 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnthroNet: Conditional Generation of Humans via Anthropometrics
Sep 07, 2023We present a novel human body model formulated by an extensive set of anthropocentric measurements, which is capable of generating a wide range of human body shapes and poses. The proposed model enables direct modeling of specific human identities through a deep generative architecture, which can produce humans in any arbitrary pose. It is the first of its kind to have been trained end-to-end using only synthetically generated data, which not only provides highly accurate human mesh representations but also allows for precise anthropometry of the body. Moreover, using a highly diverse animation library, we articulated our synthetic humans' body and hands to maximize the diversity of the learnable priors for model training. Our model was trained on a dataset of $100k$ procedurally-generated posed human meshes and their corresponding anthropometric measurements. Our synthetic data generator can be used to generate millions of unique human identities and poses for non-commercial academic research purposes.
Predicting Fine-Tuning Performance with Probing
Oct 13, 2022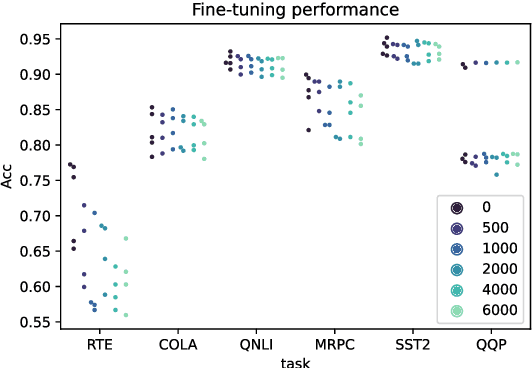


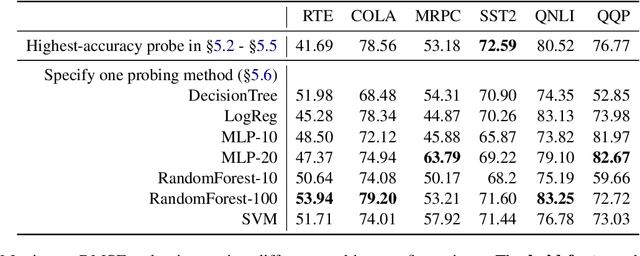
Large NLP models have recently shown impressive performance in language understanding tasks, typically evaluated by their fine-tuned performance. Alternatively, probing has received increasing attention as being a lightweight method for interpreting the intrinsic mechanisms of large NLP models. In probing, post-hoc classifiers are trained on "out-of-domain" datasets that diagnose specific abilities. While probing the language models has led to insightful findings, they appear disjointed from the development of models. This paper explores the utility of probing deep NLP models to extract a proxy signal widely used in model development -- the fine-tuning performance. We find that it is possible to use the accuracies of only three probing tests to predict the fine-tuning performance with errors $40\%$ - $80\%$ smaller than baselines. We further discuss possible avenues where probing can empower the development of deep NLP models.
OOD-Probe: A Neural Interpretation of Out-of-Domain Generalization
Aug 25, 2022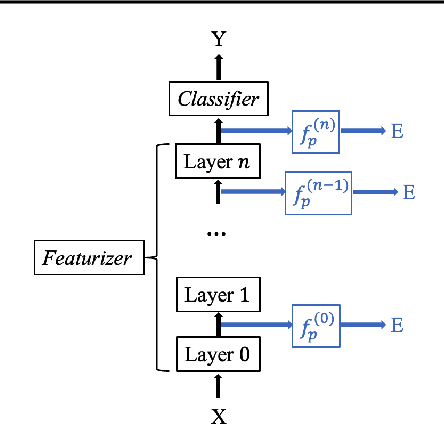
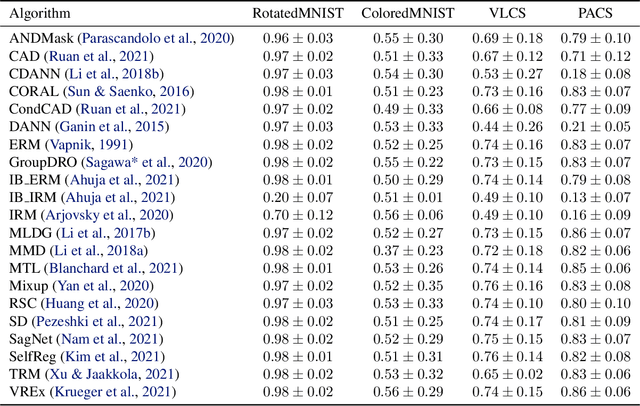

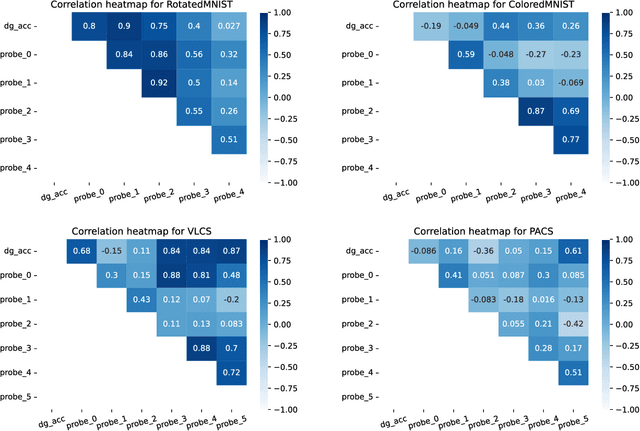
The ability to generalize out-of-domain (OOD) is an important goal for deep neural network development, and researchers have proposed many high-performing OOD generalization methods from various foundations. While many OOD algorithms perform well in various scenarios, these systems are evaluated as ``black-boxes''. Instead, we propose a flexible framework that evaluates OOD systems with finer granularity using a probing module that predicts the originating domain from intermediate representations. We find that representations always encode some information about the domain. While the layerwise encoding patterns remain largely stable across different OOD algorithms, they vary across the datasets. For example, the information about rotation (on RotatedMNIST) is the most visible on the lower layers, while the information about style (on VLCS and PACS) is the most visible on the middle layers. In addition, the high probing results correlate to the domain generalization performances, leading to further directions in developing OOD generalization systems.
SAND-mask: An Enhanced Gradient Masking Strategy for the Discovery of Invariances in Domain Generalization
Jun 04, 2021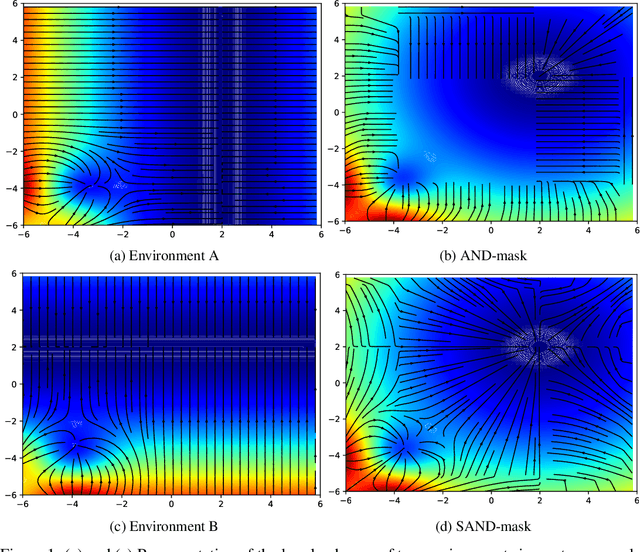
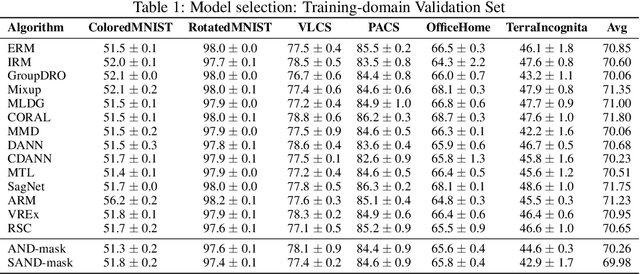
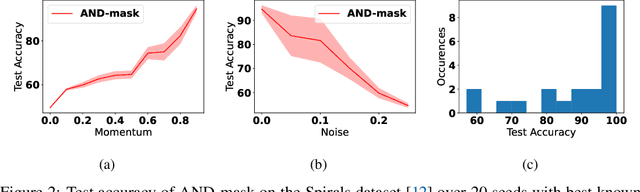
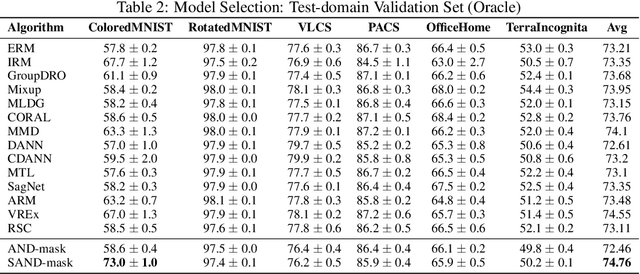
A major bottleneck in the real-world applications of machine learning models is their failure in generalizing to unseen domains whose data distribution is not i.i.d to the training domains. This failure often stems from learning non-generalizable features in the training domains that are spuriously correlated with the label of data. To address this shortcoming, there has been a growing surge of interest in learning good explanations that are hard to vary, which is studied under the notion of Out-of-Distribution (OOD) Generalization. The search for good explanations that are \textit{invariant} across different domains can be seen as finding local (global) minimas in the loss landscape that hold true across all of the training domains. In this paper, we propose a masking strategy, which determines a continuous weight based on the agreement of gradients that flow in each edge of network, in order to control the amount of update received by the edge in each step of optimization. Particularly, our proposed technique referred to as "Smoothed-AND (SAND)-masking", not only validates the agreement in the direction of gradients but also promotes the agreement among their magnitudes to further ensure the discovery of invariances across training domains. SAND-mask is validated over the Domainbed benchmark for domain generalization and significantly improves the state-of-the-art accuracy on the Colored MNIST dataset while providing competitive results on other domain generalization datasets.
Siamese Neural Networks for EEG-based Brain-computer Interfaces
Feb 03, 2020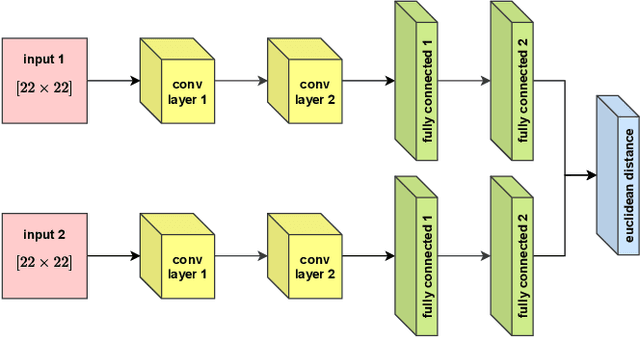

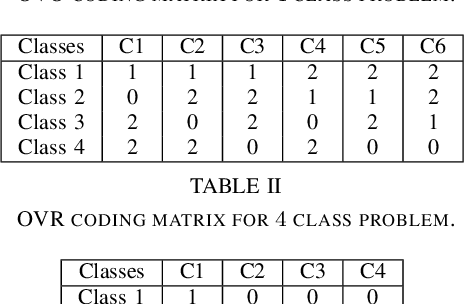
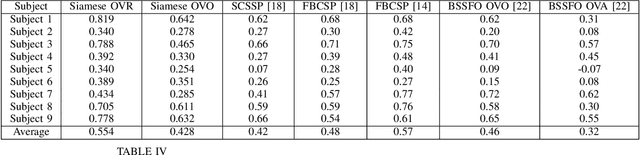
Motivated by the inconceivable capability of the human brain in simultaneously processing multi-modal signals and its real-time feedback to the outer world events, there has been a surge of interest in establishing a communication bridge between the human brain and a computer, which are referred to as Brain-computer Interfaces (BCI). To this aim, monitoring the electrical activity of brain through Electroencephalogram (EEG) has emerged as the prime choice for BCI systems. To discover the underlying and specific features of brain signals for different mental tasks, a considerable number of research works are developed based on statistical and data-driven techniques. However, a major bottleneck in the development of practical and commercial BCI systems is their limited performance when the number of mental tasks for classification is increased. In this work, we propose a new EEG processing and feature extraction paradigm based on Siamese neural networks, which can be conveniently merged and scaled up for multi-class problems. The idea of Siamese networks is to train a double-input neural network based on a contrastive loss-function, which provides the capability of verifying if two input EEG trials are from the same class or not. In this work, a Siamese architecture, which is developed based on Convolutional Neural Networks (CNN) and provides a binary output on the similarity of two inputs, is combined with OVR and OVO techniques to scale up for multi-class problems. The efficacy of this architecture is evaluated on a 4-class Motor Imagery (MI) dataset from BCI Competition IV-2a and the results suggest a promising performance compared to its counterparts.
WAKE: Wavelet Decomposition Coupled with Adaptive Kalman Filtering for Pathological Tremor Extraction
Oct 10, 2018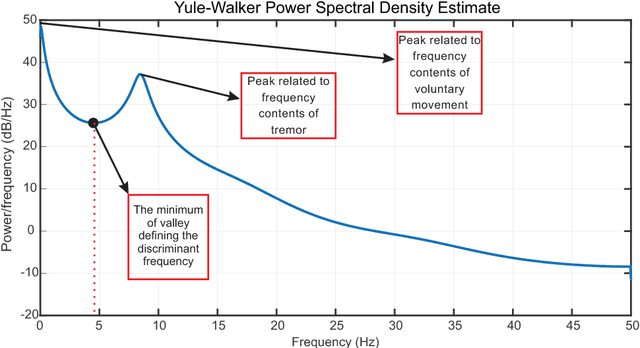
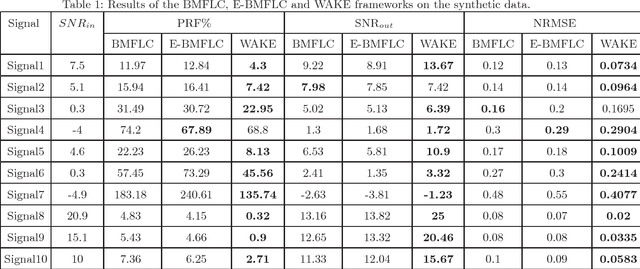

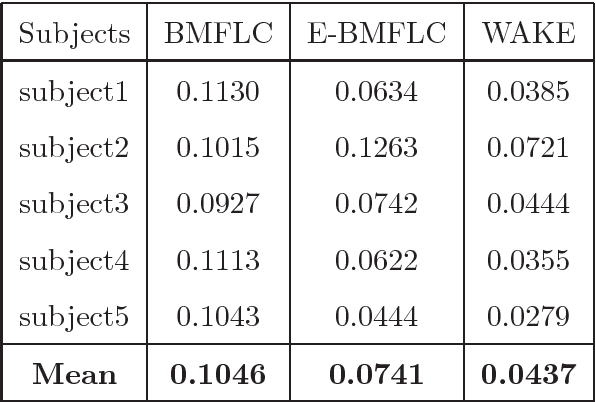
Pathological Hand Tremor (PHT) is among common symptoms of several neurological movement disorders, which can significantly degrade quality of life of affected individuals. Beside pharmaceutical and surgical therapies, mechatronic technologies have been utilized to control PHTs. Most of these technologies function based on estimation, extraction, and characterization of tremor movement signals. Real-time extraction of tremor signal is of paramount importance because of its application in assistive and rehabilitative devices. In this paper, we propose a novel on-line adaptive method which can adjust the hyper-parameters of the filter to the variable characteristics of the tremor. The proposed "WAKE: Wavelet decomposition coupled with Adaptive Kalman filtering technique for pathological tremor Extraction, referred to as the WAKE framework" is composed of a new adaptive Kalman filter and a wavelet transform core to provide indirect prediction of the tremor, one sample ahead of time, to be used for its suppression. In this paper, the design, implementation and evaluation of WAKE are given. The performance is evaluated based on three different datasets, the first one is a synthetic dataset, developed in this work, that simulates hand tremor under ten different conditions. The second and third ones are real datasets recorded from patients with PHTs. The results obtained from the proposed WAKE framework demonstrate significant improvements in the estimation accuracy in comparison with two well regarded techniques in the literature.