality.
Demonstrating Berkeley Humanoid Lite: An Open-source, Accessible, and Customizable 3D-printed Humanoid Robot
Apr 24, 2025Despite significant interest and advancements in humanoid robotics, most existing commercially available hardware remains high-cost, closed-source, and non-transparent within the robotics community. This lack of accessibility and customization hinders the growth of the field and the broader development of humanoid technologies. To address these challenges and promote democratization in humanoid robotics, we demonstrate Berkeley Humanoid Lite, an open-source humanoid robot designed to be accessible, customizable, and beneficial for the entire community. The core of this design is a modular 3D-printed gearbox for the actuators and robot body. All components can be sourced from widely available e-commerce platforms and fabricated using standard desktop 3D printers, keeping the total hardware cost under $5,000 (based on U.S. market prices). The design emphasizes modularity and ease of fabrication. To address the inherent limitations of 3D-printed gearboxes, such as reduced strength and durability compared to metal alternatives, we adopted a cycloidal gear design, which provides an optimal form factor in this context. Extensive testing was conducted on the 3D-printed actuators to validate their durability and alleviate concerns about the reliability of plastic components. To demonstrate the capabilities of Berkeley Humanoid Lite, we conducted a series of experiments, including the development of a locomotion controller using reinforcement learning. These experiments successfully showcased zero-shot policy transfer from simulation to hardware, highlighting the platform's suitability for research validation. By fully open-sourcing the hardware design, embedded code, and training and deployment frameworks, we aim for Berkeley Humanoid Lite to serve as a pivotal step toward democratizing the development of humanoid robotics. All resources are available at https://lite.berkeley-humanoid.org.
DiffuseLoco: Real-Time Legged Locomotion Control with Diffusion from Offline Datasets
Apr 30, 2024
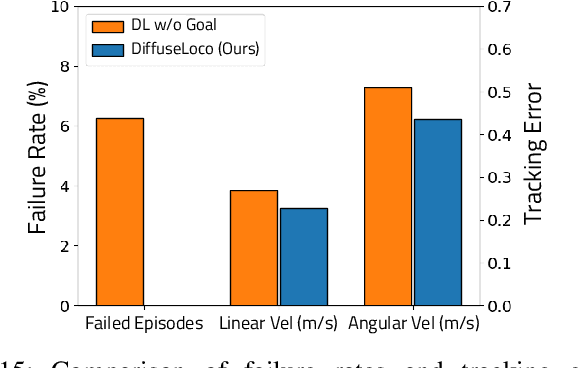
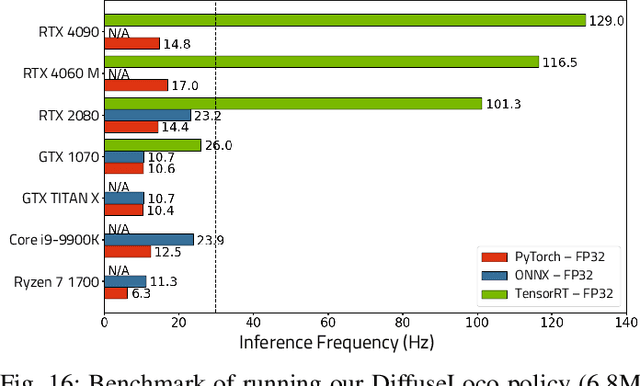

This work introduces DiffuseLoco, a framework for training multi-skill diffusion-based policies for dynamic legged locomotion from offline datasets, enabling real-time control of diverse skills on robots in the real world. Offline learning at scale has led to breakthroughs in computer vision, natural language processing, and robotic manipulation domains. However, scaling up learning for legged robot locomotion, especially with multiple skills in a single policy, presents significant challenges for prior online reinforcement learning methods. To address this challenge, we propose a novel, scalable framework that leverages diffusion models to directly learn from offline multimodal datasets with a diverse set of locomotion skills. With design choices tailored for real-time control in dynamical systems, including receding horizon control and delayed inputs, DiffuseLoco is capable of reproducing multimodality in performing various locomotion skills, zero-shot transfer to real quadrupedal robots, and it can be deployed on edge computing devices. Furthermore, DiffuseLoco demonstrates free transitions between skills and robustness against environmental variations. Through extensive benchmarking in real-world experiments, DiffuseLoco exhibits better stability and velocity tracking performance compared to prior reinforcement learning and non-diffusion-based behavior cloning baselines. The design choices are validated via comprehensive ablation studies. This work opens new possibilities for scaling up learning-based legged locomotion controllers through the scaling of large, expressive models and diverse offline datasets.
Gemmini: An Agile Systolic Array Generator Enabling Systematic Evaluations of Deep-Learning Architectures
Dec 07, 2019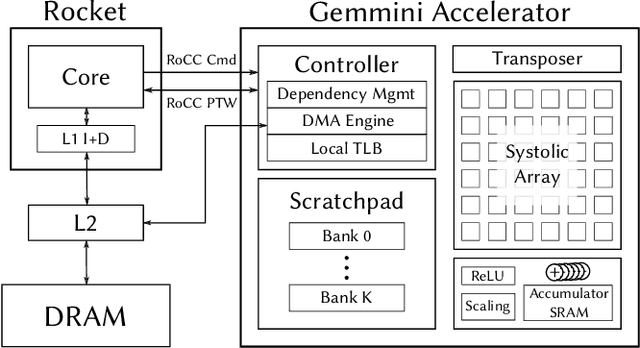
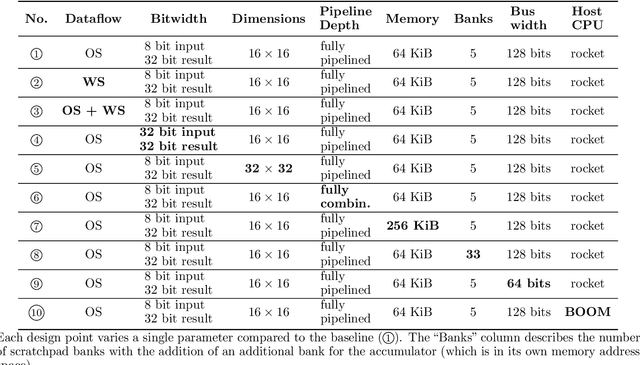
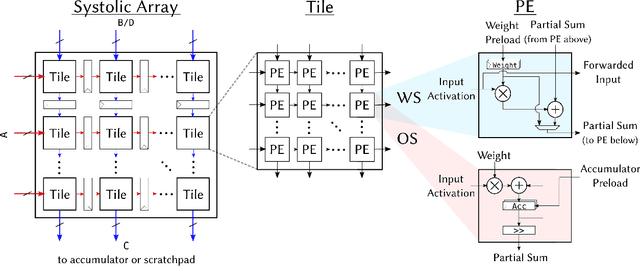
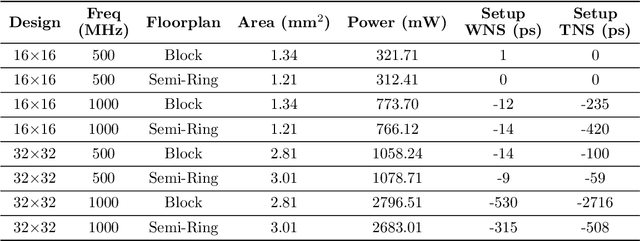
Advances in deep learning and neural networks have resulted in the rapid development of hardware accelerators that support them. A large majority of ASIC accelerators, however, target a single hardware design point to accelerate the main computational kernels of deep neural networks such as convolutions or matrix multiplication. On the other hand, the spectrum of use-cases for neural network accelerators, ranging from edge devices to cloud, presents a prime opportunity for agile hardware design and generator methodologies. We present Gemmini -- an open source and agile systolic array generator enabling systematic evaluations of deep-learning architectures. Gemmini generates a custom ASIC accelerator for matrix multiplication based on a systolic array architecture, complete with additional functions for neural network inference. Gemmini runs with the RISC-V ISA, and is integrated with the Rocket Chip System-on-Chip generator ecosystem, including Rocket in-order cores and BOOM out-of-order cores. Through an elaborate design space exploration case study, this work demonstrates the selection processes of various parameters for the use-case of inference on edge devices. Selected design points achieve two to three orders of magnitude speedup in deep neural network inference compared to the baseline execution on a host processor. Gemmini-generated accelerators were used in the fabrication of test systems-on-chip in TSMC 16nm and Intel 22FFL process technologies.