 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLight-weighted CNN-Attention based architecture for Hand Gesture Recognition via ElectroMyography
Oct 27, 2022Advancements in Biological Signal Processing (BSP) and Machine-Learning (ML) models have paved the path for development of novel immersive Human-Machine Interfaces (HMI). In this context, there has been a surge of significant interest in Hand Gesture Recognition (HGR) utilizing Surface-Electromyogram (sEMG) signals. This is due to its unique potential for decoding wearable data to interpret human intent for immersion in Mixed Reality (MR) environments. To achieve the highest possible accuracy, complicated and heavy-weighted Deep Neural Networks (DNNs) are typically developed, which restricts their practical application in low-power and resource-constrained wearable systems. In this work, we propose a light-weighted hybrid architecture (HDCAM) based on Convolutional Neural Network (CNN) and attention mechanism to effectively extract local and global representations of the input. The proposed HDCAM model with 58,441 parameters reached a new state-of-the-art (SOTA) performance with 82.91% and 81.28% accuracy on window sizes of 300 ms and 200 ms for classifying 17 hand gestures. The number of parameters to train the proposed HDCAM architecture is 18.87 times less than its previous SOTA counterpart.
TraHGR: Transformer for Hand Gesture Recognition via ElectroMyography
Mar 31, 2022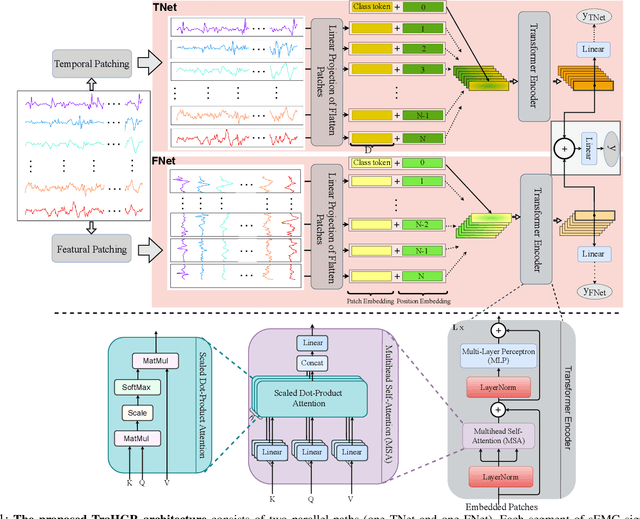
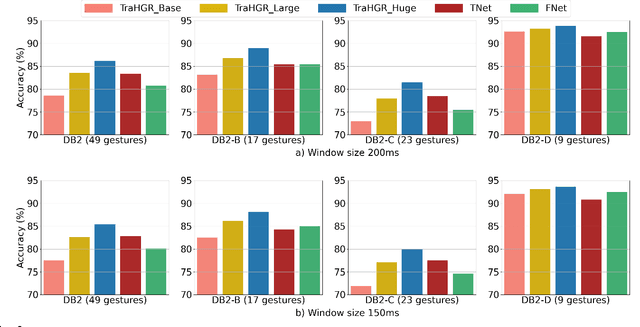
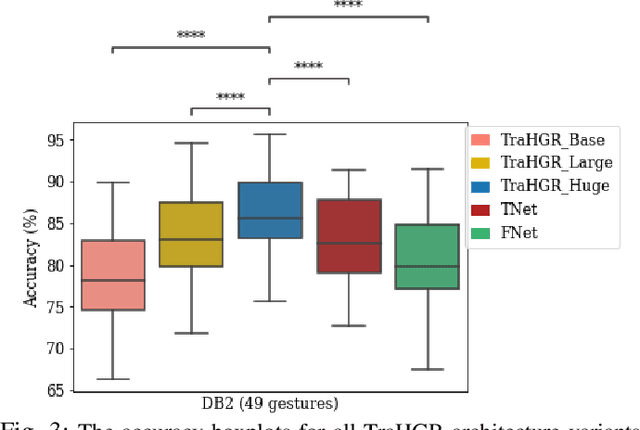
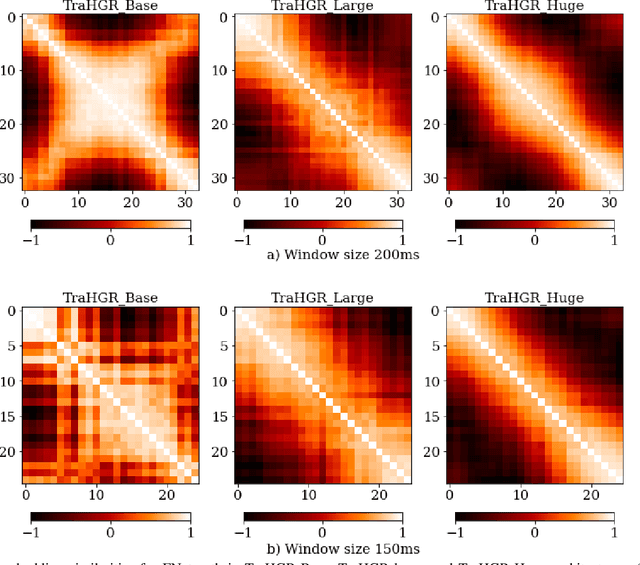
Deep learning-based Hand Gesture Recognition (HGR) via surface Electromyogram (sEMG) signals has recently shown significant potential for development of advanced myoelectric-controlled prosthesis. Existing deep learning approaches, typically, include only one model as such can hardly maintain acceptable generalization performance in changing scenarios. In this paper, we aim to address this challenge by capitalizing on the recent advances of hybrid models and transformers. In other words, we propose a hybrid framework based on the transformer architecture, which is a relatively new and revolutionizing deep learning model. The proposed hybrid architecture, referred to as the Transformer for Hand Gesture Recognition (TraHGR), consists of two parallel paths followed by a linear layer that acts as a fusion center to integrate the advantage of each module and provide robustness over different scenarios. We evaluated the proposed architecture TraHGR based on the commonly used second Ninapro dataset, referred to as the DB2. The sEMG signals in the DB2 dataset are measured in the real-life conditions from 40 healthy users, each performing 49 gestures. We have conducted extensive set of experiments to test and validate the proposed TraHGR architecture, and have compared its achievable accuracy with more than five recently proposed HGR classification algorithms over the same dataset. We have also compared the results of the proposed TraHGR architecture with each individual path and demonstrated the distinguishing power of the proposed hybrid architecture. The recognition accuracies of the proposed TraHGR architecture are 86.18%, 88.91%, 81.44%, and 93.84%, which are 2.48%, 5.12%, 8.82%, and 4.30% higher than the state-ofthe-art performance for DB2 (49 gestures), DB2-B (17 gestures), DB2-C (23 gestures), and DB2-D (9 gestures), respectively.
Lung-Originated Tumor Segmentation from Computed Tomography Scan (LOTUS) Benchmark
Jan 03, 2022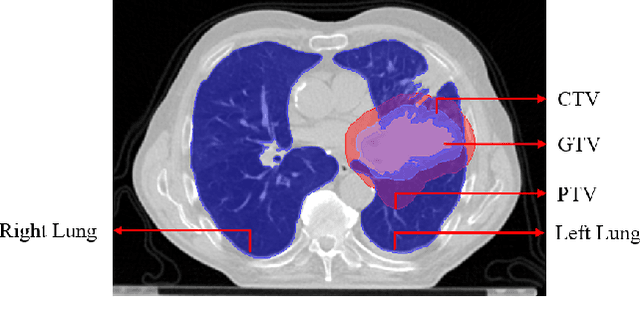
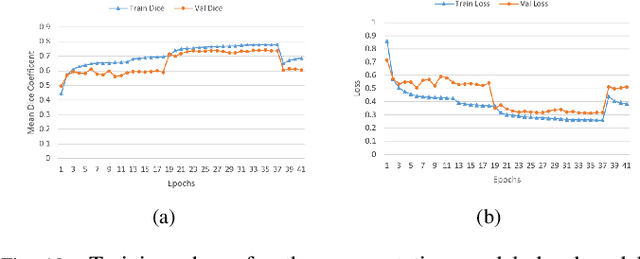
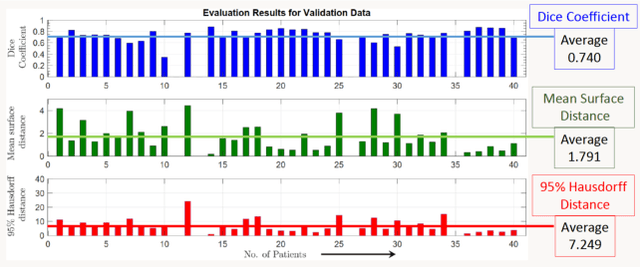
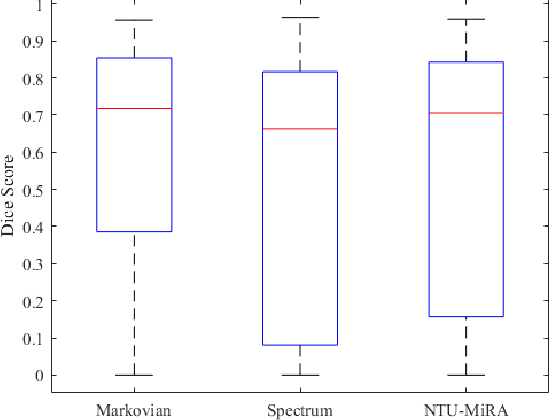
Lung cancer is one of the deadliest cancers, and in part its effective diagnosis and treatment depend on the accurate delineation of the tumor. Human-centered segmentation, which is currently the most common approach, is subject to inter-observer variability, and is also time-consuming, considering the fact that only experts are capable of providing annotations. Automatic and semi-automatic tumor segmentation methods have recently shown promising results. However, as different researchers have validated their algorithms using various datasets and performance metrics, reliably evaluating these methods is still an open challenge. The goal of the Lung-Originated Tumor Segmentation from Computed Tomography Scan (LOTUS) Benchmark created through 2018 IEEE Video and Image Processing (VIP) Cup competition, is to provide a unique dataset and pre-defined metrics, so that different researchers can develop and evaluate their methods in a unified fashion. The 2018 VIP Cup started with a global engagement from 42 countries to access the competition data. At the registration stage, there were 129 members clustered into 28 teams from 10 countries, out of which 9 teams made it to the final stage and 6 teams successfully completed all the required tasks. In a nutshell, all the algorithms proposed during the competition, are based on deep learning models combined with a false positive reduction technique. Methods developed by the three finalists show promising results in tumor segmentation, however, more effort should be put into reducing the false positive rate. This competition manuscript presents an overview of the VIP-Cup challenge, along with the proposed algorithms and results.
DF-SSmVEP: Dual Frequency Aggregated Steady-State Motion Visual Evoked Potential Design with Bifold Canonical Correlation Analysis
Jan 02, 2022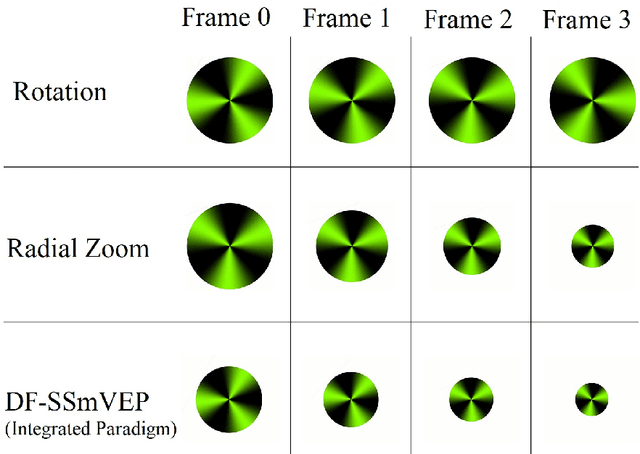
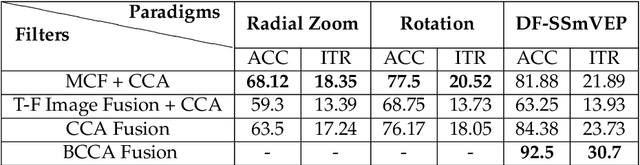
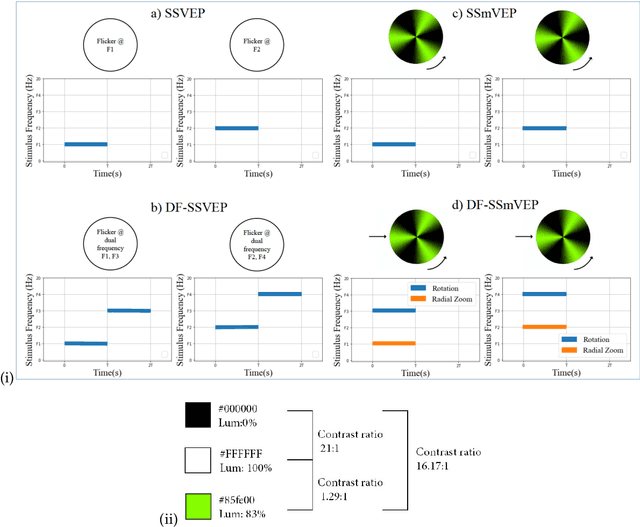
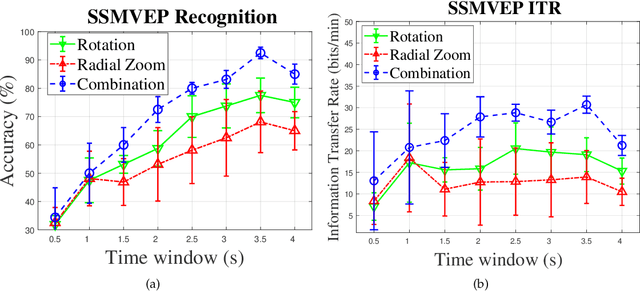
Recent advancements in Electroencephalography (EEG) sensor technologies and signal processing algorithms have paved the way for further evolution of Brain Computer Interfaces (BCI). When it comes to Signal Processing (SP) for BCI, there has been a surge of interest on Steady-State motion-Visual Evoked Potentials (SSmVEP), where motion stimulation is utilized to address key issues associated with conventional light-flashing/flickering. Such benefits, however, come with the price of having less accuracy and less Information Transfer Rate (ITR). In this regard, the paper focuses on the design of a novel SSmVEP paradigm without using resources such as trial time, phase, and/or number of targets to enhance the ITR. The proposed design is based on the intuitively pleasing idea of integrating more than one motion within a single SSmVEP target stimuli, simultaneously. To elicit SSmVEP, we designed a novel and innovative dual frequency aggregated modulation paradigm, referred to as the Dual Frequency Aggregated steady-state motion Visual Evoked Potential (DF-SSmVEP), by concurrently integrating "Radial Zoom" and "Rotation" motions in a single target without increasing the trial length. Compared to conventional SSmVEPs, the proposed DF-SSmVEP framework consists of two motion modes integrated and shown simultaneously each modulated by a specific target frequency. The paper also develops a specific unsupervised classification model, referred to as the Bifold Canonical Correlation Analysis (BCCA), based on two motion frequencies per target. The proposed DF-SSmVEP is evaluated based on a real EEG dataset and the results corroborate its superiority. The proposed DF-SSmVEP outperforms its counterparts and achieved an average ITR of 30.7 +/- 1.97 and an average accuracy of 92.5 +/- 2.04.
BP-Net: Cuff-less, Calibration-free, and Non-invasive Blood Pressure Estimation via a Generic Deep Convolutional Architecture
Dec 31, 2021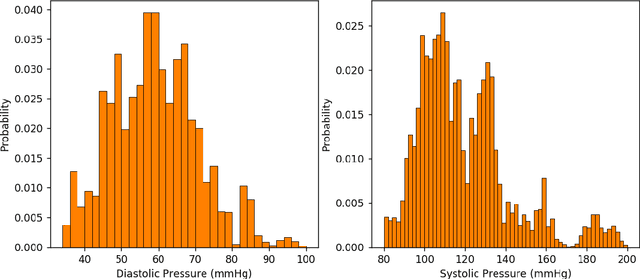
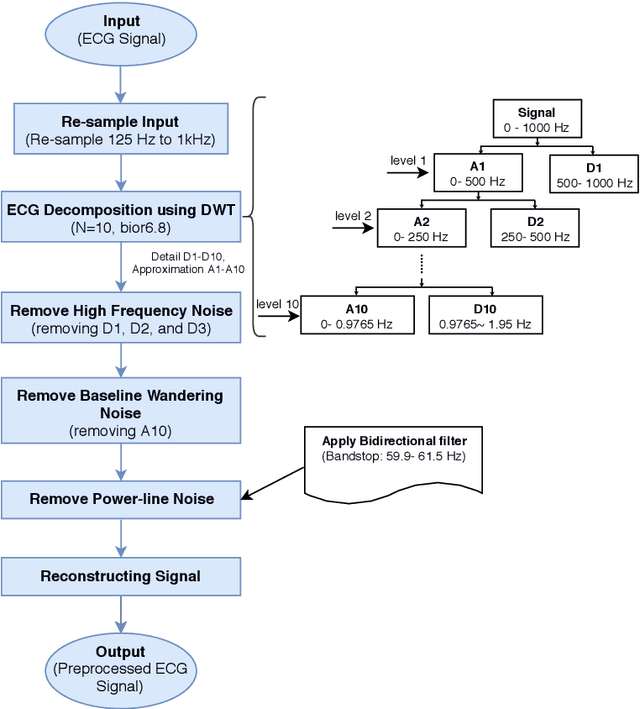
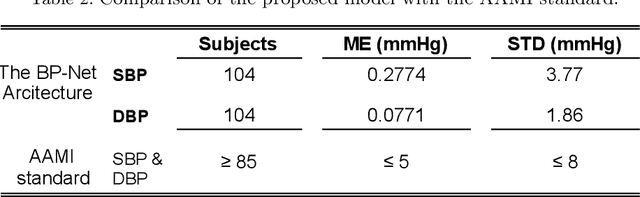
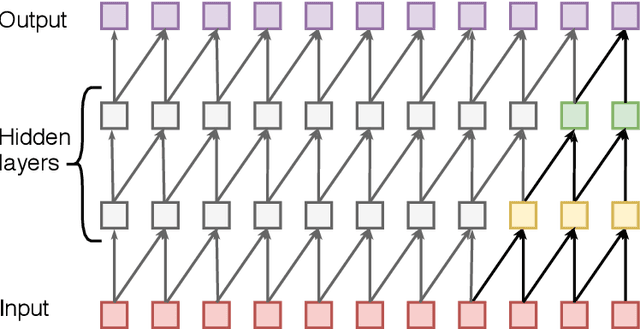
Objective: The paper focuses on development of robust and accurate processing solutions for continuous and cuff-less blood pressure (BP) monitoring. In this regard, a robust deep learning-based framework is proposed for computation of low latency, continuous, and calibration-free upper and lower bounds on the systolic and diastolic BP. Method: Referred to as the BP-Net, the proposed framework is a novel convolutional architecture that provides longer effective memory while achieving superior performance due to incorporation of casual dialated convolutions and residual connections. To utilize the real potential of deep learning in extraction of intrinsic features (deep features) and enhance the long-term robustness, the BP-Net uses raw Electrocardiograph (ECG) and Photoplethysmograph (PPG) signals without extraction of any form of hand-crafted features as it is common in existing solutions. Results: By capitalizing on the fact that datasets used in recent literature are not unified and properly defined, a benchmark dataset is constructed from the MIMIC-I and MIMIC-III databases obtained from PhysioNet. The proposed BP-Net is evaluated based on this benchmark dataset demonstrating promising performance and shows superior generalizable capacity. Conclusion: The proposed BP-Net architecture is more accurate than canonical recurrent networks and enhances the long-term robustness of the BP estimation task. Significance: The proposed BP-Net architecture addresses key drawbacks of existing BP estimation solutions, i.e., relying heavily on extraction of hand-crafted features, such as pulse arrival time (PAT), and; Lack of robustness. Finally, the constructed BP-Net dataset provides a unified base for evaluation and comparison of deep learning-based BP estimation algorithms.
Hand Gesture Recognition Using Temporal Convolutions and Attention Mechanism
Oct 17, 2021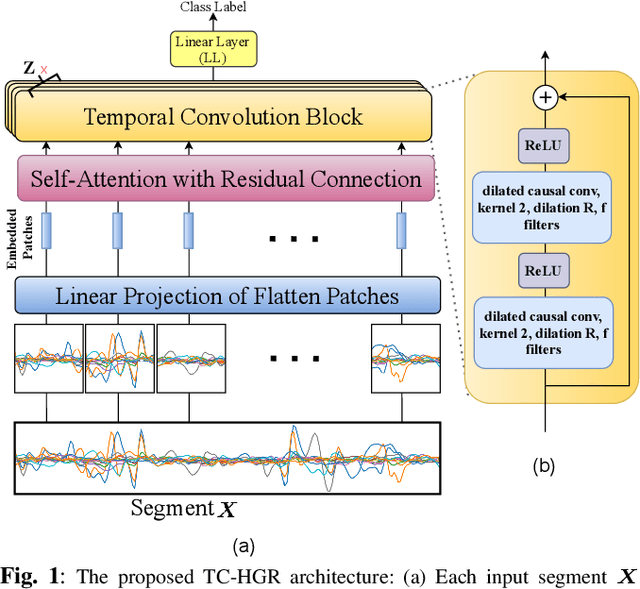
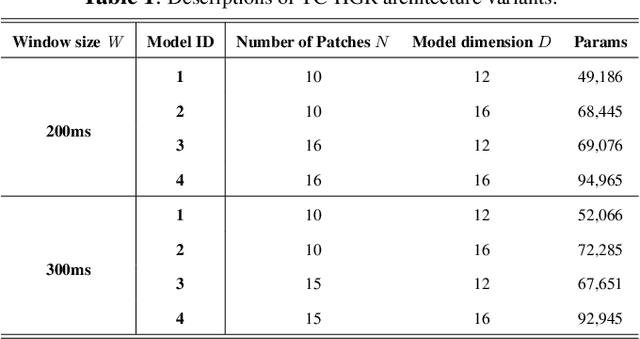
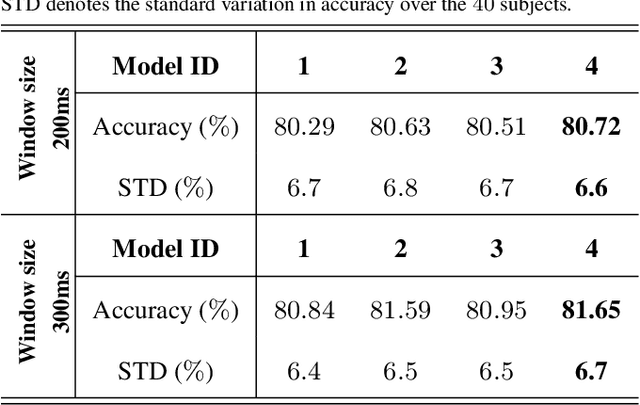
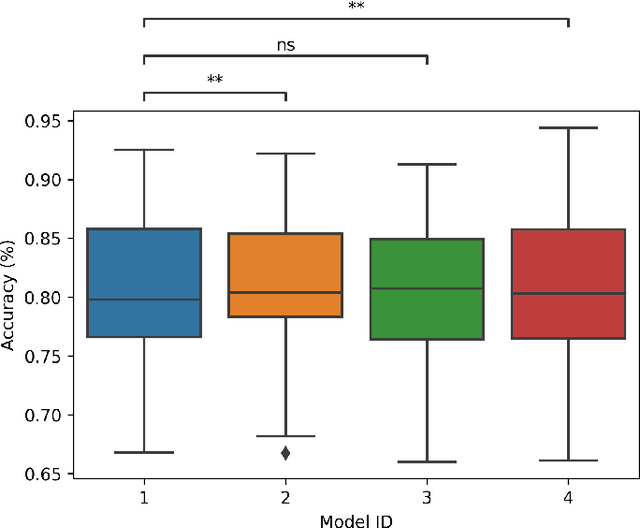
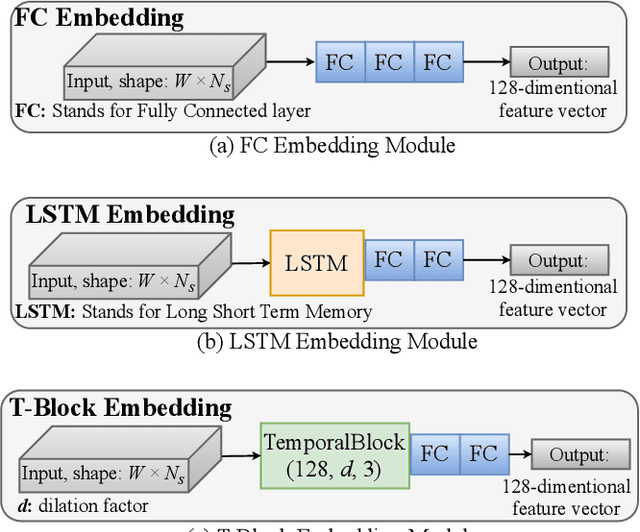
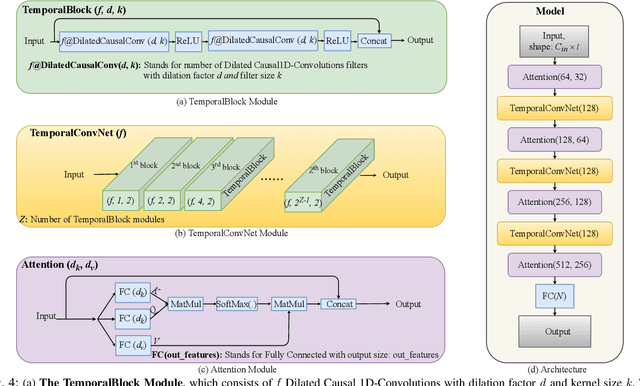
Advances in biosignal signal processing and machine learning, in particular Deep Neural Networks (DNNs), have paved the way for the development of innovative Human-Machine Interfaces for decoding the human intent and controlling artificial limbs. DNN models have shown promising results with respect to other algorithms for decoding muscle electrical activity, especially for recognition of hand gestures. Such data-driven models, however, have been challenged by their need for a large number of trainable parameters and their structural complexity. Here we propose the novel Temporal Convolutions-based Hand Gesture Recognition architecture (TC-HGR) to reduce this computational burden. With this approach, we classified 17 hand gestures via surface Electromyogram (sEMG) signals by the adoption of attention mechanisms and temporal convolutions. The proposed method led to 81.65% and 80.72% classification accuracy for window sizes of 300ms and 200ms, respectively. The number of parameters to train the proposed TC-HGR architecture is 11.9 times less than that of its state-of-the-art counterpart.
Q-Net: A Quantitative Susceptibility Mapping-based Deep Neural Network for Differential Diagnosis of Brain Iron Deposition in Hemochromatosis
Oct 01, 2021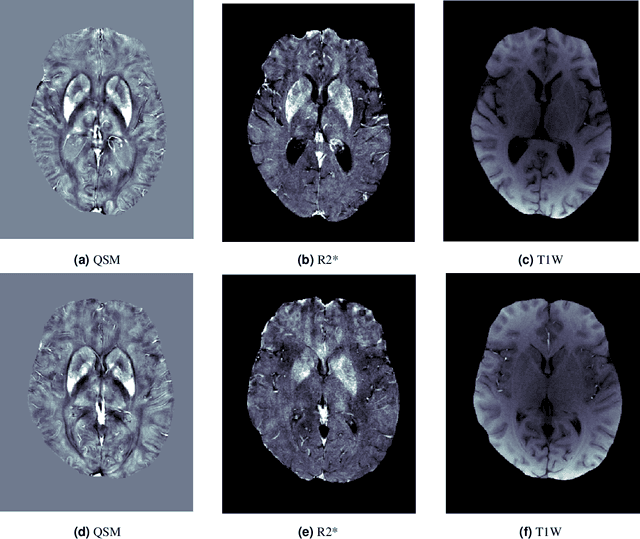

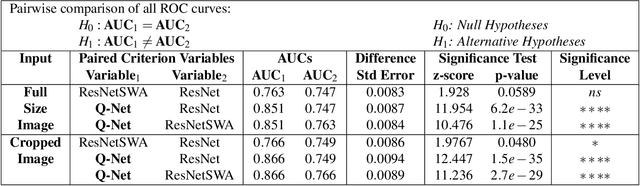
Brain iron deposition, in particular deep gray matter nuclei, increases with advancing age. Hereditary Hemochromatosis (HH) is the most common inherited disorder of systemic iron excess in Europeans and recent studies claimed high brain iron accumulation in patient with Hemochromatosis. In this study, we focus on Artificial Intelligence (AI)-based differential diagnosis of brain iron deposition in HH via Quantitative Susceptibility Mapping (QSM), which is an established Magnetic Resonance Imaging (MRI) technique to study the distribution of iron in the brain. Our main objective is investigating potentials of AI-driven frameworks to accurately and efficiently differentiate individuals with Hemochromatosis from those of the healthy control group. More specifically, we developed the Q-Net framework, which is a data-driven model that processes information on iron deposition in the brain obtained from multi-echo gradient echo imaging data and anatomical information on T1-Weighted images of the brain. We illustrate that the Q-Net framework can assist in differentiating between someone with HH and Healthy control (HC) of the same age, something that is not possible by just visualizing images. The study is performed based on a unique dataset that was collected from 52 subjects with HH and 47 HC. The Q-Net provides a differential diagnosis accuracy of 83.16% and 80.37% in the scan-level and image-level classification, respectively.
TEMGNet: Deep Transformer-based Decoding of Upperlimb sEMG for Hand Gestures Recognition
Sep 25, 2021
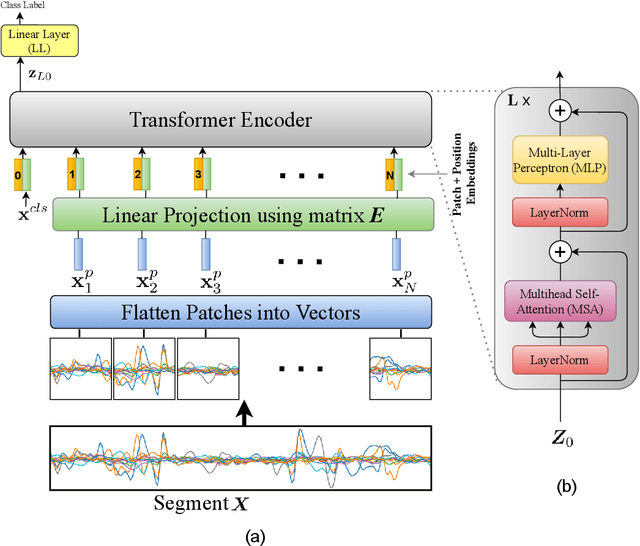
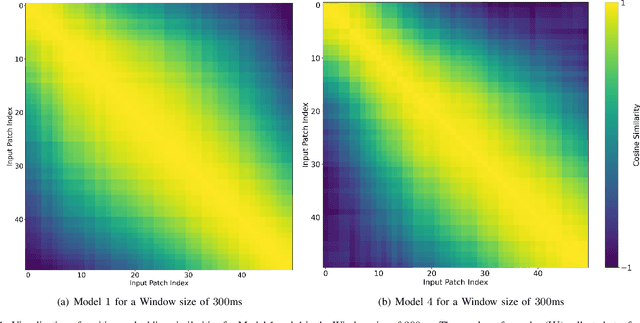
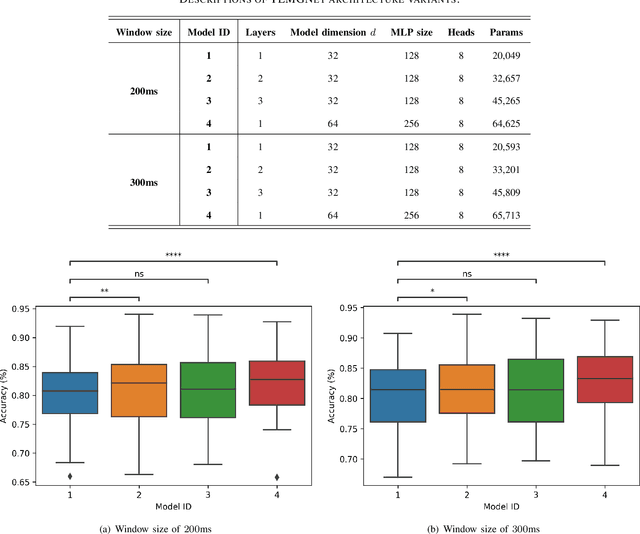
There has been a surge of recent interest in Machine Learning (ML), particularly Deep Neural Network (DNN)-based models, to decode muscle activities from surface Electromyography (sEMG) signals for myoelectric control of neurorobotic systems. DNN-based models, however, require large training sets and, typically, have high structural complexity, i.e., they depend on a large number of trainable parameters. To address these issues, we developed a framework based on the Transformer architecture for processing sEMG signals. We propose a novel Vision Transformer (ViT)-based neural network architecture (referred to as the TEMGNet) to classify and recognize upperlimb hand gestures from sEMG to be used for myocontrol of prostheses. The proposed TEMGNet architecture is trained with a small dataset without the need for pre-training or fine-tuning. To evaluate the efficacy, following the-recent literature, the second subset (exercise B) of the NinaPro DB2 dataset was utilized, where the proposed TEMGNet framework achieved a recognition accuracy of 82.93% and 82.05% for window sizes of 300ms and 200ms, respectively, outperforming its state-of-the-art counterparts. Moreover, the proposed TEMGNet framework is superior in terms of structural capacity while having seven times fewer trainable parameters. These characteristics and the high performance make DNN-based models promising approaches for myoelectric control of neurorobots.
FS-HGR: Few-shot Learning for Hand Gesture Recognition via ElectroMyography
Nov 11, 2020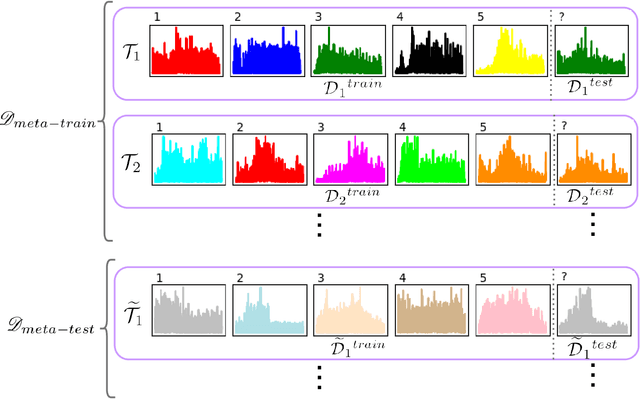
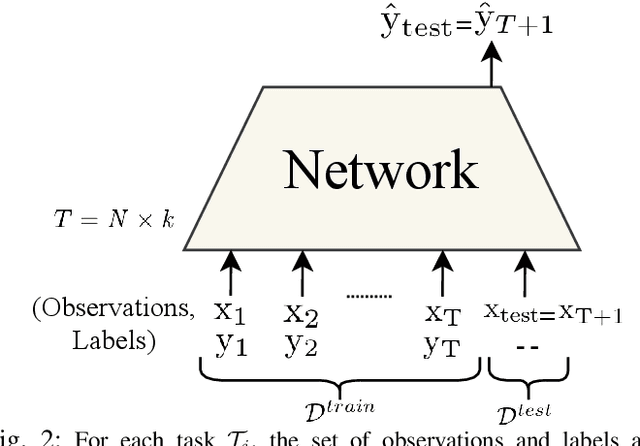
This work is motivated by the recent advances in Deep Neural Networks (DNNs) and their widespread applications in human-machine interfaces. DNNs have been recently used for detecting the intended hand gesture through processing of surface electromyogram (sEMG) signals. The ultimate goal of these approaches is to realize high-performance controllers for prosthetic. However, although DNNs have shown superior accuracy than conventional methods when large amounts of data are available for training, their performance substantially decreases when data are limited. Collecting large datasets for training may be feasible in research laboratories, but it is not a practical approach for real-life applications. Therefore, there is an unmet need for the design of a modern gesture detection technique that relies on minimal training data while providing high accuracy. Here we propose an innovative and novel "Few-Shot Learning" framework based on the formulation of meta-learning, referred to as the FS-HGR, to address this need. Few-shot learning is a variant of domain adaptation with the goal of inferring the required output based on just one or a few training examples. More specifically, the proposed FS-HGR quickly generalizes after seeing very few examples from each class. The proposed approach led to 85.94% classification accuracy on new repetitions with few-shot observation (5-way 5-shot), 81.29% accuracy on new subjects with few-shot observation (5-way 5-shot), and 73.36% accuracy on new gestures with few-shot observation (5-way 5-shot).
Siamese Neural Networks for EEG-based Brain-computer Interfaces
Feb 03, 2020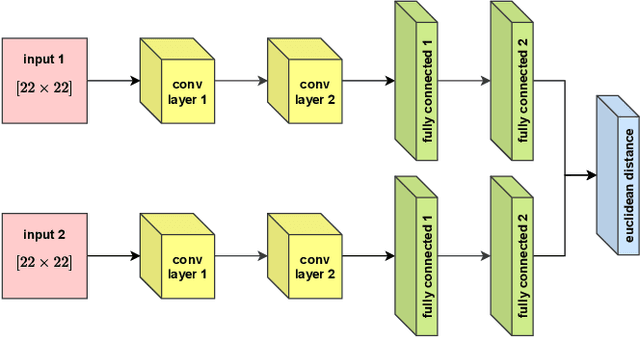

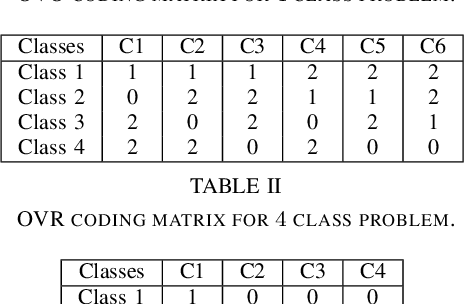
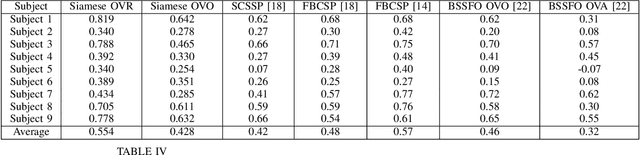
Motivated by the inconceivable capability of the human brain in simultaneously processing multi-modal signals and its real-time feedback to the outer world events, there has been a surge of interest in establishing a communication bridge between the human brain and a computer, which are referred to as Brain-computer Interfaces (BCI). To this aim, monitoring the electrical activity of brain through Electroencephalogram (EEG) has emerged as the prime choice for BCI systems. To discover the underlying and specific features of brain signals for different mental tasks, a considerable number of research works are developed based on statistical and data-driven techniques. However, a major bottleneck in the development of practical and commercial BCI systems is their limited performance when the number of mental tasks for classification is increased. In this work, we propose a new EEG processing and feature extraction paradigm based on Siamese neural networks, which can be conveniently merged and scaled up for multi-class problems. The idea of Siamese networks is to train a double-input neural network based on a contrastive loss-function, which provides the capability of verifying if two input EEG trials are from the same class or not. In this work, a Siamese architecture, which is developed based on Convolutional Neural Networks (CNN) and provides a binary output on the similarity of two inputs, is combined with OVR and OVO techniques to scale up for multi-class problems. The efficacy of this architecture is evaluated on a 4-class Motor Imagery (MI) dataset from BCI Competition IV-2a and the results suggest a promising performance compared to its counterparts.