 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatSciRE: Leveraging Pointer Networks to Automate Entity and Relation Extraction for Material Science Knowledge-base Construction
Jan 18, 2024



Material science literature is a rich source of factual information about various categories of entities (like materials and compositions) and various relations between these entities, such as conductivity, voltage, etc. Automatically extracting this information to generate a material science knowledge base is a challenging task. In this paper, we propose MatSciRE (Material Science Relation Extractor), a Pointer Network-based encoder-decoder framework, to jointly extract entities and relations from material science articles as a triplet ($entity1, relation, entity2$). Specifically, we target the battery materials and identify five relations to work on - conductivity, coulombic efficiency, capacity, voltage, and energy. Our proposed approach achieved a much better F1-score (0.771) than a previous attempt using ChemDataExtractor (0.716). The overall graphical framework of MatSciRE is shown in Fig 1. The material information is extracted from material science literature in the form of entity-relation triplets using MatSciRE.
Adapting Pre-trained Generative Models for Extractive Question Answering
Nov 06, 2023Pre-trained Generative models such as BART, T5, etc. have gained prominence as a preferred method for text generation in various natural language processing tasks, including abstractive long-form question answering (QA) and summarization. However, the potential of generative models in extractive QA tasks, where discriminative models are commonly employed, remains largely unexplored. Discriminative models often encounter challenges associated with label sparsity, particularly when only a small portion of the context contains the answer. The challenge is more pronounced for multi-span answers. In this work, we introduce a novel approach that uses the power of pre-trained generative models to address extractive QA tasks by generating indexes corresponding to context tokens or sentences that form part of the answer. Through comprehensive evaluations on multiple extractive QA datasets, including MultiSpanQA, BioASQ, MASHQA, and WikiQA, we demonstrate the superior performance of our proposed approach compared to existing state-of-the-art models.
tagE: Enabling an Embodied Agent to Understand Human Instructions
Oct 24, 2023Natural language serves as the primary mode of communication when an intelligent agent with a physical presence engages with human beings. While a plethora of research focuses on natural language understanding (NLU), encompassing endeavors such as sentiment analysis, intent prediction, question answering, and summarization, the scope of NLU directed at situations necessitating tangible actions by an embodied agent remains limited. The inherent ambiguity and incompleteness inherent in natural language present challenges for intelligent agents striving to decipher human intention. To tackle this predicament head-on, we introduce a novel system known as task and argument grounding for Embodied agents (tagE). At its core, our system employs an inventive neural network model designed to extract a series of tasks from complex task instructions expressed in natural language. Our proposed model adopts an encoder-decoder framework enriched with nested decoding to effectively extract tasks and their corresponding arguments from these intricate instructions. These extracted tasks are then mapped (or grounded) to the robot's established collection of skills, while the arguments find grounding in objects present within the environment. To facilitate the training and evaluation of our system, we have curated a dataset featuring complex instructions. The results of our experiments underscore the prowess of our approach, as it outperforms robust baseline models.
Do the Benefits of Joint Models for Relation Extraction Extend to Document-level Tasks?
Oct 01, 2023



Two distinct approaches have been proposed for relational triple extraction - pipeline and joint. Joint models, which capture interactions across triples, are the more recent development, and have been shown to outperform pipeline models for sentence-level extraction tasks. Document-level extraction is a more challenging setting where interactions across triples can be long-range, and individual triples can also span across sentences. Joint models have not been applied for document-level tasks so far. In this paper, we benchmark state-of-the-art pipeline and joint extraction models on sentence-level as well as document-level datasets. Our experiments show that while joint models outperform pipeline models significantly for sentence-level extraction, their performance drops sharply below that of pipeline models for the document-level dataset.
FinRED: A Dataset for Relation Extraction in Financial Domain
Jun 06, 2023

Relation extraction models trained on a source domain cannot be applied on a different target domain due to the mismatch between relation sets. In the current literature, there is no extensive open-source relation extraction dataset specific to the finance domain. In this paper, we release FinRED, a relation extraction dataset curated from financial news and earning call transcripts containing relations from the finance domain. FinRED has been created by mapping Wikidata triplets using distance supervision method. We manually annotate the test data to ensure proper evaluation. We also experiment with various state-of-the-art relation extraction models on this dataset to create the benchmark. We see a significant drop in their performance on FinRED compared to the general relation extraction datasets which tells that we need better models for financial relation extraction.
A Two-step Approach for Handling Zero-Cardinality in Relation Extraction
Feb 20, 2023



Relation tuple extraction from text is an important task for building knowledge bases. Recently, joint entity and relation extraction models have achieved very high F1 scores in this task. However, the experimental settings used by these models are restrictive and the datasets used in the experiments are not realistic. They do not include sentences with zero tuples (zero-cardinality). In this paper, we evaluate the state-of-the-art joint entity and relation extraction models in a more realistic setting. We include sentences that do not contain any tuples in our experiments. Our experiments show that there is significant drop ($\sim 10-15\%$ in one dataset and $\sim 6-14\%$ in another dataset) in their F1 score in this setting. We also propose a two-step modeling using a simple BERT-based classifier that leads to improvement in the overall performance of these models in this realistic experimental setup.
Exploring Generative Models for Joint Attribute Value Extraction from Product Titles
Aug 15, 2022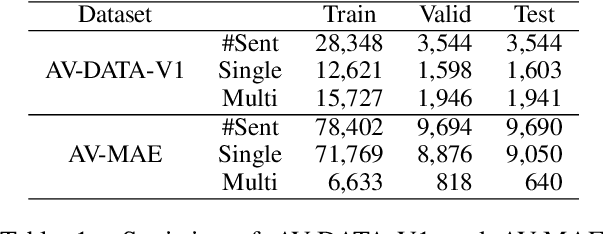
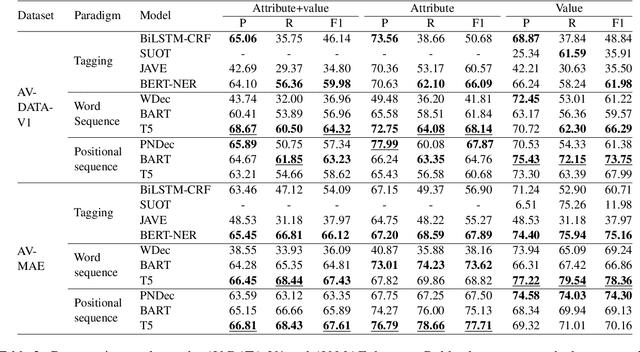
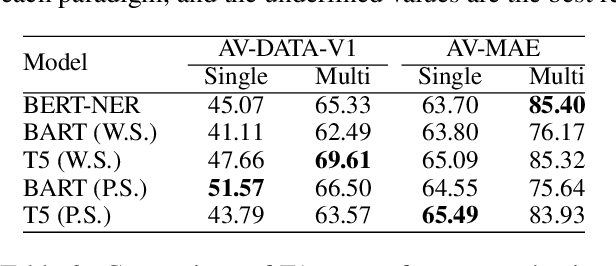

Attribute values of the products are an essential component in any e-commerce platform. Attribute Value Extraction (AVE) deals with extracting the attributes of a product and their values from its title or description. In this paper, we propose to tackle the AVE task using generative frameworks. We present two types of generative paradigms, namely, word sequence-based and positional sequence-based, by formulating the AVE task as a generation problem. We conduct experiments on two datasets where the generative approaches achieve the new state-of-the-art results. This shows that we can use the proposed framework for AVE tasks without additional tagging or task-specific model design.
A Generative Approach for Financial Causality Extraction
Apr 12, 2022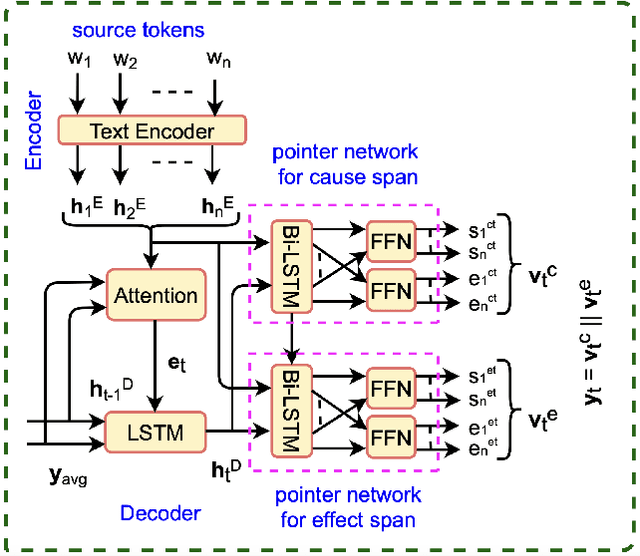
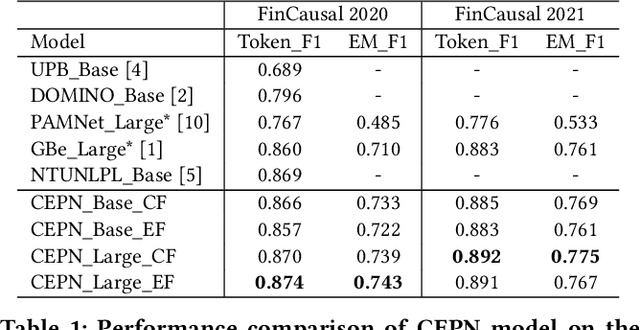
Causality represents the foremost relation between events in financial documents such as financial news articles, financial reports. Each financial causality contains a cause span and an effect span. Previous works proposed sequence labeling approaches to solve this task. But sequence labeling models find it difficult to extract multiple causalities and overlapping causalities from the text segments. In this paper, we explore a generative approach for causality extraction using the encoder-decoder framework and pointer networks. We use a causality dataset from the financial domain, \textit{FinCausal}, for our experiments and our proposed framework achieves very competitive performance on this dataset.
PASTE: A Tagging-Free Decoding Framework Using Pointer Networks for Aspect Sentiment Triplet Extraction
Oct 10, 2021


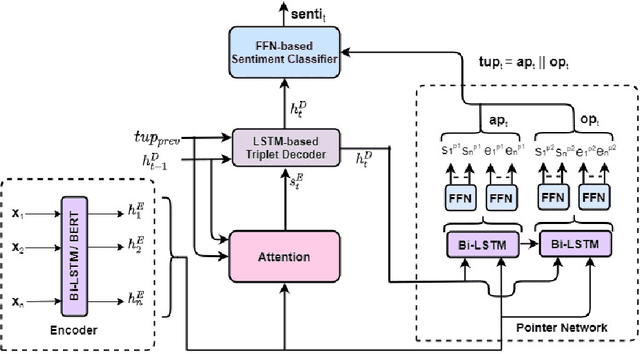
Aspect Sentiment Triplet Extraction (ASTE) deals with extracting opinion triplets, consisting of an opinion target or aspect, its associated sentiment, and the corresponding opinion term/span explaining the rationale behind the sentiment. Existing research efforts are majorly tagging-based. Among the methods taking a sequence tagging approach, some fail to capture the strong interdependence between the three opinion factors, whereas others fall short of identifying triplets with overlapping aspect/opinion spans. A recent grid tagging approach on the other hand fails to capture the span-level semantics while predicting the sentiment between an aspect-opinion pair. Different from these, we present a tagging-free solution for the task, while addressing the limitations of the existing works. We adapt an encoder-decoder architecture with a Pointer Network-based decoding framework that generates an entire opinion triplet at each time step thereby making our solution end-to-end. Interactions between the aspects and opinions are effectively captured by the decoder by considering their entire detected spans while predicting their connecting sentiment. Extensive experiments on several benchmark datasets establish the better efficacy of our proposed approach, especially in the recall, and in predicting multiple and aspect/opinion-overlapped triplets from the same review sentence. We report our results both with and without BERT and also demonstrate the utility of domain-specific BERT post-training for the task.
Improving Distantly Supervised Relation Extraction with Self-Ensemble Noise Filtering
Aug 22, 2021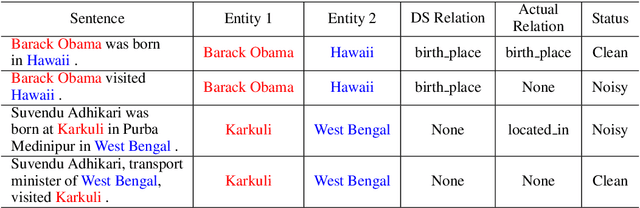
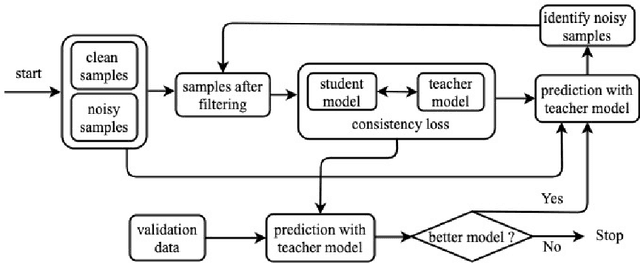
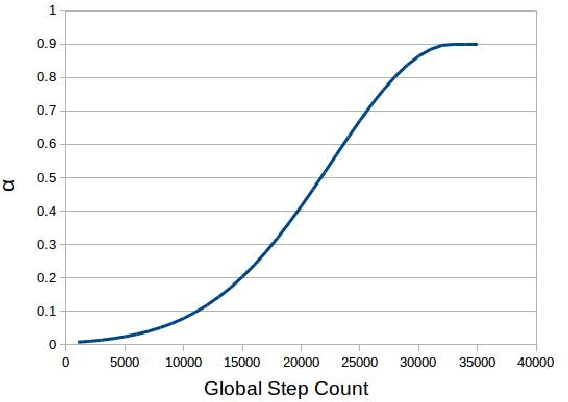

Distantly supervised models are very popular for relation extraction since we can obtain a large amount of training data using the distant supervision method without human annotation. In distant supervision, a sentence is considered as a source of a tuple if the sentence contains both entities of the tuple. However, this condition is too permissive and does not guarantee the presence of relevant relation-specific information in the sentence. As such, distantly supervised training data contains much noise which adversely affects the performance of the models. In this paper, we propose a self-ensemble filtering mechanism to filter out the noisy samples during the training process. We evaluate our proposed framework on the New York Times dataset which is obtained via distant supervision. Our experiments with multiple state-of-the-art neural relation extraction models show that our proposed filtering mechanism improves the robustness of the models and increases their F1 scores.