 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDexterous Contact-Rich Manipulation via the Contact Trust Region
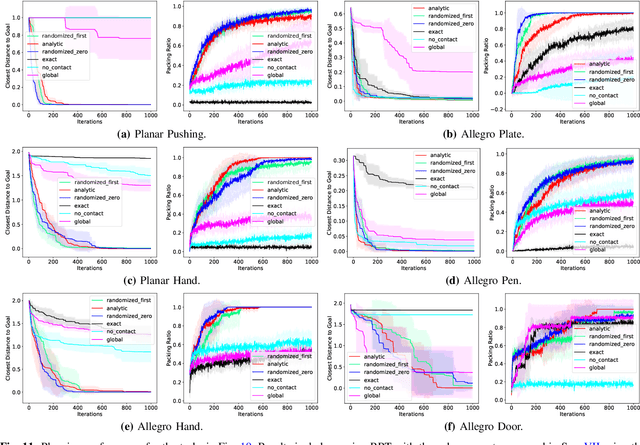
May 04, 2025What is a good local description of contact dynamics for contact-rich manipulation, and where can we trust this local description? While many approaches often rely on the Taylor approximation of dynamics with an ellipsoidal trust region, we argue that such approaches are fundamentally inconsistent with the unilateral nature of contact. As a remedy, we present the Contact Trust Region (CTR), which captures the unilateral nature of contact while remaining efficient for computation. With CTR, we first develop a Model-Predictive Control (MPC) algorithm capable of synthesizing local contact-rich plans. Then, we extend this capability to plan globally by stitching together local MPC plans, enabling efficient and dexterous contact-rich manipulation. To verify the performance of our method, we perform comprehensive evaluations, both in high-fidelity simulation and on hardware, on two contact-rich systems: a planar IiwaBimanual system and a 3D AllegroHand system. On both systems, our method offers a significantly lower-compute alternative to existing RL-based approaches to contact-rich manipulation. In particular, our Allegro in-hand manipulation policy, in the form of a roadmap, takes fewer than 10 minutes to build offline on a standard laptop using just its CPU, with online inference taking just a few seconds. Experiment data, video and code are available at ctr.theaiinstitute.com.
Physics-Driven Data Generation for Contact-Rich Manipulation via Trajectory Optimization
Feb 27, 2025



We present a low-cost data generation pipeline that integrates physics-based simulation, human demonstrations, and model-based planning to efficiently generate large-scale, high-quality datasets for contact-rich robotic manipulation tasks. Starting with a small number of embodiment-flexible human demonstrations collected in a virtual reality simulation environment, the pipeline refines these demonstrations using optimization-based kinematic retargeting and trajectory optimization to adapt them across various robot embodiments and physical parameters. This process yields a diverse, physically consistent dataset that enables cross-embodiment data transfer, and offers the potential to reuse legacy datasets collected under different hardware configurations or physical parameters. We validate the pipeline's effectiveness by training diffusion policies from the generated datasets for challenging contact-rich manipulation tasks across multiple robot embodiments, including a floating Allegro hand and bimanual robot arms. The trained policies are deployed zero-shot on hardware for bimanual iiwa arms, achieving high success rates with minimal human input. Project website: https://lujieyang.github.io/physicsgen/.
Is Linear Feedback on Smoothed Dynamics Sufficient for Stabilizing Contact-Rich Plans?
Nov 14, 2024



Designing planners and controllers for contact-rich manipulation is extremely challenging as contact violates the smoothness conditions that many gradient-based controller synthesis tools assume. Contact smoothing approximates a non-smooth system with a smooth one, allowing one to use these synthesis tools more effectively. However, applying classical control synthesis methods to smoothed contact dynamics remains relatively under-explored. This paper analyzes the efficacy of linear controller synthesis using differential simulators based on contact smoothing. We introduce natural baselines for leveraging contact smoothing to compute (a) open-loop plans robust to uncertain conditions and/or dynamics, and (b) feedback gains to stabilize around open-loop plans. Using robotic bimanual whole-body manipulation as a testbed, we perform extensive empirical experiments on over 300 trajectories and analyze why LQR seems insufficient for stabilizing contact-rich plans. The video summarizing this paper and hardware experiments is found here: https://youtu.be/HLaKi6qbwQg?si=_zCAmBBD6rGSitm9.
Fighting Uncertainty with Gradients: Offline Reinforcement Learning via Diffusion Score Matching
Jun 24, 2023



Offline optimization paradigms such as offline Reinforcement Learning (RL) or Imitation Learning (IL) allow policy search algorithms to make use of offline data, but require careful incorporation of uncertainty in order to circumvent the challenges of distribution shift. Gradient-based policy search methods are a promising direction due to their effectiveness in high dimensions; however, we require a more careful consideration of how these methods interplay with uncertainty estimation. We claim that in order for an uncertainty metric to be amenable for gradient-based optimization, it must be (i) stably convergent to data when uncertainty is minimized with gradients, and (ii) not prone to underestimation of true uncertainty. We investigate smoothed distance to data as a metric, and show that it not only stably converges to data, but also allows us to analyze model bias with Lipschitz constants. Moreover, we establish an equivalence between smoothed distance to data and data likelihood, which allows us to use score-matching techniques to learn gradients of distance to data. Importantly, we show that offline model-based policy search problems that maximize data likelihood do not require values of likelihood; but rather only the gradient of the log likelihood (the score function). Using this insight, we propose Score-Guided Planning (SGP), a planning algorithm for offline RL that utilizes score-matching to enable first-order planning in high-dimensional problems, where zeroth-order methods were unable to scale, and ensembles were unable to overcome local minima. Website: https://sites.google.com/view/score-guided-planning/home
Global Planning for Contact-Rich Manipulation via Local Smoothing of Quasi-dynamic Contact Models
Jun 22, 2022

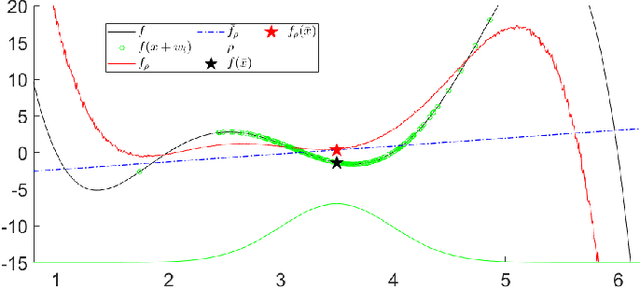
The empirical success of Reinforcement Learning (RL) in the setting of contact-rich manipulation leaves much to be understood from a model-based perspective, where the key difficulties are often attributed to (i) the explosion of contact modes, (ii) stiff, non-smooth contact dynamics and the resulting exploding / discontinuous gradients, and (iii) the non-convexity of the planning problem. The stochastic nature of RL addresses (i) and (ii) by effectively sampling and averaging the contact modes. On the other hand, model-based methods have tackled the same challenges by smoothing contact dynamics analytically. Our first contribution is to establish the theoretical equivalence of the two methods for simple systems, and provide qualitative and empirical equivalence on a number of complex examples. In order to further alleviate (ii), our second contribution is a convex, differentiable and quasi-dynamic formulation of contact dynamics, which is amenable to both smoothing schemes, and has proven through experiments to be highly effective for contact-rich planning. Our final contribution resolves (iii), where we show that classical sampling-based motion planning algorithms can be effective in global planning when contact modes are abstracted via smoothing. Applying our method on a collection of challenging contact-rich manipulation tasks, we demonstrate that efficient model-based motion planning can achieve results comparable to RL with dramatically less computation. Video: https://youtu.be/12Ew4xC-VwA
Do Differentiable Simulators Give Better Policy Gradients?
Feb 02, 2022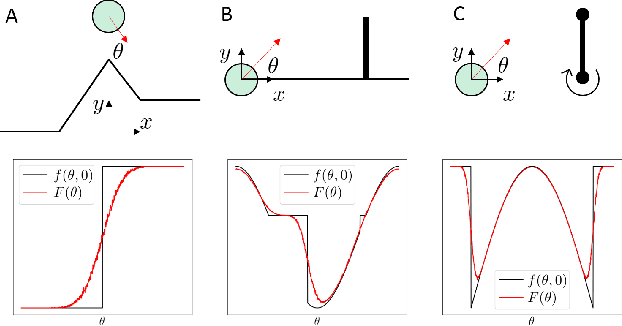
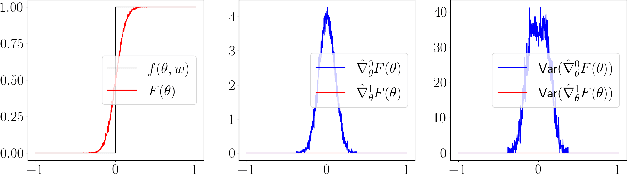
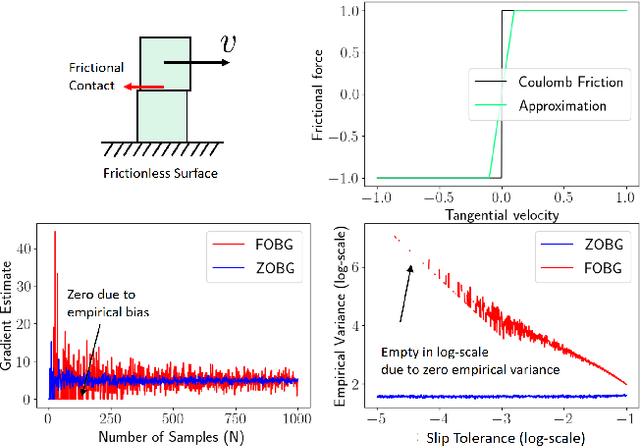
Differentiable simulators promise faster computation time for reinforcement learning by replacing zeroth-order gradient estimates of a stochastic objective with an estimate based on first-order gradients. However, it is yet unclear what factors decide the performance of the two estimators on complex landscapes that involve long-horizon planning and control on physical systems, despite the crucial relevance of this question for the utility of differentiable simulators. We show that characteristics of certain physical systems, such as stiffness or discontinuities, may compromise the efficacy of the first-order estimator, and analyze this phenomenon through the lens of bias and variance. We additionally propose an $\alpha$-order gradient estimator, with $\alpha \in [0,1]$, which correctly utilizes exact gradients to combine the efficiency of first-order estimates with the robustness of zero-order methods. We demonstrate the pitfalls of traditional estimators and the advantages of the $\alpha$-order estimator on some numerical examples.
SEED: Series Elastic End Effectors in 6D for Visuotactile Tool Use
Nov 02, 2021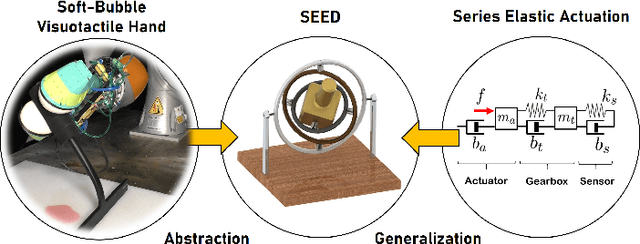
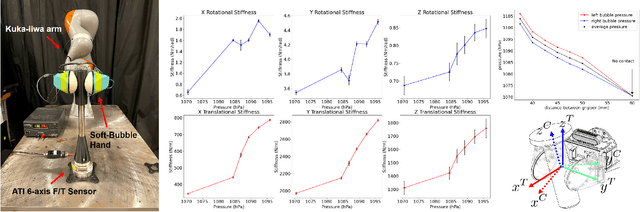
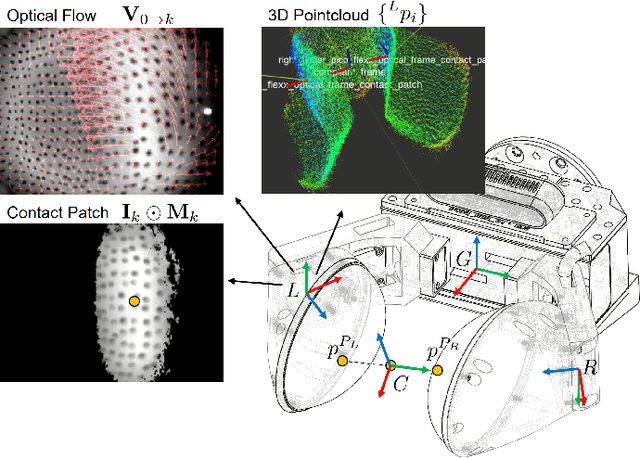
We propose the framework of Series Elastic End Effectors in 6D (SEED), which combines a spatially compliant element with visuotactile sensing to grasp and manipulate tools in the wild. Our framework generalizes the benefits of series elasticity to 6-dof, while providing an abstraction of control using visuotactile sensing. We propose an algorithm for relative pose estimation from visuotactile sensing, and a spatial hybrid force-position controller capable of achieving stable force interaction with the environment. We demonstrate the effectiveness of our framework on tools that require regulation of spatial forces. Video link: https://youtu.be/2-YuIfspDrk
Bundled Gradients through Contact via Randomized Smoothing
Sep 14, 2021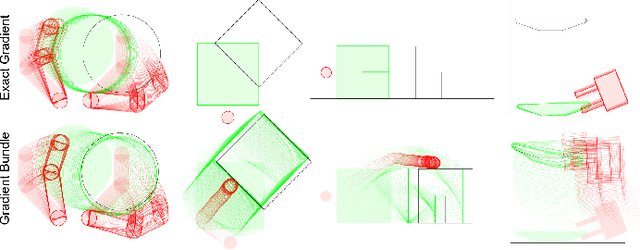

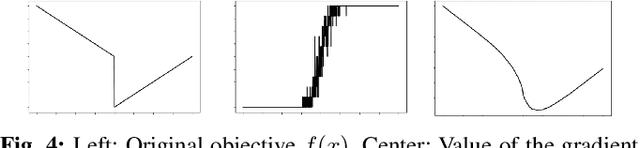

The empirical success of derivative-free methods in reinforcement learning for planning through contact seems at odds with the perceived fragility of classical gradient-based optimization methods in these domains. What is causing this gap, and how might we use the answer to improve gradient-based methods? We believe a stochastic formulation of dynamics is one crucial ingredient. We use tools from randomized smoothing to analyze sampling-based approximations of the gradient, and formalize such approximations through the gradient bundle. We show that using the gradient bundle in lieu of the gradient mitigates fast-changing gradients of non-smooth contact dynamics modeled by the implicit time-stepping, or the penalty method. Finally, we apply the gradient bundle to optimal control using iLQR, introducing a novel algorithm which improves convergence over using exact gradients. Combining our algorithm with a convex implicit time-stepping formulation of contact, we show that we can tractably tackle planning-through-contact problems in manipulation.
The Surprising Effectiveness of Linear Models for Visual Foresight in Object Pile Manipulation
Feb 21, 2020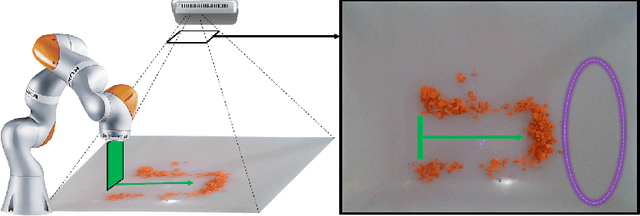


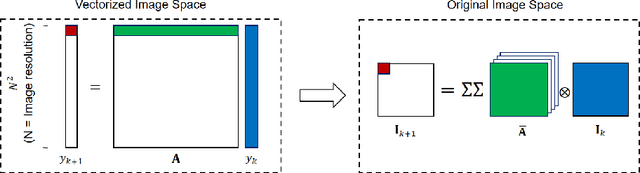
In this paper, we tackle the problem of pushing piles of small objects into a desired target set using visual feedback. Unlike conventional single-object manipulation pipelines, which estimate the state of the system parametrized by pose, the underlying physical state of this system is difficult to observe from images. Thus, we take the approach of reasoning directly in the space of images, and acquire the dynamics of visual measurements in order to synthesize a visual-feedback policy. We present a simple controller using an image-space Lyapunov function, and evaluate the closed-loop performance using three different class of models for image prediction: deep-learning-based models for image-to-image translation, an object-centric model obtained from treating each pixel as a particle, and a switched-linear system where an action-dependent linear map is used. Through results in simulation and experiment, we show that for this task, a linear model works surprisingly well -- achieving better prediction error, downstream task performance, and generalization to new environments than the deep models we trained on the same amount of data. We believe these results provide an interesting example in the spectrum of models that are most useful for vision-based feedback in manipulation, considering both the quality of visual prediction, as well as compatibility with rigorous methods for control design and analysis.
Optimal Motion Planning for Multi-Modal Hybrid Locomotion
Sep 23, 2019


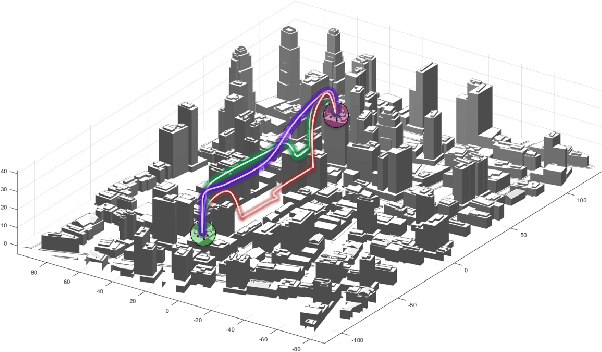
Hybrid locomotion, which combines multiple modalities of locomotion within a single robot, can enable robots to carry out complex tasks in diverse environments. This paper presents a novel method of combining graph search and trajectory optimization for planning multi-modal locomotion trajectories. We also introduce methods that allow the method to work tractably in higher dimensional state spaces. Through the examples of a hybrid double-integrator, amphibious robot, and the flying-driving drone, we show that our planner tractably gives full-state trajectories that are probabilistically optimal and dynamically feasible.