 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo the Benefits of Joint Models for Relation Extraction Extend to Document-level Tasks?
Oct 01, 2023



Two distinct approaches have been proposed for relational triple extraction - pipeline and joint. Joint models, which capture interactions across triples, are the more recent development, and have been shown to outperform pipeline models for sentence-level extraction tasks. Document-level extraction is a more challenging setting where interactions across triples can be long-range, and individual triples can also span across sentences. Joint models have not been applied for document-level tasks so far. In this paper, we benchmark state-of-the-art pipeline and joint extraction models on sentence-level as well as document-level datasets. Our experiments show that while joint models outperform pipeline models significantly for sentence-level extraction, their performance drops sharply below that of pipeline models for the document-level dataset.
A Two-step Approach for Handling Zero-Cardinality in Relation Extraction
Feb 20, 2023



Relation tuple extraction from text is an important task for building knowledge bases. Recently, joint entity and relation extraction models have achieved very high F1 scores in this task. However, the experimental settings used by these models are restrictive and the datasets used in the experiments are not realistic. They do not include sentences with zero tuples (zero-cardinality). In this paper, we evaluate the state-of-the-art joint entity and relation extraction models in a more realistic setting. We include sentences that do not contain any tuples in our experiments. Our experiments show that there is significant drop ($\sim 10-15\%$ in one dataset and $\sim 6-14\%$ in another dataset) in their F1 score in this setting. We also propose a two-step modeling using a simple BERT-based classifier that leads to improvement in the overall performance of these models in this realistic experimental setup.
Learning Latent Beliefs and Performing Epistemic Reasoning for Efficient and Meaningful Dialog Management
Nov 26, 2018
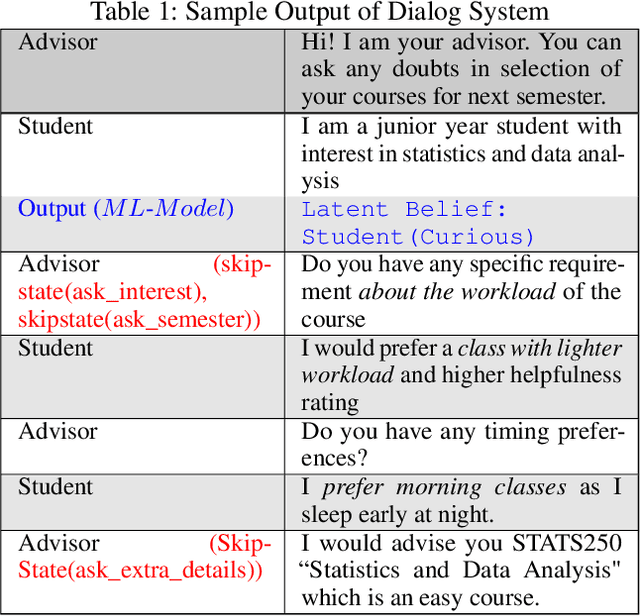
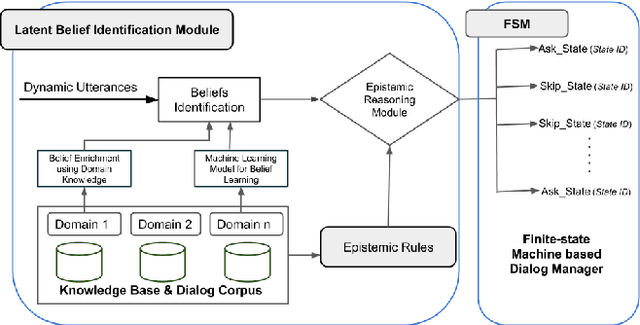

Many dialogue management frameworks allow the system designer to directly define belief rules to implement an efficient dialog policy. Because these rules are directly defined, the components are said to be hand-crafted. As dialogues become more complex, the number of states, transitions, and policy decisions becomes very large. To facilitate the dialog policy design process, we propose an approach to automatically learn belief rules using a supervised machine learning approach. We validate our ideas in Student-Advisor conversation domain, where we extract latent beliefs like student is \textit{curious, confused and neutral}, etc. Further, we also perform epistemic reasoning that helps to tailor the dialog according to student's emotional state and hence improve the overall effectiveness of the dialog system. Our latent belief identification approach shows an accuracy of 87\% and this results in efficient and meaningful dialog management.