 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBundled Gradients through Contact via Randomized Smoothing
Paper and Code
Sep 14, 2021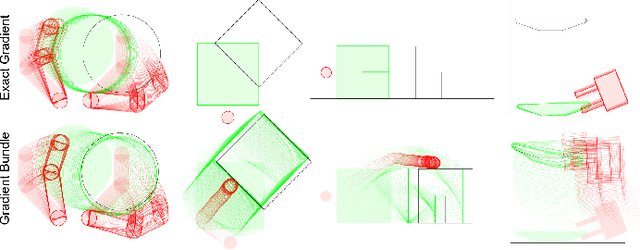

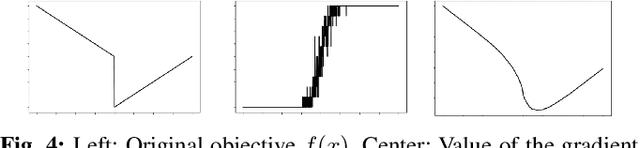

The empirical success of derivative-free methods in reinforcement learning for planning through contact seems at odds with the perceived fragility of classical gradient-based optimization methods in these domains. What is causing this gap, and how might we use the answer to improve gradient-based methods? We believe a stochastic formulation of dynamics is one crucial ingredient. We use tools from randomized smoothing to analyze sampling-based approximations of the gradient, and formalize such approximations through the gradient bundle. We show that using the gradient bundle in lieu of the gradient mitigates fast-changing gradients of non-smooth contact dynamics modeled by the implicit time-stepping, or the penalty method. Finally, we apply the gradient bundle to optimal control using iLQR, introducing a novel algorithm which improves convergence over using exact gradients. Combining our algorithm with a convex implicit time-stepping formulation of contact, we show that we can tractably tackle planning-through-contact problems in manipulation.