 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinRED: A Dataset for Relation Extraction in Financial Domain
Jun 06, 2023
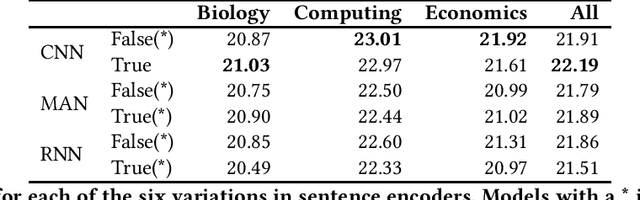
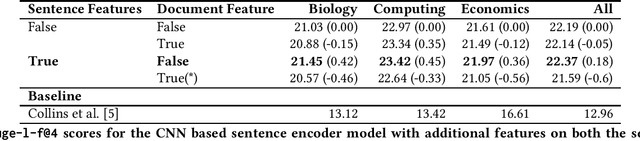

Relation extraction models trained on a source domain cannot be applied on a different target domain due to the mismatch between relation sets. In the current literature, there is no extensive open-source relation extraction dataset specific to the finance domain. In this paper, we release FinRED, a relation extraction dataset curated from financial news and earning call transcripts containing relations from the finance domain. FinRED has been created by mapping Wikidata triplets using distance supervision method. We manually annotate the test data to ensure proper evaluation. We also experiment with various state-of-the-art relation extraction models on this dataset to create the benchmark. We see a significant drop in their performance on FinRED compared to the general relation extraction datasets which tells that we need better models for financial relation extraction.
COV19IR : COVID-19 Domain Literature Information Retrieval
Nov 08, 2022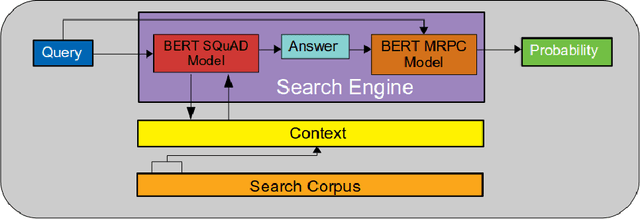
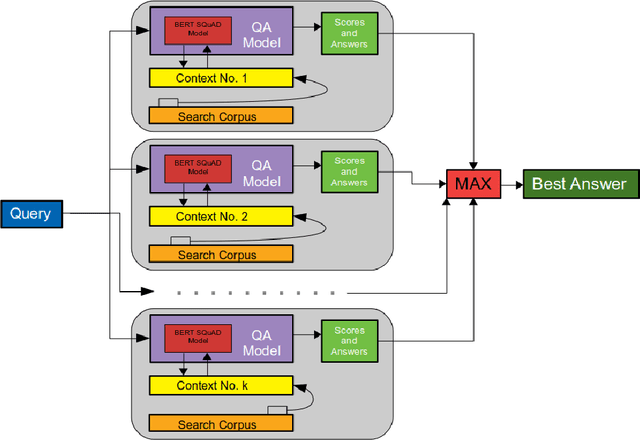
Increasing number of COVID-19 research literatures cause new challenges in effective literature screening and COVID-19 domain knowledge aware Information Retrieval. To tackle the challenges, we demonstrate two tasks along withsolutions, COVID-19 literature retrieval, and question answering. COVID-19 literature retrieval task screens matching COVID-19 literature documents for textual user query, and COVID-19 question answering task predicts proper text fragments from text corpus as the answer of specific COVID-19 related questions. Based on transformer neural network, we provided solutions to implement the tasks on CORD-19 dataset, we display some examples to show the effectiveness of our proposed solutions.