 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIDP-Bench: Benchmarking ability of LLMs to protect personal information in interdependent privacy contexts
Jun 06, 2026Large language models (LLMs) are becoming widely deployed as personal AI assistants with access to sensitive user data, making privacy a major challenge for their design and evaluation. Prior work focuses mainly on individual-level risks, overlooking \textbf{interdependent privacy (IDP)}--where one person's data may be revealed by others without their knowledge or consent. We address this gap by introducing \textbf{IDP-Bench}: the first LLM benchmark for IDP scenarios, grounded in the Contextual Integrity (CI) framework. We evaluate eight open-source LLMs on their understanding of IDP scenarios across three levels of IDP reasoning using two LLM judges. Results show strong co-ownership recognition (6/8 models exceed 90\%) but persistent weaknesses in identifying CI parameters (information attribute, primary subject) and IDP-specific parameters such as secondary subjects, where 7/8 models score below 74\%. Models also struggle to judge sharing appropriateness (5/8 scoring below 77\%). While the ability to judge the appropriateness of sharing improves with scale, performance tends to decline in smaller models, and prompt sensitivity remains high on IDP-specific questions--highlighting the need for more targeted study of IDP in LLM privacy research. Data \& code available \href{https://github.com/tisl-lab/Interdependent_Privacy_Bench}{here}.
FinRED: A Dataset for Relation Extraction in Financial Domain
Jun 06, 2023
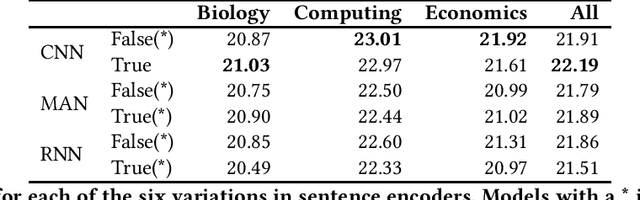

Relation extraction models trained on a source domain cannot be applied on a different target domain due to the mismatch between relation sets. In the current literature, there is no extensive open-source relation extraction dataset specific to the finance domain. In this paper, we release FinRED, a relation extraction dataset curated from financial news and earning call transcripts containing relations from the finance domain. FinRED has been created by mapping Wikidata triplets using distance supervision method. We manually annotate the test data to ensure proper evaluation. We also experiment with various state-of-the-art relation extraction models on this dataset to create the benchmark. We see a significant drop in their performance on FinRED compared to the general relation extraction datasets which tells that we need better models for financial relation extraction.
Financial Numeric Extreme Labelling: A Dataset and Benchmarking for XBRL Tagging
Jun 06, 2023


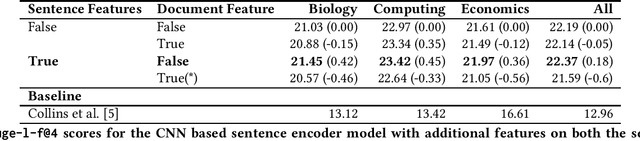
The U.S. Securities and Exchange Commission (SEC) mandates all public companies to file periodic financial statements that should contain numerals annotated with a particular label from a taxonomy. In this paper, we formulate the task of automating the assignment of a label to a particular numeral span in a sentence from an extremely large label set. Towards this task, we release a dataset, Financial Numeric Extreme Labelling (FNXL), annotated with 2,794 labels. We benchmark the performance of the FNXL dataset by formulating the task as (a) a sequence labelling problem and (b) a pipeline with span extraction followed by Extreme Classification. Although the two approaches perform comparably, the pipeline solution provides a slight edge for the least frequent labels.
Realistic Data Augmentation Framework for Enhancing Tabular Reasoning
Oct 23, 2022Existing approaches to constructing training data for Natural Language Inference (NLI) tasks, such as for semi-structured table reasoning, are either via crowdsourcing or fully automatic methods. However, the former is expensive and time-consuming and thus limits scale, and the latter often produces naive examples that may lack complex reasoning. This paper develops a realistic semi-automated framework for data augmentation for tabular inference. Instead of manually generating a hypothesis for each table, our methodology generates hypothesis templates transferable to similar tables. In addition, our framework entails the creation of rational counterfactual tables based on human written logical constraints and premise paraphrasing. For our case study, we use the InfoTabs, which is an entity-centric tabular inference dataset. We observed that our framework could generate human-like tabular inference examples, which could benefit training data augmentation, especially in the scenario with limited supervision.
A Generative Approach for Financial Causality Extraction
Apr 12, 2022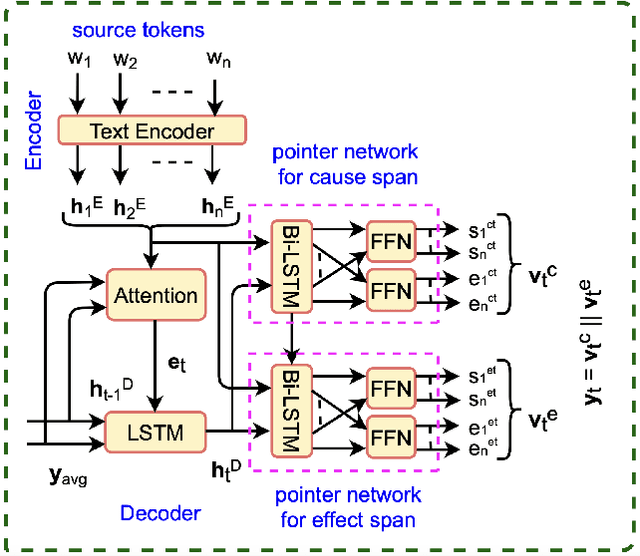
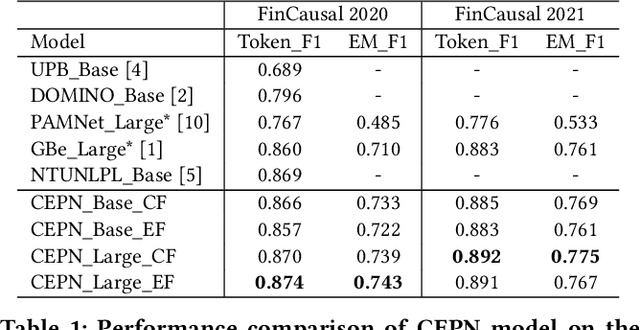
Causality represents the foremost relation between events in financial documents such as financial news articles, financial reports. Each financial causality contains a cause span and an effect span. Previous works proposed sequence labeling approaches to solve this task. But sequence labeling models find it difficult to extract multiple causalities and overlapping causalities from the text segments. In this paper, we explore a generative approach for causality extraction using the encoder-decoder framework and pointer networks. We use a causality dataset from the financial domain, \textit{FinCausal}, for our experiments and our proposed framework achieves very competitive performance on this dataset.
Q-Net: A Quantitative Susceptibility Mapping-based Deep Neural Network for Differential Diagnosis of Brain Iron Deposition in Hemochromatosis
Oct 01, 2021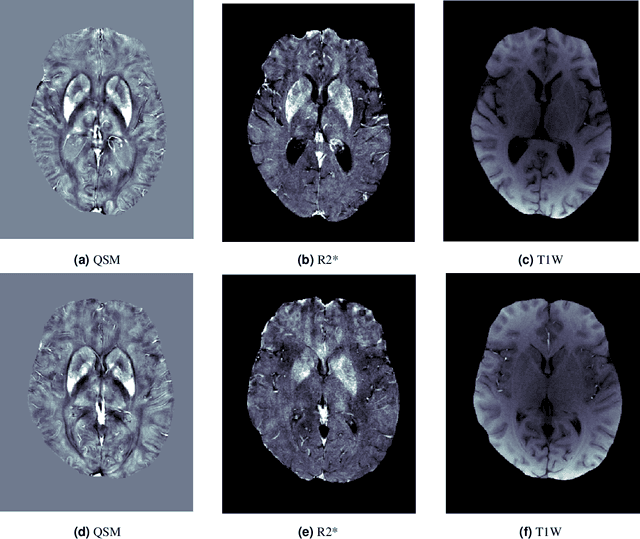

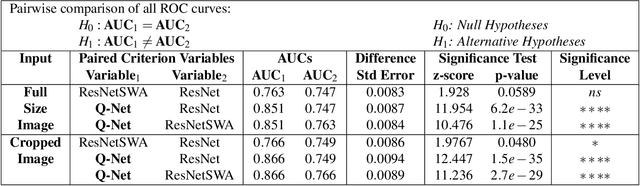
Brain iron deposition, in particular deep gray matter nuclei, increases with advancing age. Hereditary Hemochromatosis (HH) is the most common inherited disorder of systemic iron excess in Europeans and recent studies claimed high brain iron accumulation in patient with Hemochromatosis. In this study, we focus on Artificial Intelligence (AI)-based differential diagnosis of brain iron deposition in HH via Quantitative Susceptibility Mapping (QSM), which is an established Magnetic Resonance Imaging (MRI) technique to study the distribution of iron in the brain. Our main objective is investigating potentials of AI-driven frameworks to accurately and efficiently differentiate individuals with Hemochromatosis from those of the healthy control group. More specifically, we developed the Q-Net framework, which is a data-driven model that processes information on iron deposition in the brain obtained from multi-echo gradient echo imaging data and anatomical information on T1-Weighted images of the brain. We illustrate that the Q-Net framework can assist in differentiating between someone with HH and Healthy control (HC) of the same age, something that is not possible by just visualizing images. The study is performed based on a unique dataset that was collected from 52 subjects with HH and 47 HC. The Q-Net provides a differential diagnosis accuracy of 83.16% and 80.37% in the scan-level and image-level classification, respectively.
Question Answering over Electronic Devices: A New Benchmark Dataset and a Multi-Task Learning based QA Framework
Sep 14, 2021
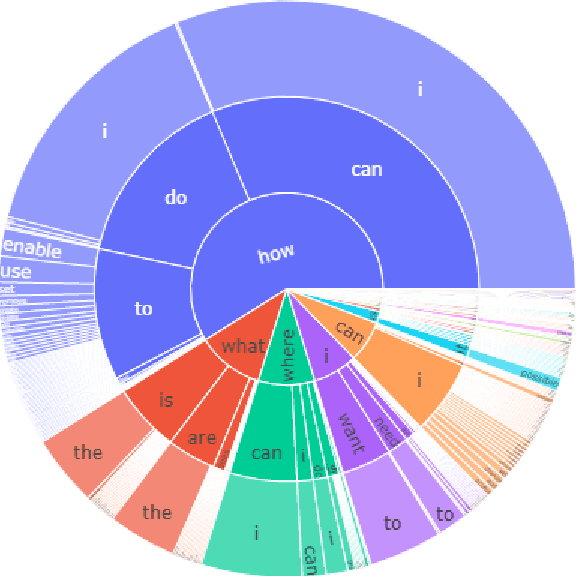
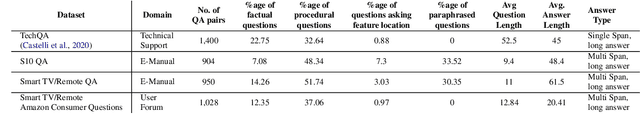
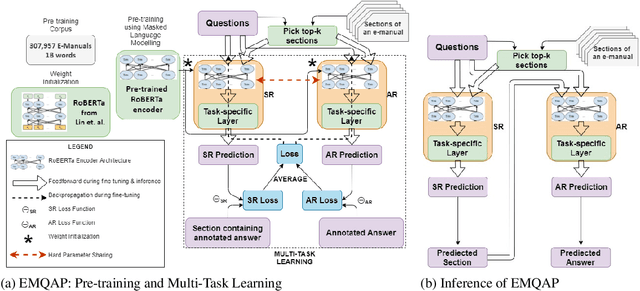
Answering questions asked from instructional corpora such as E-manuals, recipe books, etc., has been far less studied than open-domain factoid context-based question answering. This can be primarily attributed to the absence of standard benchmark datasets. In this paper we meticulously create a large amount of data connected with E-manuals and develop suitable algorithm to exploit it. We collect E-Manual Corpus, a huge corpus of 307,957 E-manuals and pretrain RoBERTa on this large corpus. We create various benchmark QA datasets which include question answer pairs curated by experts based upon two E-manuals, real user questions from Community Question Answering Forum pertaining to E-manuals etc. We introduce EMQAP (E-Manual Question Answering Pipeline) that answers questions pertaining to electronics devices. Built upon the pretrained RoBERTa, it harbors a supervised multi-task learning framework which efficiently performs the dual tasks of identifying the section in the E-manual where the answer can be found and the exact answer span within that section. For E-Manual annotated question-answer pairs, we show an improvement of about 40% in ROUGE-L F1 scores over the most competitive baseline. We perform a detailed ablation study and establish the versatility of EMQAP across different circumstances. The code and datasets are shared at https://github.com/abhi1nandy2/EMNLP-2021-Findings, and the corresponding project website is https://sites.google.com/view/emanualqa/home.
Bayesian Optimization -- Multi-Armed Bandit Problem
Dec 14, 2020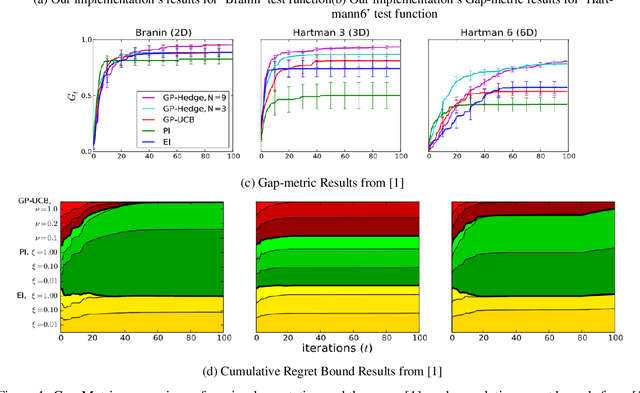
In this report, we survey Bayesian Optimization methods focussed on the Multi-Armed Bandit Problem. We take the help of the paper "Portfolio Allocation for Bayesian Optimization". We report a small literature survey on the acquisition functions and the types of portfolio strategies used in papers discussing Bayesian Optimization. We also replicate the experiments and report our findings and compare them to the results in the paper. Code link: https://colab.research.google.com/drive/1GZ14klEDoe3dcBeZKo5l8qqrKf_GmBDn?usp=sharing#scrollTo=XgIBau3O45_V.
Incorporating Domain Knowledge into Medical NLI using Knowledge Graphs
Aug 31, 2019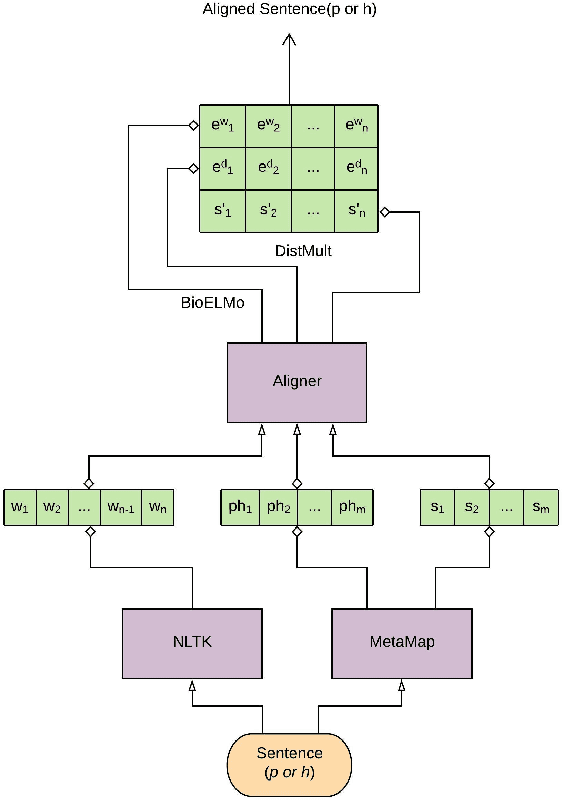
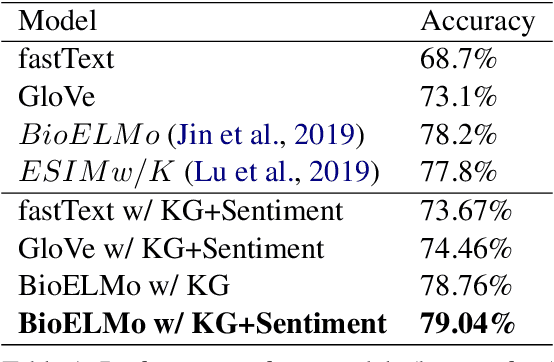
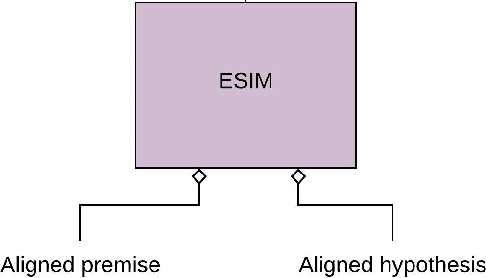
Recently, biomedical version of embeddings obtained from language models such as BioELMo have shown state-of-the-art results for the textual inference task in the medical domain. In this paper, we explore how to incorporate structured domain knowledge, available in the form of a knowledge graph (UMLS), for the Medical NLI task. Specifically, we experiment with fusing embeddings obtained from knowledge graph with the state-of-the-art approaches for NLI task (ESIM model). We also experiment with fusing the domain-specific sentiment information for the task. Experiments conducted on MedNLI dataset clearly show that this strategy improves the baseline BioELMo architecture for the Medical NLI task.