 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Collective Dynamics of Multi-Agent Systems using Event-based Vision
Nov 11, 2024This paper proposes a novel problem: vision-based perception to learn and predict the collective dynamics of multi-agent systems, specifically focusing on interaction strength and convergence time. Multi-agent systems are defined as collections of more than ten interacting agents that exhibit complex group behaviors. Unlike prior studies that assume knowledge of agent positions, we focus on deep learning models to directly predict collective dynamics from visual data, captured as frames or events. Due to the lack of relevant datasets, we create a simulated dataset using a state-of-the-art flocking simulator, coupled with a vision-to-event conversion framework. We empirically demonstrate the effectiveness of event-based representation over traditional frame-based methods in predicting these collective behaviors. Based on our analysis, we present event-based vision for Multi-Agent dynamic Prediction (evMAP), a deep learning architecture designed for real-time, accurate understanding of interaction strength and collective behavior emergence in multi-agent systems.
Real-time Digital RF Emulation -- II: A Near Memory Custom Accelerator
Jun 13, 2024



A near memory hardware accelerator, based on a novel direct path computational model, for real-time emulation of radio frequency systems is demonstrated. Our evaluation of hardware performance uses both application-specific integrated circuits (ASIC) and field programmable gate arrays (FPGA) methodologies: 1). The ASIC testchip implementation, using TSMC 28nm CMOS, leverages distributed autonomous control to extract concurrency in compute as well as low latency. It achieves a $518$ MHz per channel bandwidth in a prototype $4$-node system. The maximum emulation range supported in this paradigm is $9.5$ km with $0.24$ $\mu$s of per-sample emulation latency. 2). The FPGA-based implementation, evaluated on a Xilinx ZCU104 board, demonstrates a $9$-node test case (two Transmitters, one Receiver, and $6$ passive reflectors) with an emulation range of $1.13$ km to $27.3$ km at $215$ MHz bandwidth.
Real-time Digital RF Emulation -- I: The Direct Path Computational Model
Jun 13, 2024



In this paper we consider the problem of developing a computational model for emulating an RF channel. The motivation for this is that an accurate and scalable emulator has the potential to minimize the need for field testing, which is expensive, slow, and difficult to replicate. Traditionally, emulators are built using a tapped delay line model where long filters modeling the physical interactions of objects are implemented directly. For an emulation scenario consisting of $M$ objects all interacting with one another, the tapped delay line model's computational requirements scale as $O(M^3)$ per sample: there are $O(M^2)$ channels, each with $O(M)$ complexity. In this paper, we develop a new ``direct path" model that, while remaining physically faithful, allows us to carefully factor the emulator operations, resulting in an $O(M^2)$ per sample scaling of the computational requirements. The impact of this is drastic, a $200$ object scenario sees about a $100\times$ reduction in the number of per sample computations. Furthermore, the direct path model gives us a natural way to distribute the computations for an emulation: each object is mapped to a computational node, and these nodes are networked in a fully connected communication graph. Alongside a discussion of the model and the physical phenomena it emulates, we show how to efficiently parameterize antenna responses and scattering profiles within this direct path framework. To verify the model and demonstrate its viability in hardware, we provide several numerical experiments produced using a cycle level C++ simulator of a hardware implementation of the model.
A Sequence Agnostic Multimodal Preprocessing for Clogged Blood Vessel Detection in Alzheimer's Diagnosis
Nov 06, 2022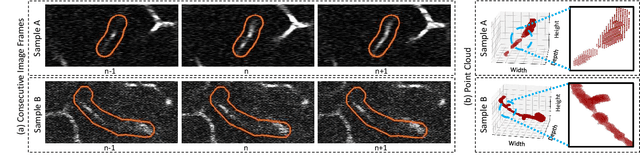
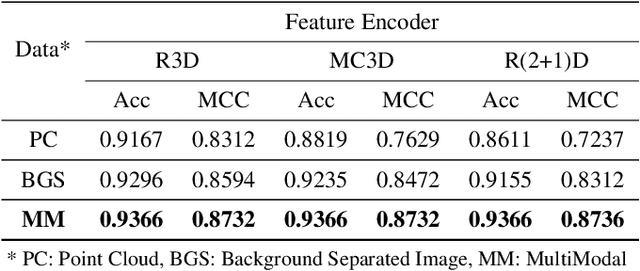

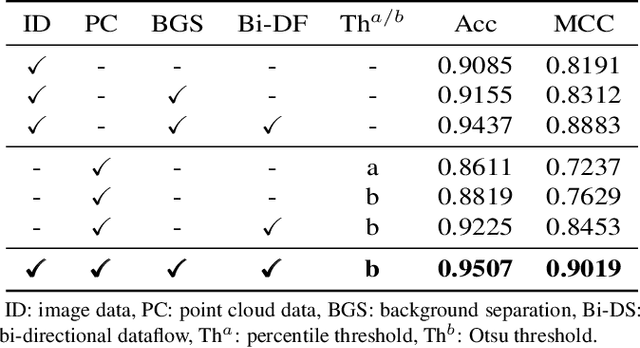
Successful identification of blood vessel blockage is a crucial step for Alzheimer's disease diagnosis. These blocks can be identified from the spatial and time-depth variable Two-Photon Excitation Microscopy (TPEF) images of the brain blood vessels using machine learning methods. In this study, we propose several preprocessing schemes to improve the performance of these methods. Our method includes 3D-point cloud data extraction from image modality and their feature-space fusion to leverage complementary information inherent in different modalities. We also enforce the learned representation to be sequence-order invariant by utilizing bi-direction dataflow. Experimental results on The Clog Loss dataset show that our proposed method consistently outperforms the state-of-the-art preprocessing methods in stalled and non-stalled vessel classification.
Lung-Originated Tumor Segmentation from Computed Tomography Scan (LOTUS) Benchmark
Jan 03, 2022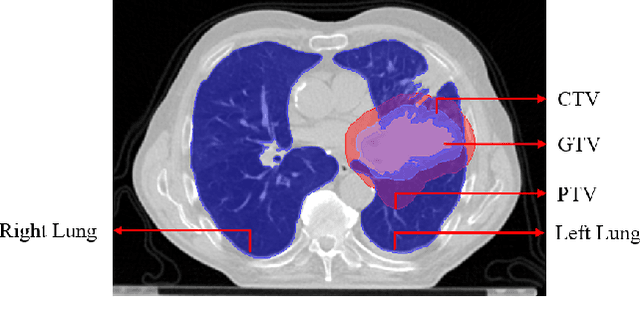
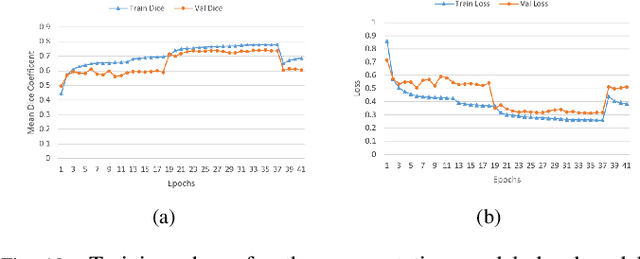
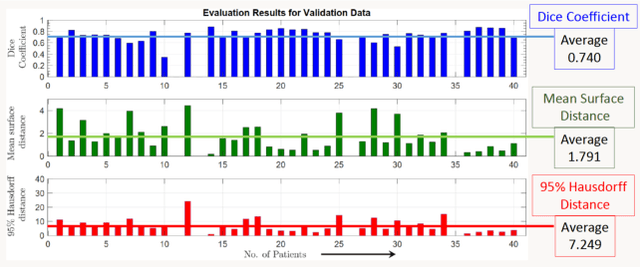
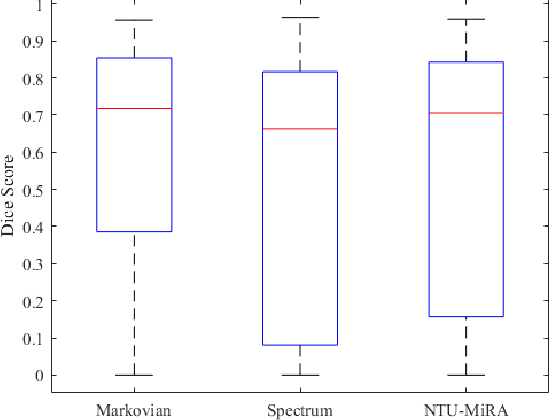
Lung cancer is one of the deadliest cancers, and in part its effective diagnosis and treatment depend on the accurate delineation of the tumor. Human-centered segmentation, which is currently the most common approach, is subject to inter-observer variability, and is also time-consuming, considering the fact that only experts are capable of providing annotations. Automatic and semi-automatic tumor segmentation methods have recently shown promising results. However, as different researchers have validated their algorithms using various datasets and performance metrics, reliably evaluating these methods is still an open challenge. The goal of the Lung-Originated Tumor Segmentation from Computed Tomography Scan (LOTUS) Benchmark created through 2018 IEEE Video and Image Processing (VIP) Cup competition, is to provide a unique dataset and pre-defined metrics, so that different researchers can develop and evaluate their methods in a unified fashion. The 2018 VIP Cup started with a global engagement from 42 countries to access the competition data. At the registration stage, there were 129 members clustered into 28 teams from 10 countries, out of which 9 teams made it to the final stage and 6 teams successfully completed all the required tasks. In a nutshell, all the algorithms proposed during the competition, are based on deep learning models combined with a false positive reduction technique. Methods developed by the three finalists show promising results in tumor segmentation, however, more effort should be put into reducing the false positive rate. This competition manuscript presents an overview of the VIP-Cup challenge, along with the proposed algorithms and results.
Anatomy X-Net: A Semi-Supervised Anatomy Aware Convolutional Neural Network for Thoracic Disease Classification
Jun 10, 2021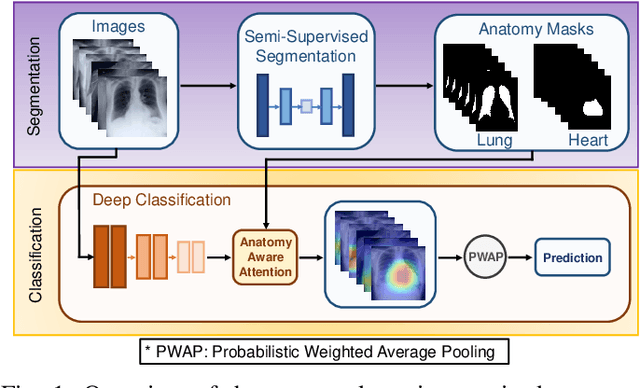
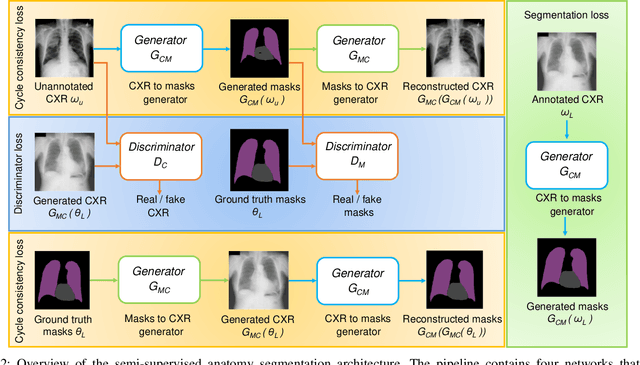
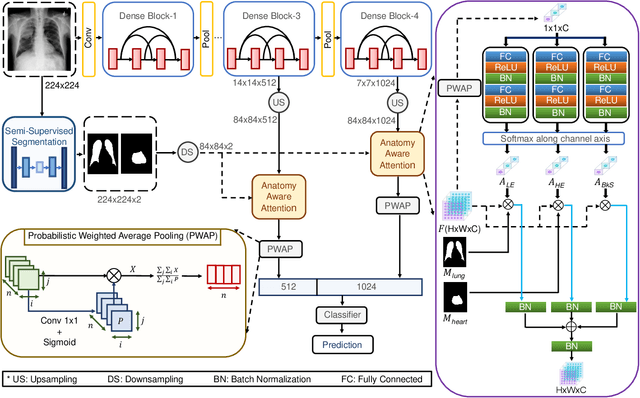
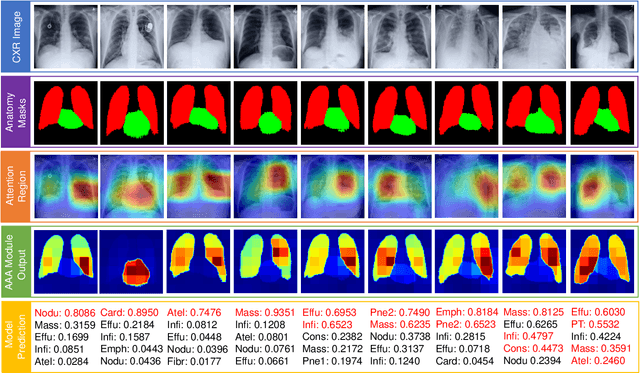
Thoracic disease detection from chest radiographs using deep learning methods has been an active area of research in the last decade. Most previous methods attempt to focus on the diseased organs of the image by identifying spatial regions responsible for significant contributions to the model's prediction. In contrast, expert radiologists first locate the prominent anatomical structures before determining if those regions are anomalous. Therefore, integrating anatomical knowledge within deep learning models could bring substantial improvement in automatic disease classification. This work proposes an anatomy-aware attention-based architecture named Anatomy X-Net, that prioritizes the spatial features guided by the pre-identified anatomy regions. We leverage a semi-supervised learning method using the JSRT dataset containing organ-level annotation to obtain the anatomical segmentation masks (for lungs and heart) for the NIH and CheXpert datasets. The proposed Anatomy X-Net uses the pre-trained DenseNet-121 as the backbone network with two corresponding structured modules, the Anatomy Aware Attention (AAA) and Probabilistic Weighted Average Pooling (PWAP), in a cohesive framework for anatomical attention learning. Our proposed method sets new state-of-the-art performance on the official NIH test set with an AUC score of 0.8439, proving the efficacy of utilizing the anatomy segmentation knowledge to improve the thoracic disease classification. Furthermore, the Anatomy X-Net yields an averaged AUC of 0.9020 on the Stanford CheXpert dataset, improving on existing methods that demonstrate the generalizability of the proposed framework.
DFR-TSD: A Deep Learning Based Framework for Robust Traffic Sign Detection Under Challenging Weather Conditions
Jun 03, 2020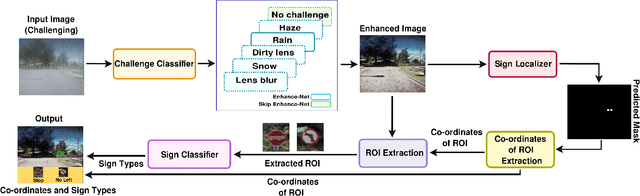
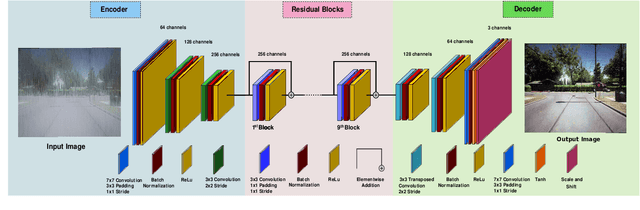

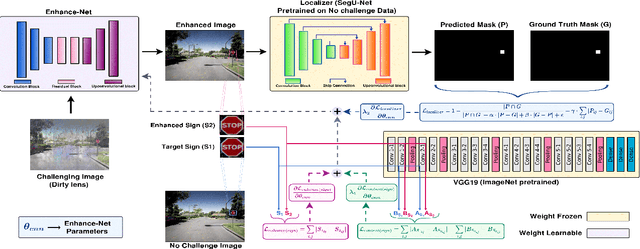
Robust traffic sign detection and recognition (TSDR) is of paramount importance for the successful realization of autonomous vehicle technology. The importance of this task has led to a vast amount of research efforts and many promising methods have been proposed in the existing literature. However, the SOTA (SOTA) methods have been evaluated on clean and challenge-free datasets and overlooked the performance deterioration associated with different challenging conditions (CCs) that obscure the traffic images captured in the wild. In this paper, we look at the TSDR problem under CCs and focus on the performance degradation associated with them. To overcome this, we propose a Convolutional Neural Network (CNN) based TSDR framework with prior enhancement. Our modular approach consists of a CNN-based challenge classifier, Enhance-Net, an encoder-decoder CNN architecture for image enhancement, and two separate CNN architectures for sign-detection and classification. We propose a novel training pipeline for Enhance-Net that focuses on the enhancement of the traffic sign regions (instead of the whole image) in the challenging images subject to their accurate detection. We used CURE-TSD dataset consisting of traffic videos captured under different CCs to evaluate the efficacy of our approach. We experimentally show that our method obtains an overall precision and recall of 91.1% and 70.71% that is 7.58% and 35.90% improvement in precision and recall, respectively, compared to the current benchmark. Furthermore, we compare our approach with SOTA object detection networks, Faster-RCNN and R-FCN, and show that our approach outperforms them by a large margin.