 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Data-Driven Reachability Analysis and Control via Koopman Operators with Conformal Coverage Guarantees
Jan 03, 2026We propose a scalable reachability-based framework for probabilistic, data-driven safety verification of unknown nonlinear dynamics. We use Koopman theory with a neural network (NN) lifting function to learn an approximate linear representation of the dynamics and design linear controllers in this space to enable closed-loop tracking of a reference trajectory distribution. Closed-loop reachable sets are efficiently computed in the lifted space and mapped back to the original state space via NN verification tools. To capture model mismatch between the Koopman dynamics and the true system, we apply conformal prediction to produce statistically-valid error bounds that inflate the reachable sets to ensure the true trajectories are contained with a user-specified probability. These bounds generalize across references, enabling reuse without recomputation. Results on high-dimensional MuJoCo tasks (11D Hopper, 28D Swimmer) and 12D quadcopters show improved reachable set coverage rate, computational efficiency, and conservativeness over existing methods.
Active Constraint Learning in High Dimensions from Demonstrations
Dec 28, 2025We present an iterative active constraint learning (ACL) algorithm, within the learning from demonstrations (LfD) paradigm, which intelligently solicits informative demonstration trajectories for inferring an unknown constraint in the demonstrator's environment. Our approach iteratively trains a Gaussian process (GP) on the available demonstration dataset to represent the unknown constraints, uses the resulting GP posterior to query start/goal states, and generates informative demonstrations which are added to the dataset. Across simulation and hardware experiments using high-dimensional nonlinear dynamics and unknown nonlinear constraints, our method outperforms a baseline, random-sampling based method at accurately performing constraint inference from an iteratively generated set of sparse but informative demonstrations.
Probabilistically-Safe Bipedal Navigation over Uncertain Terrain via Conformal Prediction and Contraction Analysis
Oct 09, 2025We address the challenge of enabling bipedal robots to traverse rough terrain by developing probabilistically safe planning and control strategies that ensure dynamic feasibility and centroidal robustness under terrain uncertainty. Specifically, we propose a high-level Model Predictive Control (MPC) navigation framework for a bipedal robot with a specified confidence level of safety that (i) enables safe traversal toward a desired goal location across a terrain map with uncertain elevations, and (ii) formally incorporates uncertainty bounds into the centroidal dynamics of locomotion control. To model the rough terrain, we employ Gaussian Process (GP) regression to estimate elevation maps and leverage Conformal Prediction (CP) to construct calibrated confidence intervals that capture the true terrain elevation. Building on this, we formulate contraction-based reachable tubes that explicitly account for terrain uncertainty, ensuring state convergence and tube invariance. In addition, we introduce a contraction-based flywheel torque control law for the reduced-order Linear Inverted Pendulum Model (LIPM), which stabilizes the angular momentum about the center-of-mass (CoM). This formulation provides both probabilistic safety and goal reachability guarantees. For a given confidence level, we establish the forward invariance of the proposed torque control law by demonstrating exponential stabilization of the actual CoM phase-space trajectory and the desired trajectory prescribed by the high-level planner. Finally, we evaluate the effectiveness of our planning framework through physics-based simulations of the Digit bipedal robot in MuJoCo.
NavMoE: Hybrid Model- and Learning-based Traversability Estimation for Local Navigation via Mixture of Experts
Sep 16, 2025This paper explores traversability estimation for robot navigation. A key bottleneck in traversability estimation lies in efficiently achieving reliable and robust predictions while accurately encoding both geometric and semantic information across diverse environments. We introduce Navigation via Mixture of Experts (NAVMOE), a hierarchical and modular approach for traversability estimation and local navigation. NAVMOE combines multiple specialized models for specific terrain types, each of which can be either a classical model-based or a learning-based approach that predicts traversability for specific terrain types. NAVMOE dynamically weights the contributions of different models based on the input environment through a gating network. Overall, our approach offers three advantages: First, NAVMOE enables traversability estimation to adaptively leverage specialized approaches for different terrains, which enhances generalization across diverse and unseen environments. Second, our approach significantly improves efficiency with negligible cost of solution quality by introducing a training-free lazy gating mechanism, which is designed to minimize the number of activated experts during inference. Third, our approach uses a two-stage training strategy that enables the training for the gating networks within the hybrid MoE method that contains nondifferentiable modules. Extensive experiments show that NAVMOE delivers a better efficiency and performance balance than any individual expert or full ensemble across different domains, improving cross- domain generalization and reducing average computational cost by 81.2% via lazy gating, with less than a 2% loss in path quality.
Constraint Learning in Multi-Agent Dynamic Games from Demonstrations of Local Nash Interactions
Aug 28, 2025We present an inverse dynamic game-based algorithm to learn parametric constraints from a given dataset of local generalized Nash equilibrium interactions between multiple agents. Specifically, we introduce mixed-integer linear programs (MILP) encoding the Karush-Kuhn-Tucker (KKT) conditions of the interacting agents, which recover constraints consistent with the Nash stationarity of the interaction demonstrations. We establish theoretical guarantees that our method learns inner approximations of the true safe and unsafe sets, as well as limitations of constraint learnability from demonstrations of Nash equilibrium interactions. We also use the interaction constraints recovered by our method to design motion plans that robustly satisfy the underlying constraints. Across simulations and hardware experiments, our methods proved capable of inferring constraints and designing interactive motion plans for various classes of constraints, both convex and non-convex, from interaction demonstrations of agents with nonlinear dynamics.
Polar Hierarchical Mamba: Towards Streaming LiDAR Object Detection with Point Clouds as Egocentric Sequences
Jun 07, 2025Accurate and efficient object detection is essential for autonomous vehicles, where real-time perception requires low latency and high throughput. LiDAR sensors provide robust depth information, but conventional methods process full 360{\deg} scans in a single pass, introducing significant delay. Streaming approaches address this by sequentially processing partial scans in the native polar coordinate system, yet they rely on translation-invariant convolutions that are misaligned with polar geometry -- resulting in degraded performance or requiring complex distortion mitigation. Recent Mamba-based state space models (SSMs) have shown promise for LiDAR perception, but only in the full-scan setting, relying on geometric serialization and positional embeddings that are memory-intensive and ill-suited to streaming. We propose Polar Hierarchical Mamba (PHiM), a novel SSM architecture designed for polar-coordinate streaming LiDAR. PHiM uses local bidirectional Mamba blocks for intra-sector spatial encoding and a global forward Mamba for inter-sector temporal modeling, replacing convolutions and positional encodings with distortion-aware, dimensionally-decomposed operations. PHiM sets a new state-of-the-art among streaming detectors on the Waymo Open Dataset, outperforming the previous best by 10\% and matching full-scan baselines at twice the throughput. Code will be available at https://github.com/meilongzhang/Polar-Hierarchical-Mamba .
Improving Out-of-Distribution Generalization of Learned Dynamics by Learning Pseudometrics and Constraint Manifolds
Mar 20, 2024We propose a method for improving the prediction accuracy of learned robot dynamics models on out-of-distribution (OOD) states. We achieve this by leveraging two key sources of structure often present in robot dynamics: 1) sparsity, i.e., some components of the state may not affect the dynamics, and 2) physical limits on the set of possible motions, in the form of nonholonomic constraints. Crucially, we do not assume this structure is known a priori, and instead learn it from data. We use contrastive learning to obtain a distance pseudometric that uncovers the sparsity pattern in the dynamics, and use it to reduce the input space when learning the dynamics. We then learn the unknown constraint manifold by approximating the normal space of possible motions from the data, which we use to train a Gaussian process (GP) representation of the constraint manifold. We evaluate our approach on a physical differential-drive robot and a simulated quadrotor, showing improved prediction accuracy on OOD data relative to baselines.
Fighting Uncertainty with Gradients: Offline Reinforcement Learning via Diffusion Score Matching
Jun 24, 2023



Offline optimization paradigms such as offline Reinforcement Learning (RL) or Imitation Learning (IL) allow policy search algorithms to make use of offline data, but require careful incorporation of uncertainty in order to circumvent the challenges of distribution shift. Gradient-based policy search methods are a promising direction due to their effectiveness in high dimensions; however, we require a more careful consideration of how these methods interplay with uncertainty estimation. We claim that in order for an uncertainty metric to be amenable for gradient-based optimization, it must be (i) stably convergent to data when uncertainty is minimized with gradients, and (ii) not prone to underestimation of true uncertainty. We investigate smoothed distance to data as a metric, and show that it not only stably converges to data, but also allows us to analyze model bias with Lipschitz constants. Moreover, we establish an equivalence between smoothed distance to data and data likelihood, which allows us to use score-matching techniques to learn gradients of distance to data. Importantly, we show that offline model-based policy search problems that maximize data likelihood do not require values of likelihood; but rather only the gradient of the log likelihood (the score function). Using this insight, we propose Score-Guided Planning (SGP), a planning algorithm for offline RL that utilizes score-matching to enable first-order planning in high-dimensional problems, where zeroth-order methods were unable to scale, and ensembles were unable to overcome local minima. Website: https://sites.google.com/view/score-guided-planning/home
Synthesizing Stable Reduced-Order Visuomotor Policies for Nonlinear Systems via Sums-of-Squares Optimization
Apr 24, 2023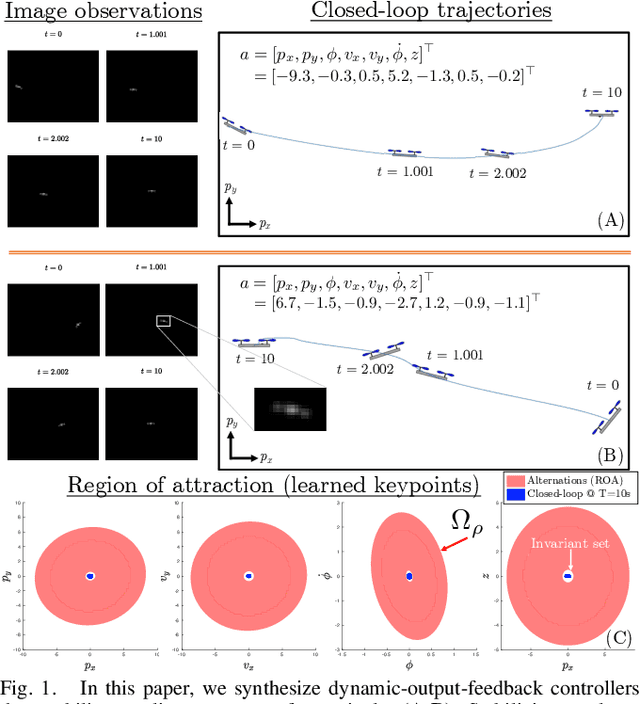



We present a method for synthesizing dynamic, reduced-order output-feedback polynomial control policies for control-affine nonlinear systems which guarantees runtime stability to a goal state, when using visual observations and a learned perception module in the feedback control loop. We leverage Lyapunov analysis to formulate the problem of synthesizing such policies. This problem is nonconvex in the policy parameters and the Lyapunov function that is used to prove the stability of the policy. To solve this problem approximately, we propose two approaches: the first solves a sequence of sum-of-squares optimization problems to iteratively improve a policy which is provably-stable by construction, while the second directly performs gradient-based optimization on the parameters of the polynomial policy, and its closed-loop stability is verified a posteriori. We extend our approach to provide stability guarantees in the presence of observation noise, which realistically arises due to errors in the learned perception module. We evaluate our approach on several underactuated nonlinear systems, including pendula and quadrotors, showing that our guarantees translate to empirical stability when controlling these systems from images, while baseline approaches can fail to reliably stabilize the system.
Data-Efficient Learning of Natural Language to Linear Temporal Logic Translators for Robot Task Specification
Mar 21, 2023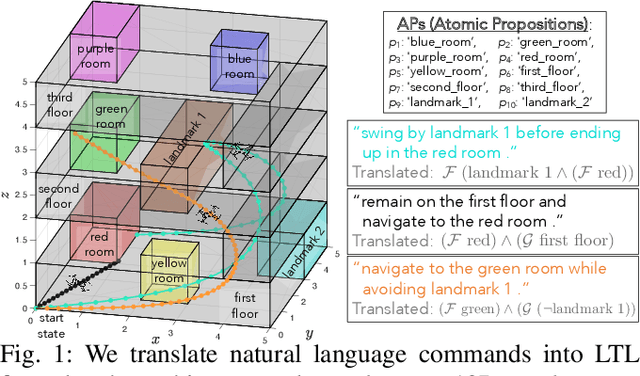
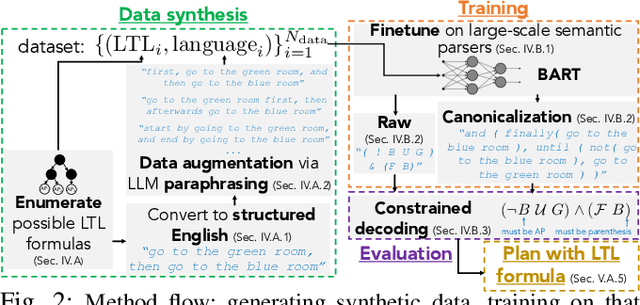
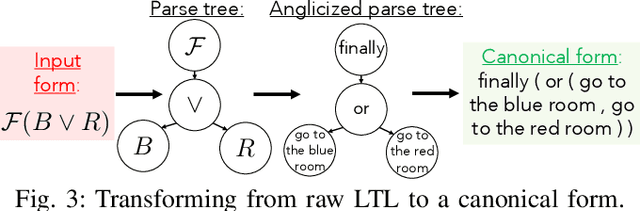

To make robots accessible to a broad audience, it is critical to endow them with the ability to take universal modes of communication, like commands given in natural language, and extract a concrete desired task specification, defined using a formal language like linear temporal logic (LTL). In this paper, we present a learning-based approach for translating from natural language commands to LTL specifications with very limited human-labeled training data. This is in stark contrast to existing natural-language to LTL translators, which require large human-labeled datasets, often in the form of labeled pairs of LTL formulas and natural language commands, to train the translator. To reduce reliance on human data, our approach generates a large synthetic training dataset through algorithmic generation of LTL formulas, conversion to structured English, and then exploiting the paraphrasing capabilities of modern large language models (LLMs) to synthesize a diverse corpus of natural language commands corresponding to the LTL formulas. We use this generated data to finetune an LLM and apply a constrained decoding procedure at inference time to ensure the returned LTL formula is syntactically correct. We evaluate our approach on three existing LTL/natural language datasets and show that we can translate natural language commands at 75\% accuracy with far less human data ($\le$12 annotations). Moreover, when training on large human-annotated datasets, our method achieves higher test accuracy (95\% on average) than prior work. Finally, we show the translated formulas can be used to plan long-horizon, multi-stage tasks on a 12D quadrotor.