 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIRE-Prune: Asymptotic Impulse-Response Energy for State Pruning in State Space Models
Jan 31, 2026State space models (SSMs) often sacrifice capacity, search space, or stability to offset the memory and compute costs of large state dimensions. We introduce a structured post-training pruning method for SSMs -- AIRE-Prune (Asymptotic Impulse-Response Energy for State PRUN(E)) -- that reduces each layer's state dimension by directly minimizing long-run output-energy distortion. AIRE-Prune assigns every state a closed-form asymptotic impulse-response energy-based score, i.e., the total impulse-response energy it contributes over an infinite horizon (time), and normalizes these scores layer-wise to enable global cross-layer comparison and selection. This extends modal truncation from single systems to deep stacks and aligns pruning with asymptotic response energy rather than worst-case gain. Across diverse sequence benchmarks, AIRE-Prune reveals substantial redundancy in SISO and MIMO SSMs with average pruning of 60.8%, with average accuracy drop of 0.29% without retraining, while significantly lowering compute. Code: https://github.com/falcon-arrow/AIRE-Prune.
SSMRadNet : A Sample-wise State-Space Framework for Efficient and Ultra-Light Radar Segmentation and Object Detection
Nov 11, 2025



We introduce SSMRadNet, the first multi-scale State Space Model (SSM) based detector for Frequency Modulated Continuous Wave (FMCW) radar that sequentially processes raw ADC samples through two SSMs. One SSM learns a chirp-wise feature by sequentially processing samples from all receiver channels within one chirp, and a second SSM learns a representation of a frame by sequentially processing chirp-wise features. The latent representations of a radar frame are decoded to perform segmentation and detection tasks. Comprehensive evaluations on the RADIal dataset show SSMRadNet has 10-33x fewer parameters and 60-88x less computation (GFLOPs) while being 3.7x faster than state-of-the-art transformer and convolution-based radar detectors at competitive performance for segmentation tasks.
Polar Hierarchical Mamba: Towards Streaming LiDAR Object Detection with Point Clouds as Egocentric Sequences
Jun 07, 2025Accurate and efficient object detection is essential for autonomous vehicles, where real-time perception requires low latency and high throughput. LiDAR sensors provide robust depth information, but conventional methods process full 360{\deg} scans in a single pass, introducing significant delay. Streaming approaches address this by sequentially processing partial scans in the native polar coordinate system, yet they rely on translation-invariant convolutions that are misaligned with polar geometry -- resulting in degraded performance or requiring complex distortion mitigation. Recent Mamba-based state space models (SSMs) have shown promise for LiDAR perception, but only in the full-scan setting, relying on geometric serialization and positional embeddings that are memory-intensive and ill-suited to streaming. We propose Polar Hierarchical Mamba (PHiM), a novel SSM architecture designed for polar-coordinate streaming LiDAR. PHiM uses local bidirectional Mamba blocks for intra-sector spatial encoding and a global forward Mamba for inter-sector temporal modeling, replacing convolutions and positional encodings with distortion-aware, dimensionally-decomposed operations. PHiM sets a new state-of-the-art among streaming detectors on the Waymo Open Dataset, outperforming the previous best by 10\% and matching full-scan baselines at twice the throughput. Code will be available at https://github.com/meilongzhang/Polar-Hierarchical-Mamba .
FLAMES: A Hybrid Spiking-State Space Model for Adaptive Memory Retention in Event-Based Learning
Apr 02, 2025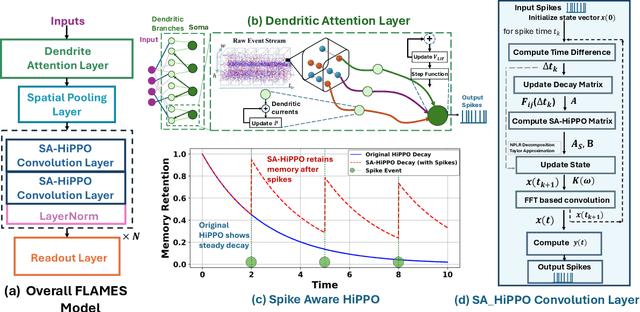
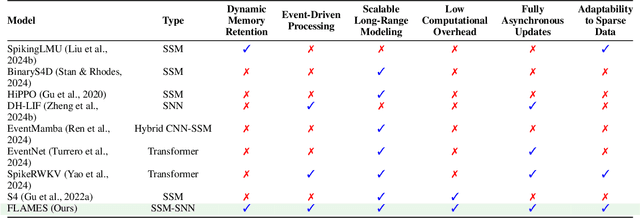
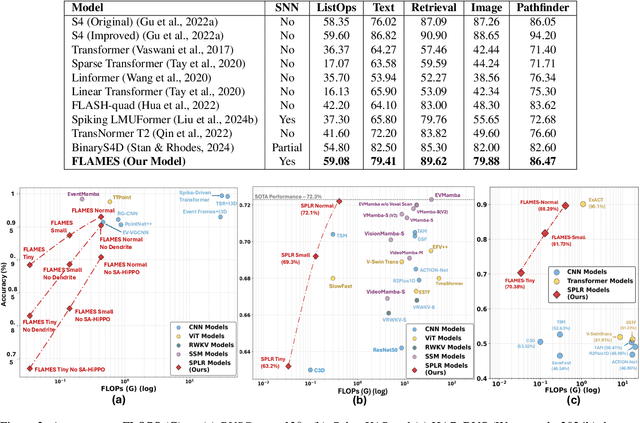
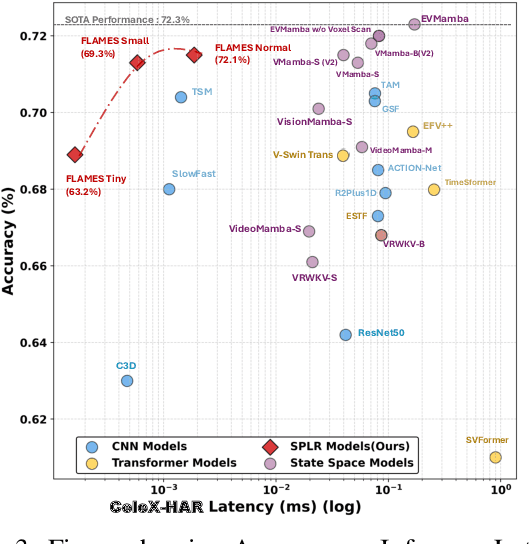
We propose \textbf{FLAMES (Fast Long-range Adaptive Memory for Event-based Systems)}, a novel hybrid framework integrating structured state-space dynamics with event-driven computation. At its core, the \textit{Spike-Aware HiPPO (SA-HiPPO) mechanism} dynamically adjusts memory retention based on inter-spike intervals, preserving both short- and long-range dependencies. To maintain computational efficiency, we introduce a normal-plus-low-rank (NPLR) decomposition, reducing complexity from $\mathcal{O}(N^2)$ to $\mathcal{O}(Nr)$. FLAMES achieves state-of-the-art results on the Long Range Arena benchmark and event datasets like HAR-DVS and Celex-HAR. By bridging neuromorphic computing and structured sequence modeling, FLAMES enables scalable long-range reasoning in event-driven systems.
Dynamic Graph Structure Estimation for Learning Multivariate Point Process using Spiking Neural Networks
Apr 01, 2025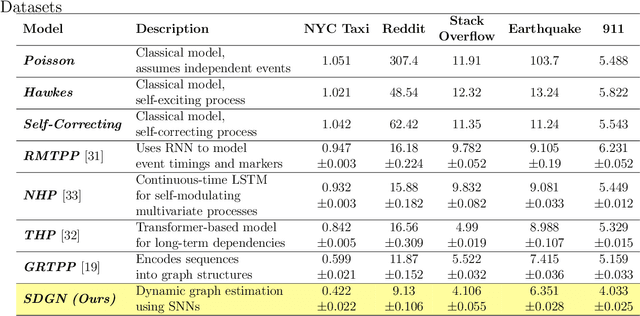
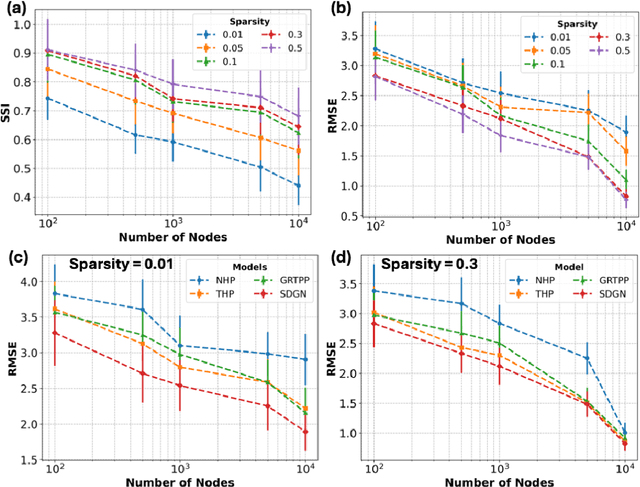
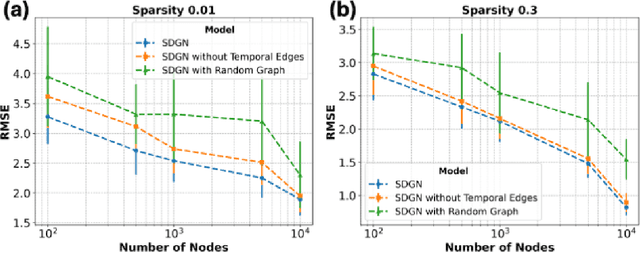
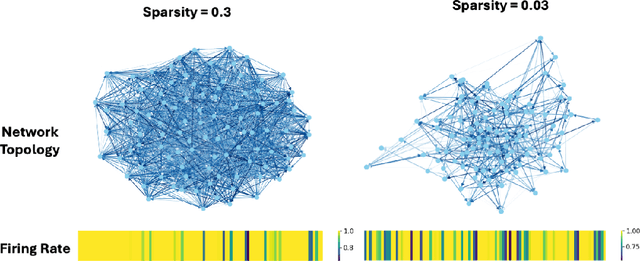
Modeling and predicting temporal point processes (TPPs) is critical in domains such as neuroscience, epidemiology, finance, and social sciences. We introduce the Spiking Dynamic Graph Network (SDGN), a novel framework that leverages the temporal processing capabilities of spiking neural networks (SNNs) and spike-timing-dependent plasticity (STDP) to dynamically estimate underlying spatio-temporal functional graphs. Unlike existing methods that rely on predefined or static graph structures, SDGN adapts to any dataset by learning dynamic spatio-temporal dependencies directly from the event data, enhancing generalizability and robustness. While SDGN offers significant improvements over prior methods, we acknowledge its limitations in handling dense graphs and certain non-Gaussian dependencies, providing opportunities for future refinement. Our evaluations, conducted on both synthetic and real-world datasets including NYC Taxi, 911, Reddit, and Stack Overflow, demonstrate that SDGN achieves superior predictive accuracy while maintaining computational efficiency. Furthermore, we include ablation studies to highlight the contributions of its core components.
Intelligent Sensing-to-Action for Robust Autonomy at the Edge: Opportunities and Challenges
Feb 04, 2025Autonomous edge computing in robotics, smart cities, and autonomous vehicles relies on the seamless integration of sensing, processing, and actuation for real-time decision-making in dynamic environments. At its core is the sensing-to-action loop, which iteratively aligns sensor inputs with computational models to drive adaptive control strategies. These loops can adapt to hyper-local conditions, enhancing resource efficiency and responsiveness, but also face challenges such as resource constraints, synchronization delays in multi-modal data fusion, and the risk of cascading errors in feedback loops. This article explores how proactive, context-aware sensing-to-action and action-to-sensing adaptations can enhance efficiency by dynamically adjusting sensing and computation based on task demands, such as sensing a very limited part of the environment and predicting the rest. By guiding sensing through control actions, action-to-sensing pathways can improve task relevance and resource use, but they also require robust monitoring to prevent cascading errors and maintain reliability. Multi-agent sensing-action loops further extend these capabilities through coordinated sensing and actions across distributed agents, optimizing resource use via collaboration. Additionally, neuromorphic computing, inspired by biological systems, provides an efficient framework for spike-based, event-driven processing that conserves energy, reduces latency, and supports hierarchical control--making it ideal for multi-agent optimization. This article highlights the importance of end-to-end co-design strategies that align algorithmic models with hardware and environmental dynamics and improve cross-layer interdependencies to improve throughput, precision, and adaptability for energy-efficient edge autonomy in complex environments.
AdaCred: Adaptive Causal Decision Transformers with Feature Crediting
Dec 19, 2024



Reinforcement learning (RL) can be formulated as a sequence modeling problem, where models predict future actions based on historical state-action-reward sequences. Current approaches typically require long trajectory sequences to model the environment in offline RL settings. However, these models tend to over-rely on memorizing long-term representations, which impairs their ability to effectively attribute importance to trajectories and learned representations based on task-specific relevance. In this work, we introduce AdaCred, a novel approach that represents trajectories as causal graphs built from short-term action-reward-state sequences. Our model adaptively learns control policy by crediting and pruning low-importance representations, retaining only those most relevant for the downstream task. Our experiments demonstrate that AdaCred-based policies require shorter trajectory sequences and consistently outperform conventional methods in both offline reinforcement learning and imitation learning environments.
A Dynamical Systems-Inspired Pruning Strategy for Addressing Oversmoothing in Graph Neural Networks
Dec 10, 2024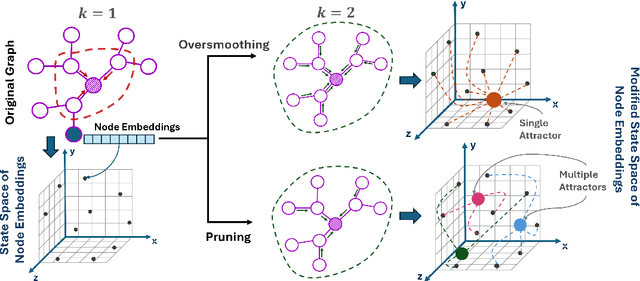
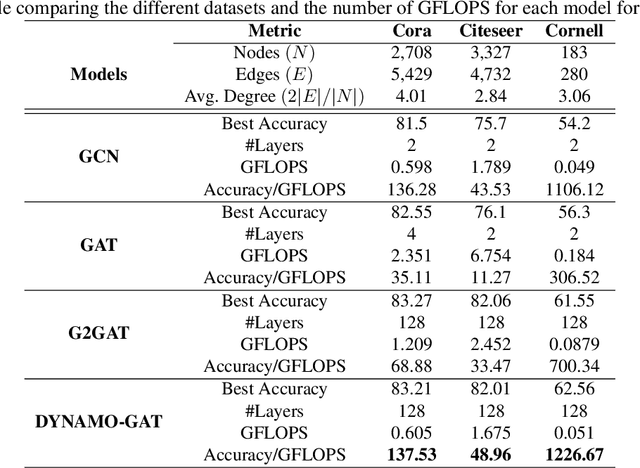
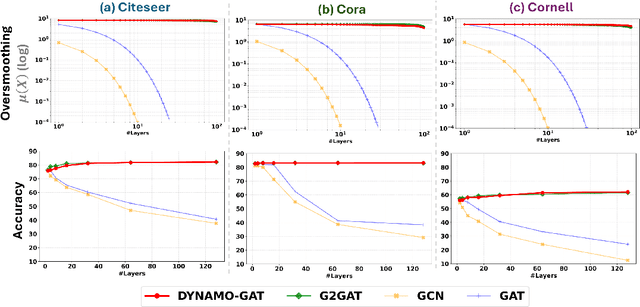
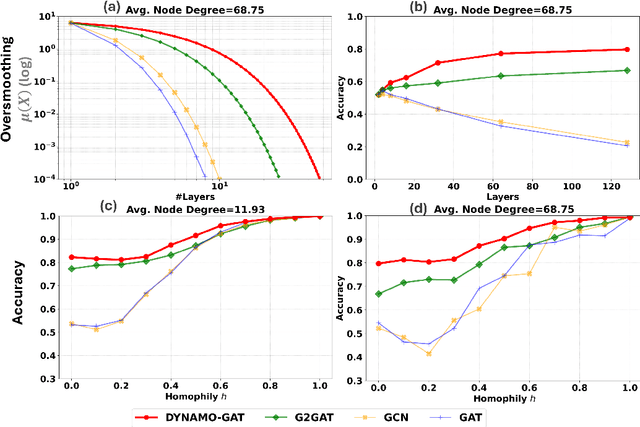
Oversmoothing in Graph Neural Networks (GNNs) poses a significant challenge as network depth increases, leading to homogenized node representations and a loss of expressiveness. In this work, we approach the oversmoothing problem from a dynamical systems perspective, providing a deeper understanding of the stability and convergence behavior of GNNs. Leveraging insights from dynamical systems theory, we identify the root causes of oversmoothing and propose \textbf{\textit{DYNAMO-GAT}}. This approach utilizes noise-driven covariance analysis and Anti-Hebbian principles to selectively prune redundant attention weights, dynamically adjusting the network's behavior to maintain node feature diversity and stability. Our theoretical analysis reveals how DYNAMO-GAT disrupts the convergence to oversmoothed states, while experimental results on benchmark datasets demonstrate its superior performance and efficiency compared to traditional and state-of-the-art methods. DYNAMO-GAT not only advances the theoretical understanding of oversmoothing through the lens of dynamical systems but also provides a practical and effective solution for improving the stability and expressiveness of deep GNNs.
Learning Collective Dynamics of Multi-Agent Systems using Event-based Vision
Nov 11, 2024This paper proposes a novel problem: vision-based perception to learn and predict the collective dynamics of multi-agent systems, specifically focusing on interaction strength and convergence time. Multi-agent systems are defined as collections of more than ten interacting agents that exhibit complex group behaviors. Unlike prior studies that assume knowledge of agent positions, we focus on deep learning models to directly predict collective dynamics from visual data, captured as frames or events. Due to the lack of relevant datasets, we create a simulated dataset using a state-of-the-art flocking simulator, coupled with a vision-to-event conversion framework. We empirically demonstrate the effectiveness of event-based representation over traditional frame-based methods in predicting these collective behaviors. Based on our analysis, we present event-based vision for Multi-Agent dynamic Prediction (evMAP), a deep learning architecture designed for real-time, accurate understanding of interaction strength and collective behavior emergence in multi-agent systems.
Online Relational Inference for Evolving Multi-agent Interacting Systems
Nov 03, 2024



We introduce a novel framework, Online Relational Inference (ORI), designed to efficiently identify hidden interaction graphs in evolving multi-agent interacting systems using streaming data. Unlike traditional offline methods that rely on a fixed training set, ORI employs online backpropagation, updating the model with each new data point, thereby allowing it to adapt to changing environments in real-time. A key innovation is the use of an adjacency matrix as a trainable parameter, optimized through a new adaptive learning rate technique called AdaRelation, which adjusts based on the historical sensitivity of the decoder to changes in the interaction graph. Additionally, a data augmentation method named Trajectory Mirror (TM) is introduced to improve generalization by exposing the model to varied trajectory patterns. Experimental results on both synthetic datasets and real-world data (CMU MoCap for human motion) demonstrate that ORI significantly improves the accuracy and adaptability of relational inference in dynamic settings compared to existing methods. This approach is model-agnostic, enabling seamless integration with various neural relational inference (NRI) architectures, and offers a robust solution for real-time applications in complex, evolving systems.