 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Fine-Tuning Performance with Probing
Paper and Code
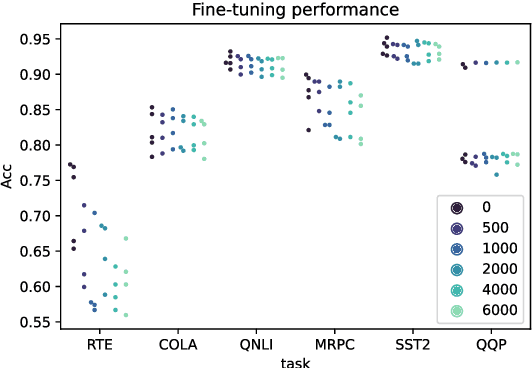


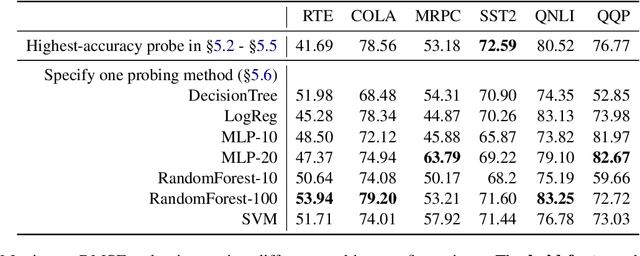
Large NLP models have recently shown impressive performance in language understanding tasks, typically evaluated by their fine-tuned performance. Alternatively, probing has received increasing attention as being a lightweight method for interpreting the intrinsic mechanisms of large NLP models. In probing, post-hoc classifiers are trained on "out-of-domain" datasets that diagnose specific abilities. While probing the language models has led to insightful findings, they appear disjointed from the development of models. This paper explores the utility of probing deep NLP models to extract a proxy signal widely used in model development -- the fine-tuning performance. We find that it is possible to use the accuracies of only three probing tests to predict the fine-tuning performance with errors $40\%$ - $80\%$ smaller than baselines. We further discuss possible avenues where probing can empower the development of deep NLP models.