 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerceptive Humanoid Parkour: Chaining Dynamic Human Skills via Motion Matching
Feb 17, 2026While recent advances in humanoid locomotion have achieved stable walking on varied terrains, capturing the agility and adaptivity of highly dynamic human motions remains an open challenge. In particular, agile parkour in complex environments demands not only low-level robustness, but also human-like motion expressiveness, long-horizon skill composition, and perception-driven decision-making. In this paper, we present Perceptive Humanoid Parkour (PHP), a modular framework that enables humanoid robots to autonomously perform long-horizon, vision-based parkour across challenging obstacle courses. Our approach first leverages motion matching, formulated as nearest-neighbor search in a feature space, to compose retargeted atomic human skills into long-horizon kinematic trajectories. This framework enables the flexible composition and smooth transition of complex skill chains while preserving the elegance and fluidity of dynamic human motions. Next, we train motion-tracking reinforcement learning (RL) expert policies for these composed motions, and distill them into a single depth-based, multi-skill student policy, using a combination of DAgger and RL. Crucially, the combination of perception and skill composition enables autonomous, context-aware decision-making: using only onboard depth sensing and a discrete 2D velocity command, the robot selects and executes whether to step over, climb onto, vault or roll off obstacles of varying geometries and heights. We validate our framework with extensive real-world experiments on a Unitree G1 humanoid robot, demonstrating highly dynamic parkour skills such as climbing tall obstacles up to 1.25m (96% robot height), as well as long-horizon multi-obstacle traversal with closed-loop adaptation to real-time obstacle perturbations.
OmniRetarget: Interaction-Preserving Data Generation for Humanoid Whole-Body Loco-Manipulation and Scene Interaction
Sep 30, 2025A dominant paradigm for teaching humanoid robots complex skills is to retarget human motions as kinematic references to train reinforcement learning (RL) policies. However, existing retargeting pipelines often struggle with the significant embodiment gap between humans and robots, producing physically implausible artifacts like foot-skating and penetration. More importantly, common retargeting methods neglect the rich human-object and human-environment interactions essential for expressive locomotion and loco-manipulation. To address this, we introduce OmniRetarget, an interaction-preserving data generation engine based on an interaction mesh that explicitly models and preserves the crucial spatial and contact relationships between an agent, the terrain, and manipulated objects. By minimizing the Laplacian deformation between the human and robot meshes while enforcing kinematic constraints, OmniRetarget generates kinematically feasible trajectories. Moreover, preserving task-relevant interactions enables efficient data augmentation, from a single demonstration to different robot embodiments, terrains, and object configurations. We comprehensively evaluate OmniRetarget by retargeting motions from OMOMO, LAFAN1, and our in-house MoCap datasets, generating over 8-hour trajectories that achieve better kinematic constraint satisfaction and contact preservation than widely used baselines. Such high-quality data enables proprioceptive RL policies to successfully execute long-horizon (up to 30 seconds) parkour and loco-manipulation skills on a Unitree G1 humanoid, trained with only 5 reward terms and simple domain randomization shared by all tasks, without any learning curriculum.
A New Semidefinite Relaxation for Linear and Piecewise-Affine Optimal Control with Time Scaling
Apr 17, 2025We introduce a semidefinite relaxation for optimal control of linear systems with time scaling. These problems are inherently nonconvex, since the system dynamics involves bilinear products between the discretization time step and the system state and controls. The proposed relaxation is closely related to the standard second-order semidefinite relaxation for quadratic constraints, but we carefully select a subset of the possible bilinear terms and apply a change of variables to achieve empirically tight relaxations while keeping the computational load light. We further extend our method to handle piecewise-affine (PWA) systems by formulating the PWA optimal-control problem as a shortest-path problem in a graph of convex sets (GCS). In this GCS, different paths represent different mode sequences for the PWA system, and the convex sets model the relaxed dynamics within each mode. By combining a tight convex relaxation of the GCS problem with our semidefinite relaxation with time scaling, we can solve PWA optimal-control problems through a single semidefinite program.
Physics-Driven Data Generation for Contact-Rich Manipulation via Trajectory Optimization
Feb 27, 2025



We present a low-cost data generation pipeline that integrates physics-based simulation, human demonstrations, and model-based planning to efficiently generate large-scale, high-quality datasets for contact-rich robotic manipulation tasks. Starting with a small number of embodiment-flexible human demonstrations collected in a virtual reality simulation environment, the pipeline refines these demonstrations using optimization-based kinematic retargeting and trajectory optimization to adapt them across various robot embodiments and physical parameters. This process yields a diverse, physically consistent dataset that enables cross-embodiment data transfer, and offers the potential to reuse legacy datasets collected under different hardware configurations or physical parameters. We validate the pipeline's effectiveness by training diffusion policies from the generated datasets for challenging contact-rich manipulation tasks across multiple robot embodiments, including a floating Allegro hand and bimanual robot arms. The trained policies are deployed zero-shot on hardware for bimanual iiwa arms, achieving high success rates with minimal human input. Project website: https://lujieyang.github.io/physicsgen/.
Lyapunov-stable Neural Control for State and Output Feedback: A Novel Formulation for Efficient Synthesis and Verification
Apr 11, 2024



Learning-based neural network (NN) control policies have shown impressive empirical performance in a wide range of tasks in robotics and control. However, formal (Lyapunov) stability guarantees over the region-of-attraction (ROA) for NN controllers with nonlinear dynamical systems are challenging to obtain, and most existing approaches rely on expensive solvers such as sums-of-squares (SOS), mixed-integer programming (MIP), or satisfiability modulo theories (SMT). In this paper, we demonstrate a new framework for learning NN controllers together with Lyapunov certificates using fast empirical falsification and strategic regularizations. We propose a novel formulation that defines a larger verifiable region-of-attraction (ROA) than shown in the literature, and refines the conventional restrictive constraints on Lyapunov derivatives to focus only on certifiable ROAs. The Lyapunov condition is rigorously verified post-hoc using branch-and-bound with scalable linear bound propagation-based NN verification techniques. The approach is efficient and flexible, and the full training and verification procedure is accelerated on GPUs without relying on expensive solvers for SOS, MIP, nor SMT. The flexibility and efficiency of our framework allow us to demonstrate Lyapunov-stable output feedback control with synthesized NN-based controllers and NN-based observers with formal stability guarantees, for the first time in literature. Source code at https://github.com/Verified-Intelligence/Lyapunov_Stable_NN_Controllers.
Fighting Uncertainty with Gradients: Offline Reinforcement Learning via Diffusion Score Matching
Jun 24, 2023



Offline optimization paradigms such as offline Reinforcement Learning (RL) or Imitation Learning (IL) allow policy search algorithms to make use of offline data, but require careful incorporation of uncertainty in order to circumvent the challenges of distribution shift. Gradient-based policy search methods are a promising direction due to their effectiveness in high dimensions; however, we require a more careful consideration of how these methods interplay with uncertainty estimation. We claim that in order for an uncertainty metric to be amenable for gradient-based optimization, it must be (i) stably convergent to data when uncertainty is minimized with gradients, and (ii) not prone to underestimation of true uncertainty. We investigate smoothed distance to data as a metric, and show that it not only stably converges to data, but also allows us to analyze model bias with Lipschitz constants. Moreover, we establish an equivalence between smoothed distance to data and data likelihood, which allows us to use score-matching techniques to learn gradients of distance to data. Importantly, we show that offline model-based policy search problems that maximize data likelihood do not require values of likelihood; but rather only the gradient of the log likelihood (the score function). Using this insight, we propose Score-Guided Planning (SGP), a planning algorithm for offline RL that utilizes score-matching to enable first-order planning in high-dimensional problems, where zeroth-order methods were unable to scale, and ensembles were unable to overcome local minima. Website: https://sites.google.com/view/score-guided-planning/home
Suboptimal Controller Synthesis for Cart-Poles and Quadrotors via Sums-of-Squares
Apr 25, 2023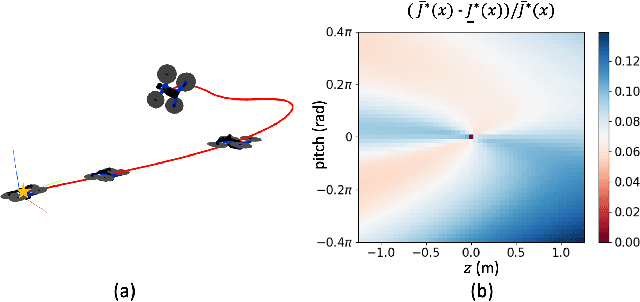
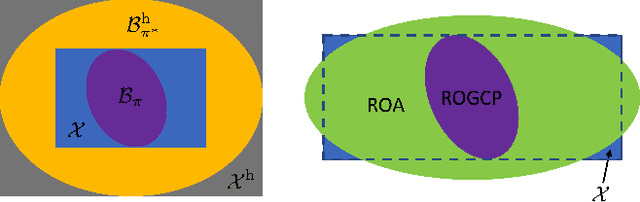
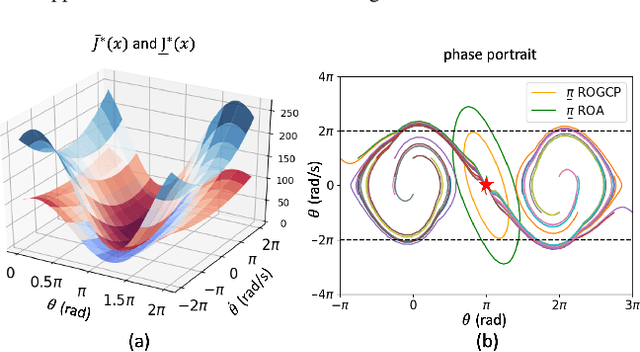
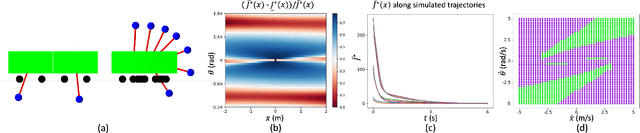
Sums-of-squares (SOS) optimization is a promising tool to synthesize certifiable controllers, but most examples to date have been limited to relatively simple systems. Here we demonstrate that SOS can synthesize controllers with bounded suboptimal performance for various underactuated robotic systems by finding good approximations of the value function. We summarize a unified SOS framework to synthesize both under- and over- approximations of the value function for continuous-time, control-affine systems, use these approximations to generate suboptimal controllers, and perform regional analysis on the closed-loop system driven by these controllers. We then extend the formulation to handle hybrid systems with contacts. We demonstrate that our method can generate tight under- and over- approximations of the value function with low-degree polynomials, which are used to provide stabilizing controllers for continuous-time systems including the inverted pendulum, the cart-pole, and the 3D quadrotor as well as a hybrid system, the planar pusher. To the best of our knowledge, this is the first time that a SOS-based time-invariant controller can swing up and stabilize a cart-pole, and push the planar slider to the desired pose.
Global Planning for Contact-Rich Manipulation via Local Smoothing of Quasi-dynamic Contact Models
Jun 22, 2022

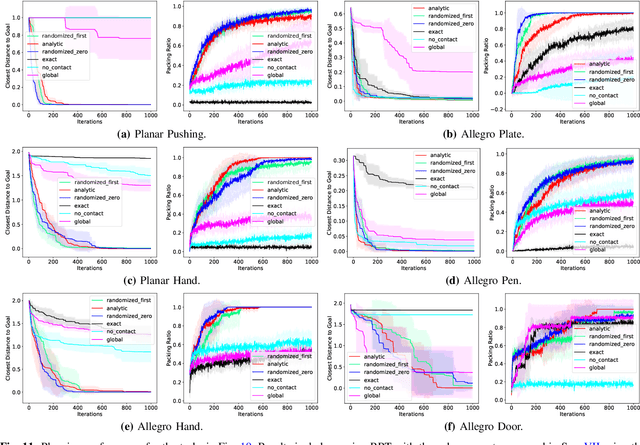
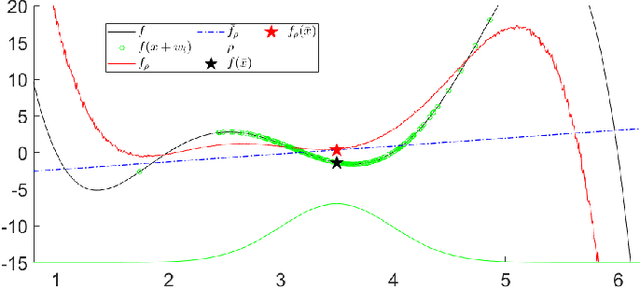
The empirical success of Reinforcement Learning (RL) in the setting of contact-rich manipulation leaves much to be understood from a model-based perspective, where the key difficulties are often attributed to (i) the explosion of contact modes, (ii) stiff, non-smooth contact dynamics and the resulting exploding / discontinuous gradients, and (iii) the non-convexity of the planning problem. The stochastic nature of RL addresses (i) and (ii) by effectively sampling and averaging the contact modes. On the other hand, model-based methods have tackled the same challenges by smoothing contact dynamics analytically. Our first contribution is to establish the theoretical equivalence of the two methods for simple systems, and provide qualitative and empirical equivalence on a number of complex examples. In order to further alleviate (ii), our second contribution is a convex, differentiable and quasi-dynamic formulation of contact dynamics, which is amenable to both smoothing schemes, and has proven through experiments to be highly effective for contact-rich planning. Our final contribution resolves (iii), where we show that classical sampling-based motion planning algorithms can be effective in global planning when contact modes are abstracted via smoothing. Applying our method on a collection of challenging contact-rich manipulation tasks, we demonstrate that efficient model-based motion planning can achieve results comparable to RL with dramatically less computation. Video: https://youtu.be/12Ew4xC-VwA
Lyapunov-stable neural-network control
Sep 29, 2021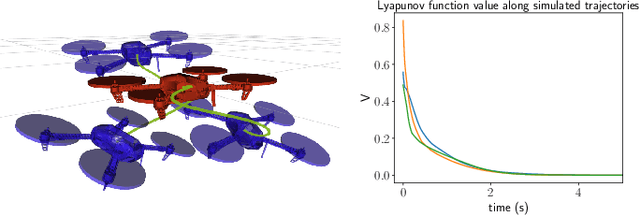


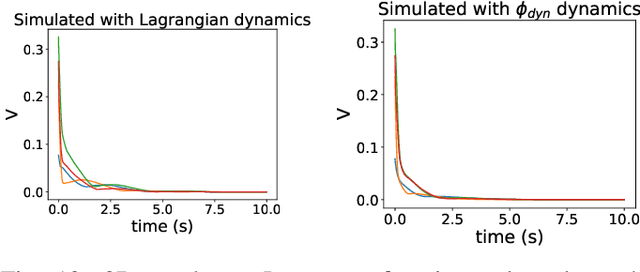
Deep learning has had a far reaching impact in robotics. Specifically, deep reinforcement learning algorithms have been highly effective in synthesizing neural-network controllers for a wide range of tasks. However, despite this empirical success, these controllers still lack theoretical guarantees on their performance, such as Lyapunov stability (i.e., all trajectories of the closed-loop system are guaranteed to converge to a goal state under the control policy). This is in stark contrast to traditional model-based controller design, where principled approaches (like LQR) can synthesize stable controllers with provable guarantees. To address this gap, we propose a generic method to synthesize a Lyapunov-stable neural-network controller, together with a neural-network Lyapunov function to simultaneously certify its stability. Our approach formulates the Lyapunov condition verification as a mixed-integer linear program (MIP). Our MIP verifier either certifies the Lyapunov condition, or generates counter examples that can help improve the candidate controller and the Lyapunov function. We also present an optimization program to compute an inner approximation of the region of attraction for the closed-loop system. We apply our approach to robots including an inverted pendulum, a 2D and a 3D quadrotor, and showcase that our neural-network controller outperforms a baseline LQR controller. The code is open sourced at \url{https://github.com/StanfordASL/neural-network-lyapunov}.